Структура микропроцессорной системы
Структура микропроцессорной системы
В широком смысле интерфейс включает также механическую часть (совместимость по типоразъемам) и вспомогательные схемы, обеспечивающие электрическую совместимость устройств по уровням логических сигналов, входным и выходным токам и т. д.
Подробное изучение интерфейсов и системных шин не входит в задачи данного курса. Поэтому эти вопросы мы будем рассматривать лишь с точки зрения общего представления об организации работы микропроцессорной системы и принципах взаимодействия составляющих ее устройств.
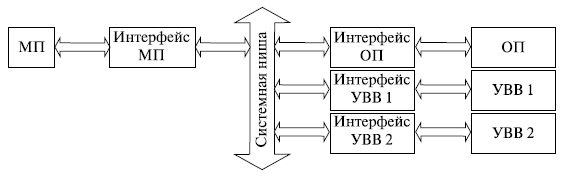
На интерфейсные схемы модулей возлагаются следующие задачи:
Эти интерфейсные схемы могут быть достаточно сложными. Обычно они выполняются в виде специализированных микропроцессорных БИС. Такие схемы принято называть контроллерами.
Контроллеры обладают высокой степенью автономности, что позволяет обеспечить параллельную во времени работу периферийных устройств и выполнение программы обработки данных микропроцессором.
Кроме того, предварительно буферируя данные, контроллеры обеспечивают пересылку сразу для многих слов, расположенных по подряд идущим адресам, что позволяет использование так называемого «взрывного»
Недостатком магистрально-модульного способа организации ЭВМ является невозможность одновременного взаимодействия более двух модулей, что ставит ограничение на производительность компьютера.
Взаимодействие микропроцессора с оперативной памятью (ОП) и внешними устройствами (ВУ) проиллюстрировано на рис. 8.2.
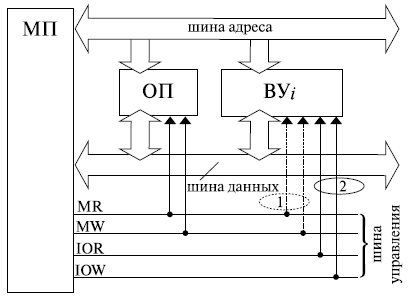
Для обмена информацией с внешними устройствами в МП имеются только 2 команды:
Сигналы IOR/ IOW формируются при выполнении только этих команд.
В связи с этим возможны два основных способа организации адресного пространства микропроцессорной системы:
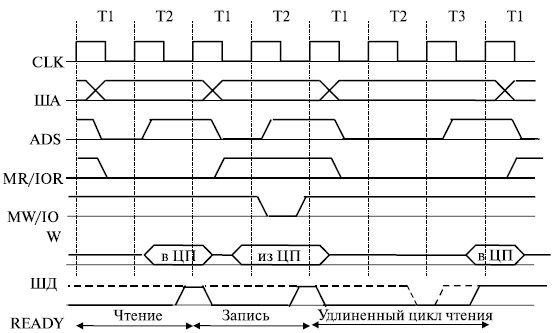
Рассмотрим особенности обмена информацией микропроцессора с внешними устройствами. Упрощенная временная диаграмма этого процесса представлена на рис. 8.3.
Структура микропроцессорной системы

Структура микропроцессорной системы
Микропроцессор всегда работает совместно с системой памяти (микросхемы ОЗУ, ПЗУ, ППЗУ), устройствами ввода-вывода (УВВ) информации (рис. 15). В памяти хранится программа решаемой задачи, исходные, промежуточные и окончательные результаты (данные), УВВ осуществляет ввод и вывод данных.
МП выполняет программу и управляет всеми перечисленными устройствами. Вычислительная система, представленная на рис. 15, называется микропроцессорной системой и реализуется на микропроцессорных БИС. Система построена по модульному принципу и имеет магистральную (шинную) организацию межмодульных связей.
Взаимодействие МП с памятью и УВВ требует выбора способа обращения к устройствам памяти и ввода-вывода, разработки системы адресации и внутреннего интерфейса МП-системы.
По способу организации взаимодействия устройств памяти и УВВ возможны два варианта организации системы:
При разделении адресов все элементы системы адресуются как ячейки памяти в том смысле, что для идентификации УВВ и устройств памяти не генерируется никаких специальных сигналов. Адрес, подаваемый на шину, дешифрируется памятью и системой ввода-вывода с целью определения его назначения, и в таких системах можно не использовать специальных команд ввода-вывода. Все поле адресов распределяется в этом случае между памятью и УВВ. Разделение адресов между памятью и УВВ достигается выделением одной (или нескольких) адресной линии для указания используемого устройства (память или ввод-вывод). Этот способ уменьшает в два (или более) раза емкость адресуемой памяти, поэтому может использоваться лишь в системах с небольшой емкостью памяти.
Использование одной (или более) адресной линии для идентификации устройств можно представить как перевод одной (или более) адресной линии в шину управления.

Рис. 15. Обобщенная структура МПС:
ГТИ – генератор тактовых импульсов; ПЗУ, ППЗУ – перепрограммируемое запоминающее устройство; ЗУ – оперативное запоминающее
устройство; УВВ – устройство ввода-вывода
В небольших МП-системах в дополнение к простоте адресации этот метод обеспечивает преимущества в использовании команд обращения к памяти вместо команд ввода-вывода. По командам ввода в МП-системах осуществляется просто загрузка требуемых данных в аккумулятор микропроцессора. Команды с обращением к памяти имеют более гибкие возможности по обработке данных.
При выделении подсистем вся МП-система разделяется на ряд подсистем (память, ввод, вывод, стек). В рамках каждой подсистемы используется вся совокупность адресов. Разделение всей системы на подсистемы осуществляется с помощью управляющих сигналов, которые появляются на специальных выводах микропроцессора. Обычно эти сигналы поддерживаются на выводах МП или шине данных в течение ограниченного интервала времени (в течение такта, например). Если необходимо запомнить и хранить слово состояния или управляющие сигналы более длительное время, в состав МП-системы вводят специальный регистр – регистр состояния системы.
В архитектуре магистрального типа важное значение приобретает интерфейс. На рис. 15 показаны интерфейсы МП, системы памяти и системы ввода-вывода (ВВ). В узком смысле интерфейсом (от англ. Interfase – сопрягать, согласовать) называют устройство сопряжения; в широком смысле под интерфейсом понимают совокупность аппаратных, программных и конструктивных средств, обеспечивающих взаимодействие функциональных модулей системы.
Таким образом, для представленной на рис.15 микропроцессорной системы необходимым условием высокой эффективности использования является совместимость интерфейсов МП, системы памяти и системы ввода-вывода (ВВ). Работа рассматриваемой системы синхронизируется генератором тактовых импульсов (ГТИ).
Система работает с командами пересылки информации: МП – память, МП – УВВ, память – УВВ.
Для МП-системы разработано три основных режима ввода-вывода:
· ввод-вывод по прерываниям,
· режим прямого доступа к памяти (ПДП).
2.6.1. Программный ввод-вывод
Программный ввод-вывод – это наиболее простой способ обмена данными между процессором и внешним устройством. В этом случае всеми действиями по организации обмена управляет процессор, а всем другим элементам системы отводится пассивная роль сигнализации о своей готовности (асинхронный способ обмена). Непроизводительные потери времени МП на ожидание сигнала готовности от УВВ могут оказаться неприемлемыми для систем, работающих в реальном времени.
Известны два типа программно-управляемой передачи данных: синхронная, асинхронная.
Синхронная передача данных характерна для периферийных устройств, для которых известны временные соотношения. При этом типе передачи устройство ввода-вывода должно быть готово к приему или передаче данных за время, равное времени выполнения определенной команды процессора. Синхронная передача реализуется при минимальных затратах технических и программных средств.
Асинхронная передача данных, иногда называемая обменом посредством “рукопожатия”, широко используется в микроЭВМ. При такой передаче данных ЭВМ перед выполнением операции ввода-вывода проверяет состояние периферийного устройства. Блок-схема алгоритма асинхронного программного обмена (фрагмента некоторой программы) приведена на рис. 16.
Обычно при обмене необходимо:
· проверить состояние устройства (чтение регистра состояния ( PC ));
· активизировать устройство, если последнее готово к обмену;
· передать данные (чтение регистра данных (РД), запись РД);
Асинхронная передача является идеальной в смысле согласования временных различий между периферийными устройствами и процессором. Недостаток ее в том, что процессор вынужден ожидать, пока периферийное устройство не будет готово к обмену. Это приводит не только к непроизводительным затратам времени МП (при наличии длительных задержек), но и во многих случаях является просто недопустимым. Например, в процессах управления в этом случае возникает необходимость сохранения уровня сигналов управления на время ожидания передачи. Методом, позволяющим устранить подобные трудности, является передача данных с прерыванием программы.

Рис. 16. Блок-схема алгоритма асинхронного программного обмена
2.6.2. Ввод-вывод по прерываниям
Ввод-вывод по прерываниям подразумевает, что действия по обмену информацией инициируют сами периферийные устройства, генерируя сигнал прерывания. При восприятии сигнала прерывания микропроцессор приостанавливает выполнение текущей программы, временно запоминает ее состояние (как минимум, запоминается содержание PSW, РС) идентифицирует прерывающее устройство и осуществляет обмен информацией. После завершения обмена восстанавливается состояние прерванной программы и возобновляется ее выполнение (рис. 17). В данном режиме на ввод-вывод расходуется гораздо меньше времени микропроцессора, чем в программно-управляемом ВВ, поэтому система может выполнить больше полезной работы или обслужить больше периферийных устройств.


| |


| |

| |



Рис. 17. Обслуживание прерывания в МП-системе
Для повышения производительности системы необходимо освободить процессор от опроса готовности ВУ к обмену. Эту функцию берет на себя контроллер прерываний ВУ. Получив команду ввода-вывода, контроллер передает ее ВУ и следит за временем ее выполнения. По окончании действий в ВУ (печати, перфорации и т. п.) контроллер посылает в процессор сигнал требования прерывания, получает очередную команду ввода-вывода, и действия повторяются. Процессор в этом случае, передав в контроллер очередную команду ввода-вывода, может выполнять другие операции основной программы до получения сигнала требования прерывания. Получив его, он обслуживает это прерывание, то есть формирует и выдает в контроллер очередную команду ввода-вывода, а затем возвращается к выполнению прерванной основной программы.


Ввод-вывод по прерываниям, однако, требует усложнения аппаратных средств – создания системы прерываний.
Структура таблицы векторов прерываний для ип от Intel имеет вид


Пошаговый режим выполнения программы
Запрос по входу NMI
Запрос по входу IRQ0 (системный таймер)
Запрос по входу IRQ1 (контроллер клавиатуры)
Отсутствие сегмента в оперативной памяти
Один контроллер прерываний имеет 8 входов ( IRQ ), чего явно недостаточно для обслуживания внешних устройств современного компьютера (таймер, часы реального времени, клавиатура, гибкий и жесткий диски, мышь, последовательные и параллельные порты и проч.).
Однако несколько контроллеров прерываний могут быть включены последовательно. На современных компьютерах (начиная с 286) один (ведущий) контроллер прерываний подключен непосредственно к процессору, а второй (ведомый) своим выходом INT подключен ко входу IRQ 2 ведущего контроллера. Итого получается 15 входов прерываний от IRQ 0 до IRQ 15 ( IRQ 2 не может быть использован).
Структура контроллера приоритетных прерываний имеет вид


Пример каскадного включения двух контроллеров прямого доступа к памяти


2.6.3. Ввод-вывод в режиме прямого доступа к памяти
Два рассмотренных выше способа обмена – программный и по прерываниям – имеют малую скорость обмена данными. Для передачи одного слова данных процессор должен выполнить несколько команд, среди них вспомогательные – изменение адреса памяти, изменение и анализ содержимого счетчика слов. В некоторых микропроцессорах (МП с архитектурой x 86) невозможно в одной команде передать данные из ВУ в память. Сначала необходимо их принять в процессор, а затем из процессора передать в память. Однако во многих случаях требуется передавать большие массивы информации между памятью и внешним устройством (например, накопители на магнитных дисках). В этом случае процессор выступает в роли “лишнего звена”, транзитом пропуская через себя информацию.
В то же время память ПЭВМ обычно позволяет выполнять чтение-запись данных со скоростью нескольких Мбайт в секунду. Нередко и ВУ позволяют вводить или выводить данные с такими скоростями. Очевидно, что процессор, участвуя в таком обмене, становится “узким местом”, снижает возможные скорости обмена. Связь с такими устройствами удобно реализовать в режиме прямого доступа к памяти (ПДП, DMA – Direct Memory Access ). В этом режиме на время передачи действия МП приостанавливаются, и он отключается от шины адреса и данных. Инициирование и управление обменом информации между периферийными устройствами и системой памяти осуществляется контроллером прямого доступа к памяти (КПДП). Контроллер ПДП позволяет быстродействующим периферийным устройствам обращаться к ОЗУ непосредственно. Межмодульный обмен осуществляется с помощью магистрали в режиме ПДП. Во время цикла обмена МП приостанавливает работу (находится в режиме ожидания), это несколько снижает его производительность.
Условием возможности реализации режима ПДП является способность МП отключаться от своих внешних шин, то есть переводить буферные регистры данных и адреса по выходу в высокое импедансное состояние.
Типовой микропроцессор имеет возможность работать в каждом из вышеописанных режимов обмена. Структура интерфейса МП-системы для каждого из режимов приведена на рис. 18.

Рис. 18. Структура интерфейса МП-системы:
а) программно-управляемый ВВ, ввод-вывод по прерываниям (ИВВ – интерфейс ввода-вывода, ОШ – общая шина); б) режим ПДП (КПДП –
контроллер прямого доступа к памяти)
Функции контроллера интерфейса чаще всего выполняет сам МП.


Рис. ХХХ. Подробная схема реализации ПДП
Метод ПДП позволяет периферийным устройствам обмениваться данными с памятью минуя процессор, который в это время может обрабатывать команды, которые в него уже загружены, до тех пор, пока не потребуется выполнить обмен данными с ОЗУ. Существуют усовершенствованные методы ПДП (Enhanced DMA), которые позволяют выполнять блочные передачи в скоростном режиме.
Процессом ПДП на шине управления системы руководит специальный контроллер. Контроллер программируется на различные режимы работы и скорости обмена данными. Контроллер способен захватить управление шиной данных, заблокировав на это время шину данных процессора, открыть магистраль данных между соответствующим устройством и ОЗУ и с соответствующей режиму работы скоростью перекачивать между ними данные.
Обмен по ПДП на шинах ISA, EISA и PCI имеет существенные отличия. Так, например, стандартный обмен при частоте 8 МГц на 16-разрядной шине ISA позволяет обмениваться данными с устройствами ввода-вывода со скоростью 0,1 Мбайт/с, а на шине EISA при частоте 8,33 МГц достигать скорости ввода/вывода до 4,17 Мбайт/с в стандартном режиме. В режиме групповой передачи на 32-разрядной шине EISA возможна скорость обмена до 33,33 Мбайт/с. На локальной шине PCI могут быть организованы режимы ускоренной передачи по ПДП (Multiword DMA) со скоростью 13,3 Мбайт/с или Ultra DMA со скоростью до 133 Мбайт/с при частоте 33 МГц на 32-разрядной шине (для обмена данными с УВП EIDE).
Примечания: в системе имеются каскады, т. е. объединения нескольких контроллеров прерываний и ПДП для расширения числа входных или выходных линий линии DMA разделены на 8- и 16-разрядные подгруппы; на линиях РМА шин EISA и PCI могут быть организованы передачи по 32-разрядным шинам данных в скоростных режимах.
Типичным примером использования DMA являются контроллеры дисководов и винчестера. В системах IBM PC XT/AT используется контроллер DMA Intel 8237A (, обеспечивающий четыре 8-битных канала DMA. В IBM PC AT применяется каскадное включение двух контроллеров DMA (: 8237A, обеспечивающего четыре 8-битных канала, и 8237A-5, обеспечивающего четыре 16-битных канала (см..)
Таблица Стандартное распределение каналов DMA
Структура микропроцессорной системы
Структура микропроцессорной системы
В широком смысле интерфейс включает также механическую часть (совместимость по типоразъемам) и вспомогательные схемы, обеспечивающие электрическую совместимость устройств по уровням логических сигналов, входным и выходным токам и т. д.
Подробное изучение интерфейсов и системных шин не входит в задачи данного курса. Поэтому эти вопросы мы будем рассматривать лишь с точки зрения общего представления об организации работы микропроцессорной системы и принципах взаимодействия составляющих ее устройств.
На интерфейсные схемы модулей возлагаются следующие задачи:
Эти интерфейсные схемы могут быть достаточно сложными. Обычно они выполняются в виде специализированных микропроцессорных БИС. Такие схемы принято называть контроллерами.
Контроллеры обладают высокой степенью автономности, что позволяет обеспечить параллельную во времени работу периферийных устройств и выполнение программы обработки данных микропроцессором.
Кроме того, предварительно буферируя данные, контроллеры обеспечивают пересылку сразу для многих слов, расположенных по подряд идущим адресам, что позволяет использование так называемого «взрывного»
Недостатком магистрально-модульного способа организации ЭВМ является невозможность одновременного взаимодействия более двух модулей, что ставит ограничение на производительность компьютера.
Взаимодействие микропроцессора с оперативной памятью (ОП) и внешними устройствами (ВУ) проиллюстрировано на рис. 8.2.
Для обмена информацией с внешними устройствами в МП имеются только 2 команды:
Сигналы IOR/ IOW формируются при выполнении только этих команд.
В связи с этим возможны два основных способа организации адресного пространства микропроцессорной системы:
Рассмотрим особенности обмена информацией микропроцессора с внешними устройствами. Упрощенная временная диаграмма этого процесса представлена на рис. 8.3.
Организация микропроцессорных систем: структуры, магистрали, обращение к памяти
 Под организацией микропроцессорной системы (МС) понимают совокупность устройств, связи между ними и их функциональные характеристики. Рассмотрим организацию МС на логическом уровне, или структурно–функциональную организацию.
Под организацией микропроцессорной системы (МС) понимают совокупность устройств, связи между ними и их функциональные характеристики. Рассмотрим организацию МС на логическом уровне, или структурно–функциональную организацию.
Типовые структуры микропроцессорных систем.
Тип структуры МС определяют состав и организацию памяти и подсистемы ввода/вывода (ВВ).
В памяти можно выделить:
● постоянные запоминающие устройства (ПЗУ), используемые для хранения программ и констант;
● оперативные запоминающие устройства (ОЗУ), предназначенные для хранения переменных и загружаемого извне объектного кода (программы).
В подсистеме ВВ можно выделить ряд законченных функциональных модулей:
● порты — простейшие модули в виде адресуемых центральным процессором (ЦП) буферных схем и регистров;
● периферийные адаптеры (ПА) — более сложные программно–управляемые модули. При использовании средств ВВ для управления внешними устройствами их называют периферийными контроллерами;
● сопроцессоры ВВ — наиболее сложные модули, работающие по собственным программам.
 К основным типовым структурам МС относятся:
К основным типовым структурам МС относятся:
● магистральная структура (рис. 3.1.1, а), в которой все модули подключены к магистрали. Использование единой магистрали обеспечивает выполнение за один рабочий цикл одной операции обмена данными между двумя (в общем случае любыми) модулями системы;
● магистрально–каскадная (рис. 3.1.1, б) и магистрально–радиальная (рис. 3.1.1, в) структуры, в которых используются контроллеры шин для реализации приоритетных отношений при обращении к магистрали.
В каждый момент времени магистраль предоставляется в распоряжение одному функциональному модулю. В простейших МС роль активного модуля выполняет центральный процессор (ЦП), который организует управление магистралью. В более сложных системах магистраль распределяется между отдельными модулями в соответствии с запросами на ее захват и приоритетными соглашениями. Эта задача возлагается на арбитра системной магистрали.
Магистрали микропроцессорных систем.
Обмен информацией центрального процессора (ЦП) с памятью и подсистемой ввода–вывода (ВВ) происходит по внутрисистемной магистрали, представляющей собой единый набор шин системы. Наиболее часто используется трехшинная магистраль с раздельными шинами передачи адреса и данных. Она состоит из следующих шин (рис. 3.1.2, а):
● шины данных ШД, предназначенной для обмена данными;
● шины адреса ША, по которой передаются адреса ячеек памяти или портов при обращениях;
● шины управления ШУ, служащей для управления работой системы. 
Некоторые микропроцессоры (например, микроконтроллеры МС S –51) имеют совмещенную шину адреса/данных (ША/Д). Микросистема с двухшинной магистралью приведена на рис. 3.1.2, б. В этом случае для разделения функций совмещенной шины ША/Д используется строб чтения адреса (ЧтА). При ЧтА = 1 шина ША/Д выполняет функцию передачи адреса, при ЧтА = 0 — функцию передачи данных. Фиксация адреса обычно осуществляется по срезу (переходу ЧтА из 1 в 0) в специальном адресном регистре (рис. 3.1.3, а, б). 
Организация пространств памяти и ввода–вывода.
С точки зрения программиста память можно представить как упорядоченный набор 8–разрядных ячеек (рис. 3.1.4, а). Каждой ячейке памяти (байту) сопоставляется число (номер), называемое адресом ячейки. Последовательность адресов составляет целочисленный ряд от 0 до 2 m – 1, где m — разрядность адресного кода, определяемая числом линий адресной шины. Совокупность всех адресов образует адресное пространство памяти. Такое пространство и его адрес называют линейными. В рассмотренных выше 8–разрядных процессорах линейный адрес эквивалентен физическому адресу, который выставляется на адресную шину для обращения к физической памяти емкостью 2 16 = 64К байт. 
Линейное адресное пространство обеспечивает доступ к любому байту памяти (рис. 3.1.4, б). Слова (2 байта) и двойные слова (4 байта) в линейной памяти занимают соседние байты. Порядок расположения байтов внутри слова: сначала младший ( L –байт), затем старший (Н–байт) байт слова (рис. 3.1.4, в, г). Адрес L –байта служит адресом всего слова и может быть как четным, так и нечетным (путем выбора начального адреса Ан).
В адресном пространстве памяти можно выделить три составляющих:
● CSEG ( Code Segment ) — пространство памяти команд (кода, программ);
● DSEG ( Data Segment ) — пространство памяти данных;
● RSEG ( Register Segment ) — пространство памяти программно доступных регистров.
На организацию памяти команд и данных влияет архитектура МС. В системах с гарвардской архитектурой пространства памяти команд и данных разделены. Системы с принстонской архитектурой имеют общую память и единое адресное пространство для команд и данных. Отметим, что при сегментной организации памяти реализуется отдельный доступ к сегментам команд и сегментам данных, однако сами сегменты могут располагаться по любым адресам.
Подсистему ввода/вывода (ВВ) можно представить в виде пространства IOSEG ( Input / Out Segment ) и правил доступа к нему. Возможно два вида пространств IOSEG :
1. Для многих процессоров предусмотрены команды обращения к портам, например, ввода IN и вывода OUT ;
Организация обращения к памяти и устройствам ввода/вывода.
При 16–разрядной адресной шине ЦП пространство памяти ограничено адресами 0000…FFFFh в шестнадцатеричной ( h ) системе, что соответствует десятичным номерам ячеек памяти от 0 до 65535. Требуемый объем памяти определяется типом и числом выбранных микросхем памяти, используемых в качестве модулей памяти.
Правая часть рис. 3.1.5 иллюстрирует принцип организации обращения к внешним устройствам — устройству ввода/вывода (УВ/В), устройству ввода (УВв) и устройству вывода (УВыв). Для адресации к устройствам отведены младшие адресные разряды А7, А0. Работа устройств ввода–вывода и ввода инициируется подачей сигнала записи ¯ЗпУВВ, а устройств ввода–вывода и вывода — подачей сигнала чтения ¯ЧтУВВ. С выходов устройств снимаются 8–разрядные операнды данных и сигнал готовности Гт (возможны также сигналы ЗАПРОСА ЗАХВАТА, ЗАПРОСА ПРЕРЫВАНИЯ и др.). При 8–разрядной адресации возможно подключение 256 устройств ввода–вывода или одновременно 256 устройств ввода и 256 устройств вывода.
Циклы обращения к магистрали.
При обмене данными между центральным процессором (ЦП) и памятью или подсистемой ввода/вывода (ВВ) за один цикл обращения к магистрали передается одно слово или байт. Существуют несколько типовых циклов обмена:
● циклы чтения памяти и записи в память;
● циклы чтения и записи в устройства (порты) ВВ (при изолированном пространстве ВВ IOSEG);
● цикл чтения памяти программ (для архитектуры гарвардского типа);
● цикл чтения–записи в память (для двухшинной магистрали). Этот цикл, требующий однократной передачи адреса, используется для увеличения пропускной способности магистрали.
Для управления циклами используются различные наборы сигналов (команд), передаваемых по шине управления ШУ. Сигналы представляют собой импульсы прямоугольной формы и называются стробами. Ниже в качестве примера приведено два возможных набора.
1 –й набор¯ЧтП чтение памяти (Memory Read Command — MRDC);
¯ЧтП запись в память (Memory Write Command — MWTC);
¯ЧтУВВ чтение из устройства ВВ Input/Output Read Command — IORC);
¯ЗпУВВ запись в устройство ВВ (Input/Output Write Command — IOWC);
ЧтПП чтение программной памяти (Program Segment Enable — PSEN).
2–й набор ¯Чт чтение RD ( Read );
¯Зп запись WR ( Write );
П/¯УВВ выбор пространства памяти или ВВ ( Memory or Input / Output — М/ IO );
ВПП выбор памяти программ ( Code — COD ).
Следует отметить, что с помощью логических схем второй набор можно преобразовать в первый. Возможно комбинированное использование обоих наборов. 
Временные диаграммы циклов обращения к трехшинной и двухшинной магистралям изображены на рис. 3.1.6, а, б.
Для разделения функций совмещенной ША/Д двухшинной магистрали используется строб чтения адреса (ЧтА). Фиксация адреса осуществляется по срезу (переходу ЧтА из 1 в 0) в специальном адресном регистре (рис. 3.1.3, а).
На приведенных временных диаграммах:
• адрес выставляется раньше, а снимается позже строба чтения ¯Чт;
• данные выставляются и снимаются с задержкой относительно строба чтения ¯Чт;
• фиксация данных осуществляется по заднему фронту строба чтения ¯Чт;
• адрес и данные выставляется раньше, а снимается позже строба записи ¯Зп;
• данные истинны в течение действия всего строба записи или фиксируются по заднему фронту строба записи ¯ЗпЗФ (для БИС с динамическим входом синхронизации).
Строб ЗпЗФ улучшает скоростные характеристики магистрали.
Рассмотренные циклы обращения к магистрали могут быть реализованы при обмене микропроцессора с высокоскоростными периферийными устройствами ПУ, такими, например, как память. Для организации надежного обмена с низкоскоростными внешними устройствами вводится дополнительная линия управления, по которой передается сигнал подтверждения обмена (ПОб) или готовности (Гт). 
При классической организации обмена (рис. 3.1.7) внешнее устройство, находящееся в состоянии обмена, выдает сигнал ПОб = 1, в противном случае — ПОб = 0. В каждом цикле обращения до окончания строба чтения/записи ( ¯Чт = 0 или ¯ЗпЗФ = 0) ЦП проверяет (по срезу тактовых импульсов ТИ) состояние сигнала ПОб. Если проверка показывает ПОб = 0, ЦП переходит в состояние ожидания подтверждения, генерируя сигнал ОжП = 1. После того, как установится сигнал подтверждения обмена и очередная проверка покажет ПОб = 1, ЦП снимает сигналы ожидания подтверждения (ОжП = 0) и чтения/записи ( ¯Чт / ¯ЗпЗФ =1). Данные фиксируются по срезу (из 0 в 1) сигналов чтения/записи. Завершение обмена внешнее устройство подтверждает сбросом сигнала подтверждения обмена (ПОб).
Буферизация шин данных и адреса.
Токи, потребляемые устройствами памяти и ввода/вывода по цепям шин данных и адреса значительно превышают допустимые значения токов для микросхем процессоров. Поэтому указанные устройства подключают к шинам данных и адреса микропроцессора через буферы, представляющие собой усилители импульсов. В буферах часто используются элементы с тремя состояниями выхода, два обычных состояния соответствуют высокому и низкому уровням выхода, а третье состояние Z — высокоомному выходному сопротивлению элемента. В состоянии Z элемент практически оказывается отключенным от нагрузки.
Элемент с Z –состоянием можно реализовать, например, путем введения в стандартную схему ТТЛ–инвертора полупроводникового диода VD 2 (рис. 3.1.8, а). Если на управляющем входе Z = 0, то потенциал коллектора (а также эмиттера) транзистора VT 2 близок к нулю и поэтому выходные транзисторы VT З, VT 4 находятся в режиме отсечки, т. е. в разомкнутом состоянии. При Z = 1 диод VD 2 отключен, и ТТЛ–инвертор с входом X и выходом Y работает в обычном режиме. Подключением к входу X инвертора получают повторитель с тремя состояниями выхода. На рис. 3.1.8, б, в приведены графические обозначения повторителя и инвертора с тремя состояниями выхода. 
Для построения буферов шин данных и адреса можно использовать шинные формирователи позволяющие осуществить управляемую двунаправленную передачу 8–разрядных слов. На рис. 3.1.8, г приведена схема, иллюстрирующая принцип построения шинного формирователя, используемого в 8–разрядных процессорах. В k –ю цепь передачи формирователя (k = 0, …, 7) включены два повторителя П1, П2 с тремя возможными состояниями выхода. Управление состояниями повторителей осуществляется с помощью логических элементов ЛЭ1, ЛЭ2. Режимы работы формирователя приведены в табл. 3.1.1.
Общие сведения об интерфейсе.
Под интерфейсом понимают совокупность аппаратных, программных и конструктивных средств, необходимых для реализации взаимодействия различных функциональных узлов микропроцессорных систем (МС) и направленных на обеспечение их информационной, электрической и конструктивной совместимости. Интерфейс МС представляет собой систему шин, вспомогательных узлов и алгоритмов, предназначенных для организации обмена информацией между микропроцессором, ОЗУ и внешними по отношению к ним узлами и устройствами (ВУ).
Как уже отмечалось выше, в систему шин входят шина данных (ШД), шина адресов (ША) и шина управления (ШУ).
Для подключения к центральной части МС (процессору и ОЗУ) внешних узлов и организации обмена информацией между ними используются интерфейсные схемы. Они позволяют:
● передавать на шину управления сигналы готовности ВУ к обмену данными с МС;
● осуществлять буферизацию шин и хранение данных, адресов и команд, что необходимо для синхронизации обмена информацией;
● выбирать требуемое внешнее устройство при работе МС с несколькими ВУ и дешифрировать их адреса, посылаемые микропроцессором;
● дешифрировать коды и инициировать выполнение команд при работе с такими внешними устройствами, которые помимо передачи данных выполняют другие операции;
● осуществлять синхронизацию и формирование управляющих сигналов, необходимых для правильной реализации любой из перечисленных выше функций;
● управлять процессом передачи данных и преобразовывать их форматы;
● выполнять другие функции, обусловленные спецификой интерфейсной схемы.