Почему капчи стали такими сложными
Доказывать, что ты не робот, становится всё сложнее

В какой-то момент прошлого года постоянные требования от Google доказать, что я человек, начали казаться всё более агрессивными. Всё чаще за простой и немного чересчур милой кнопочкой «Я не робот» начали появляться требования доказать это – выбрав все светофоры, переходы или витрины в сетке изображений. Вскоре светофоры начали прятаться в листве, переходы искажаться и уходить за угол, а вывески магазинов стали размытыми и перешли на корейский язык. Есть что-то весьма разочаровывающее в неудачных попытках найти на изображении пожарный гидрант.
Эти тесты называются CAPTCHA – акроним от «полностью автоматического публичного теста Тьюринга, предназначенного для различения людей и компьютеров», и когда-то они уже доходили до подобной степени неразборчивости. В начале 2000-х простых изображений с текстом было достаточно, чтобы остановить большинство спам-ботов. Прошло десять лет, и после того, как компания Google купила программу у исследователей из Университета Карнеги-Меллона и использовала её для оцифровки в проекте Google Books, тексты приходилось всё сильнее искажать и скрывать, чтобы обгонять улучшающиеся программы оптического распознавания символов – те самые программы, которые помогали улучшать те самые люди, кому приходилось разгадывать все эти капчи.
Поскольку CAPTCHA – элегантный инструмент для тренировок ИИ, то любой придуманный тест может продержаться лишь некоторое время, что признают и его изобретатели. Со всеми этими исследователями, мошенниками, и простыми людьми, решающими миллиарды задачек на грани возможного для ИИ, в какой-то момент машины просто обязаны были нас обогнать. В 2014-м Google стравила между собой свой лучший алгоритм по разгадыванию самых искажённых текстов и людей: компьютер правильно распознал текст в 99,8% случаев, а люди всего в 33%.
После этого Google перешла на NoCaptcha ReCaptcha, наблюдающую за поведением людей и собирающую их данные, что позволяет некоторым из них пройти дальше просто по клику на кнопке «Я не робот», а другим выдаёт задачи на поиск изображений, которые мы сегодня и наблюдаем. Но машины снова настигают нас. Все эти навесы, которые могут быть или не быть витринами магазинов – это заключительная стадия гонки вооружений людей и машин.
Язон Полакис, профессор информатики в Университете Иллинойса в Чикаго лично отвечает за недавнее усложнение капчи. В 2016-м он опубликовал работу, в которой использовал готовые программы распознавания изображений, включая собственный поиск по изображением от Google, чтобы решать капчи с точностью в 70%. Другие исследователи справлялись с распознаванием аудио капчи от Google при помощи программ по распознаванию речи от самой же компании.
Машинное обучение уже не хуже людей справляется с распознаванием простых текстов, изображений и голоса, говорит Полакис. Алгоритмы, возможно, даже делают это уже лучше: «Мы дошли до момента, когда усложнение задач для софта приводит к тому, что задачи становятся чрезмерно сложными для людей. Нам нужна альтернатива, но чёткого плана пока нет».
Литература по капчам переполнена фальстартами и странными попытками найти что-то кроме текста и изображений, с чем хорошо справляются все люди и плохо справляются машины. Исследователи пробовали предлагать пользователям сортировать изображения людей по выражению лиц, полу и этнической принадлежности (можете представить, как это прошло). Были предложения организовать капчи с викторинами, капчи на основе колыбельных, распространённых в тех местах, где, как предполагается, вырос пользователь. Такие капчи с культурной привязкой нацелены не только на роботов, но и на людей из других стран, решающих капчи за копейки. Люди пытались загнать алгоритмы распознавания изображений в тупик, предлагая пользователю опознать, например, свинью, но при этом рисованную и в солнечных очках. Исследователи изучали такие варианты, как предложить пользователям распознать объекты в мешанине калейдоскопа. В одном из интересных вариантов в 2010-м исследователи предложили использовать капчу для сортировки древних петроглифов – компьютеры плохо справляются с распознаванием скетчей или изображений оленей на стенах пещер.
Недавно были попытки разработать игровые капчи, где пользователю нужно вращать объекты на определённые углы или передвигать кусочки головоломки, причём инструкции по решению капчи давались не в виде текста, а в виде символов, или же подразумевались по контексту игрового поля. Надежда на то, что люди поймут логику загадки, а компьютеры без чётких инструкций споткнутся. Другие исследователи пытались использовать факт наличия у людей тел, и применяли камеры устройств или дополненную реальность для интерактивного подтверждения наличия человека.
Со многими из этих тестов проблема не в том, что роботы слишком умные, а в том, что люди плохо с ними справляются. И дело не в том, что люди тупые; они просто очень сильно различаются по языку, культуре и опыту. Избавившись от всего этого, чтобы сделать тест, который может пройти любой человек без тренировки и долгих размышлений, мы остаёмся с такими грубыми задачами, как распознавание изображений – а это именно то, с чем хорошо справится специально заточенный под это ИИ.
«Тесты ограничены возможностями человека, — говорит Полакис. – Дело не только в физических возможностях – нужно найти что-то межкультурное, межъязыковое. Нужна задача, которая хорошо работает с человеком из Греции, с человеком из Чикаго, с человеком из Южной Африки, Ирана и Австралии одновременно. И она не должна зависеть от культурных нюансов и различий. Нужна задача, с которой хорошо справляется средний человек, она не должно быть ограничено определённой подгруппой людей, и она должна быть трудной для компьютера. Всё это сильно ограничивает выбор вариантов. А ещё это должно быть что-то, с чем люди справляются быстро, и что не сильно раздражает».
Попытки решения этих загадок с размытыми картинками быстро переводят человека на философские рельсы: есть ли какое-то универсальное человеческое качество, которое можно продемонстрировать машине, и которое машина не может имитировать? Что значит – быть человеком?
Может, наша человечность измеряется не тем, как мы выполняем задачи, а тем, как мы ведём себя, продвигаясь сквозь мир – или, в данном случае, сквозь интернет. Игровые капчи, видеокапчи, любые капчи, которые вы сможете придумать, в итоге будут взломаны, говорит Шуман Госмахумдер [Shuman Ghosemajumder], занимавшийся в Google борьбой с автоматизацией кликов, а потом ставший технологическим директором компании по распознаванию роботов Shape Security. Он склоняется в сторону «постоянной авторизации» вместо отдельных тестов – к наблюдению за поведением пользователя и поиску признаков автоматизации. «Реальный человек не очень хорошо контролирует моторику, и не может двигать мышь одинаковым образом много раз во время нескольких взаимодействий, даже если будет пытаться сделать это», — говорит Госмахумдер. Робот будет взаимодействовать со страницей, не двигая мышью, или двигая её очень точно, а в действиях человека будет наблюдаться «энтропия», которую сложно подделать, говорит Госмахумдер.
Собственная команда Google, занимающаяся капчей, работает в сходном направлении. Последняя версия reCaptcha v3, выход которой был объявлен в конце прошлого года, использует «адаптивный анализ рисков» для оценки трафика по подозрительности; владельцы сайтов могут предлагать подозрительным пользователям задачи вроде ввода пароля или двухфакторной авторизации. В Google не сообщают, какие факторы учитываются при оценках, кроме того, что компания оценивает, как выглядит на сайте «хороший трафик», и использует эту информацию для фильтрации «плохого трафика», согласно Сай Кормаи [Cy Khormaee], менеджеру продукта из команды CAPTCHA. Исследователи в области безопасности говорят, что это, вероятно, смесь куков, атрибутов браузера, закономерностей трафика и других факторов. Один недостаток новой модели распознавания роботов состоит в том, что навигация в вебе при попытках минимизации наблюдений за пользователем может стать немного раздражающей, поскольку такие вещи, как VPN и расширения, затрудняющие отслеживание пользователя, могут отметить вас, как подозрительного.
Аарон Маленфант [Aaron Malenfant], ведущий инженер команды CAPTCHA в Google, говорит, что сдвиг в сторону от тестов Тьюринга должен помочь обойти соревнование, которое люди всё время проигрывают. «Чем больше мы будем вкладываться в машинное обучение, тем сложнее эти задачи будут становиться для людей, и, в частности, поэтому мы запустили CAPTCHA V3 – чтобы опередить эту кривую». Маленфант говорит, что через 5-10 лет задачи в капче вообще не будут иметь смысла. Большая часть веба будет зависеть от постоянного скрытого теста Тьюринга, работающего на фоне.
В своей книге «Самый человечный человек» Брайан Кристиан [Brian Christian] принимает участие в тесте Тьюринга в качестве подсадной утки и понимает, что очень сложно доказать свою человечность в беседах. С другой стороны разработчики ботов обнаружили, что эти тесты легко пройти, не притворяясь красноречивым или интеллектуальным собеседником, а отвечая на вопросы при помощи нелогичных шуток, делая опечатки, или, как в случае бота, выигравшего соревнование Тьюринга в 2014-м, заявляя, что ты – 13-летний украинский мальчик, плохо говорящий по-английски. Ведь человеку свойственно ошибаться. Возможно, что такое будущее ждёт и капчу, самый распространённый тест Тьюринга в мире – новая гонка вооружений будет создавать не роботов, превосходящих людей в сортировке изображений и разборе текста, а роботов, делающих ошибки, промахивающихся по кнопкам, отвлекающимся и переключающим вкладки. «Думаю, народ начинает понимать, что есть области применения для симуляции среднего пользователя-человека… или тупых людей», — говорит Госмахумдер.
Капчи могут сохраниться и в этом мире. В 2017-м Amazon зарегистрировала патент на схему, в которой используются оптические иллюзии и логические задачки, с которыми тяжело справляться людям. Этот тест называется «тест Тьюринга через ошибку», и единственный способ пройти его – дать неверный ответ.
Обойти капчу, или Как сайты проверяют человека

Капча (CAPTCHA), требующая доказать, что «Я не робот», появляется на все большем количестве сайтов и сервисов, и раздражает пользователей. Есть несколько причин, из-за которых сайты принимают посетителей за ботов и требуют введения проверочным символов. Можно ли избавиться от повторяющейся проверки, что нужно изменить в настройках браузера и странице во «Вконтакте», как обойти капчу с помощью VPN-сервисов?
Что такое капча?
CAPTCHA — автоматизированный публичный тест Тьюринга. Он позволяет определить бота среди посетителей сайтов. Механизм защиты веб-сервисов от спама разработала в 2000 году команда университета Карнеги — Меллон. Идея теста в том, что предложенное задание легко выполняется людьми, но недоступно для машин.
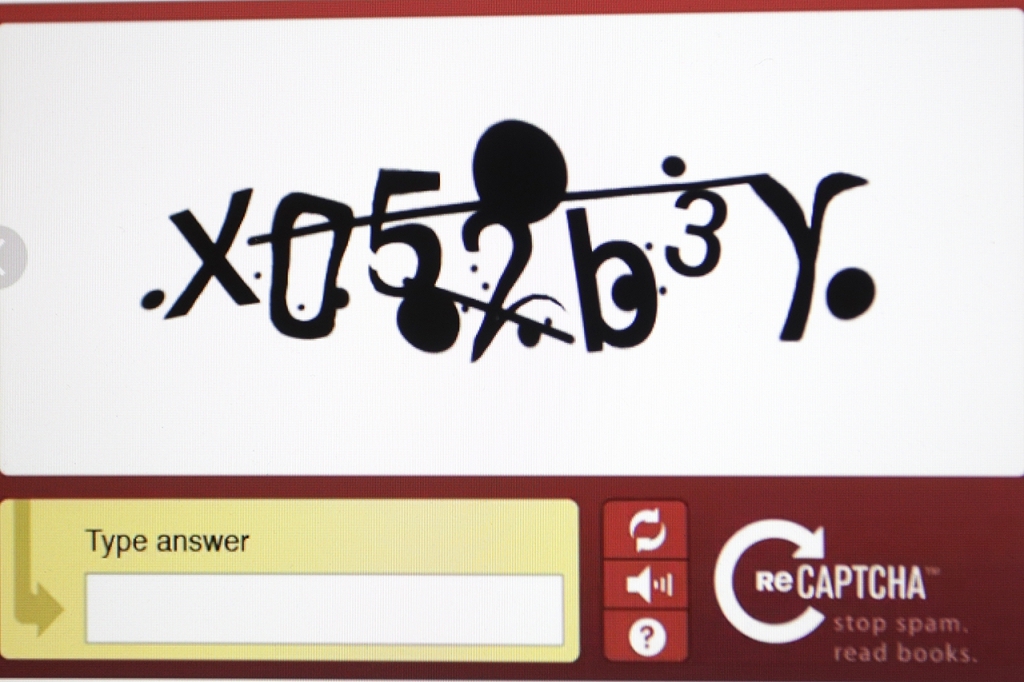
Чаще всего пользователям нужно ввести символы с картинки. Они изображены с помехами, или полупрозрачны, чтобы машина не могла их распознать. Изначально система хорошо работала, снизила нагрузку на сайты, избавила их от фальшивых комментариев.

Через семь лет после создания теста Тьюринга появилась модификация — reCAPTCHA. Людям предложили распознавать слова отсканированных выпусков газеты The New York Times. Защита от спама одновременно помогала оцифровывать издание.
Но компьютеры становились все мощнее и стали способны распознать символы. Поэтому появились другие варианты: поиск кошек, дорожных знаков на картинках или галочка напротив фразы «Я не робот».
Полезный для администрации сайтов тест стал раздражать пользователей. Иногда приходится вводить капчу по несколько раз, чтобы увидеть какую-то страницу. Отдельной проблемой становится капча во «ВКонтакте».
Существует несколько причин, по которым пользователю приходится постоянно доказывать, что он не робот. Даже если человек не спамит, а просто оставляет комментарии или общается в соцсетях, его может преследовать ввод символов.
Подозрительный трафик с компьютера. Расширения браузера или вирусы на устройстве юзера могут стать частью сети ботов. За это reCAPTCHA блокирует его IP-адрес.
Плохая компания. Провайдеры выделяют для группы абонентов один реальный IP. Поэтому если один из них бот, его блокируют, и вся группа попадает в чёрный список.
Выключение JavaScript на смартфоне. Механизм reCAPTCHA — код JavaScript на сайте. Кодами пользуются не только сервисы, но и мошенники, поэтому в смартфонах для безопасности в браузерах отключен JavaScript. Это приводит к тому, что reCAPTCHA работает со сбоями.
Как избавиться от капчи
Пользователи Google Chrome могут избавиться от надоедливой защиты, отключив ряд расширений. Блокирующее рекламу расширение AdBlock или плагин RDS Bar часто приводят к появлению капчи.
Еще один вариант для компьютеров — заново подключиться к интернету. После перезагрузки модема или роутера юзер может получить новый внешний адрес, и избавиться от назойливой проверки.
Владельцы iPhone могут в разделе настроек Safari открыть вкладку «Дополнения» и включить JavaScript. Пользователям Android в Chrome, нужно нажать на меню с тремя точками, перейти в «Настройки», открыть «Настройки сайтов» и также активировать JavaScript. Еще один вариант для мобильных — ненадолго включить авиарежим, после которого смартфон перерегистрируют в сети, и сможет получить незапятнанный IP.
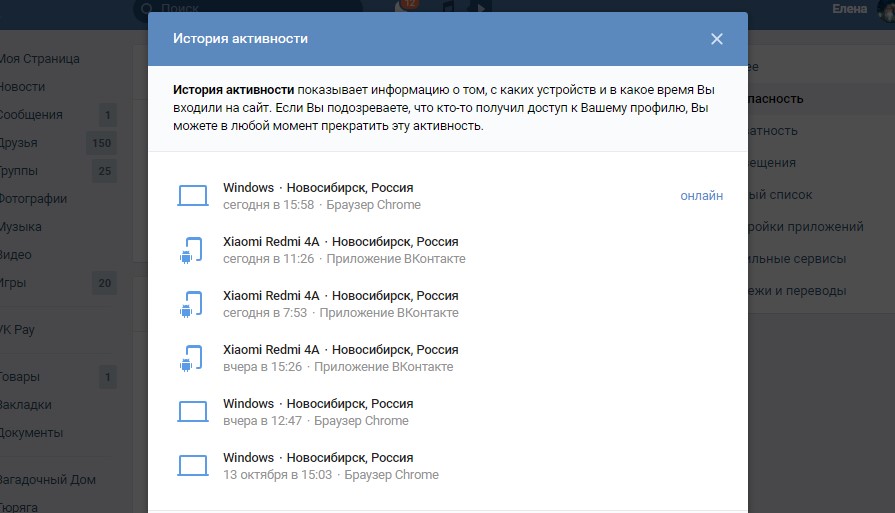
Избавиться от капчи «ВКонтакте» можно за несколько минут. В настройках страницы надо перейти в раздел «Безопасность», нажать на «Показать историю активности». Всплывшее окно покажет историю посещений сайта и IP, с которого осуществлялся вход.
Если в списке адрес, который отличается от адреса пользователя, нужно нажать «Завершить все сеансы». А затем сменить пароль. Кроме того, капча появляется реже, если страница привязана к номеру телефона.
Если капчу вводить лень даже изредка, это за плату сделают другие юзеры. На специализированных веб-сервисах возьмут примерно 40 рублей за разгадывание тысячи картинок. Пользователь же получит специальный ключ, позволяющий ему забыть о надоедливом тесте.
Если колдовство с настройками не помогло, придётся воспользоваться сервисами VPN. Крупные компании оказывают эту услугу платно. Но есть и бесплатные сервисы с хорошим интерфейсом и удобные в эксплуатации. Например, программа CyberGhost VPN (скачать бесплатно >>).
Сервис работает с всеми популярными браузерами, отлично защищен благодаря протоколу OpenVPN с 256-битным шифрованием AES. Бесплатно можно запускать только на одном устройстве. Пользователь получит доступ к 37 серверам в 12 странах, работает без перерыва около трех часов, после этого надо снова подключит и продолжить работу.
У вас постоянно вылезает капча и достает вопросом «Вы не робот?» Зачем ее придумали и как от нее избавиться
Откуда взялась CAPTCHA?
Технология CAPTCHA (сейчас будет страшная расшифровка: Completely Automated Public Turing Test to tell Computers and Humans Apart — «полностью автоматический тест Тьюринга, разделяющий компьютеры и людей») появилась в 2000 году.
Это была первая успешная попытка установить «фейс-контроль» для каждого посетителя сайта. Сетевые боты только начали появляться, но разработчики подготовились с ними сражаться. Бот-системы могли перегружать сайты, делая их недоступными для живых людей. Так, например, на форуме без капчи в начале нулевых можно было автоматически зарегистрировать десятки тысяч фейков и заспамить форум рекламой.
Для борьбы с такими ситуациями в американском Университете Карнеги-Меллона придумали скрипт, который требовал при доступе к сайту ввести символы с трудноразличимой картинки. Для пользователя ребус был несложный: буквы, раскиданные по изображению в хаотичном порядке и искаженные помехами, легко считывались человеком. Зато компьютерные системы распознавания текста терялись. Такой простейший барьер позволил значительно снизить нагрузку на популярные сайты, а также защитить многие порталы от фейковых регистраций и комментариев.
Как CAPTCHA стала полезной
Когда «капчу» стали использовать чересчур часто, сообщество задумалось о более полезном применении технологии. В 2007 году появилась reCAPTCHA, где вместо абстрактных картинок пользователям показывали нераспознанные компьютером слова из сканов архивных выпусков газеты The New York Times.
Аудитория теперь не расшифровывала тарабарщину, а помогала оцифровывать бумажную прессу XX века. Подтвердил, что ты человек, а заодно добавил слово.
Вскоре технологию купила Google и использовала ее для оцифровки книг.
Боты тоже развивались и научились автоматически распознавать текстовую reCAPTCHA. Тогда Google выпустила принципиально новый алгоритм проверки. Теперь вместо расшифровки слов пользователям предлагали среди девяти картинок найти те, где есть котики, дорожные знаки или, например, бананы. reCAPTCHA вновь стала эффективной, а людям не пришлось ломать глаза в попытке распознать очередное неудачно отсканированное слово из книги.
В самой новой версии reCAPTCHA человеку вообще не нужно напрягаться, достаточно поставить галочку напротив отметки «Я не робот» — алгоритм анализирует движения курсора (бот пойдет по прямому кратчайшему пути) и IP-адрес. До недавних пор reCAPTCHA работала крайне эффективно и почти незаметно для пользователей.
Однажды что-то пошло не так
С первыми ошибками в работе reCAPTCHA столкнулись пользователи смартфонов. Заходишь в строку поиска Google, но вместо результата браузер показывает графическую «капчу». где надо искать объекты на матрице изображений. Причем успешно пройти тест порой было невозможно, reCAPTCHA требовала от пользователя вновь и вновь отмечать картинки.
Вслед за Google проверка пользователя всплыла и на других сайтах. Российский интернет наполнился жалобами на операторов связи, Google и даже Роскомнадзор — пользователей раздражало, что сайты при каждом посещении начали требовать подтверждения человеческой природы.
Первое время никто, включая техподдержку сайтов и провайдеров, не мог внятно ответить на вопрос, что же случилось и как пройти проверку reCAPTCHA. Когда специалисты взялись за изучение проблемы, всплыли сразу несколько причин, по которым сервис проверки на «человечность» начал неистово сбоить.