Проверка поступающих заявок на дубли в Roistat¶
Для чего нужна проверка на дубли?¶
Проверка на дубли отсеивает повторяющиеся заявки. Это нужно для того, чтобы в CRM не скапливались лишние данные, а также для создания точных статистических отчётов.
Механизм проверки на дубли < #mechanism data-toc-label='Механизм проверки на дубли' >¶
Новые сделки связываются с контактами, которые поступили в CRM через Roistat.
Если с момента создания первой заявки в течение часа пришла новая заявка с дублирующимися данными, то она не отправится в СRM и будет помечена как дубль в любом случае (даже если удалить или изменить статус первой заявки). Это связано с тем, что синхронизация Roistat с подключенной к проекту CRM проходит один раз в час.
Виды проверки на дубли¶
Существует два вида проверки на дубли: стандартная проверка и пользовательская проверка.
Стандартная проверка¶
Алгоритм стандартной проверки на дубли:
Процесс отправки заявки в CRM зависит от конкретной интеграции. Чтобы узнать, как отправляются заявки в конкретной CRM, читайте документацию по интеграции Roistat с CRM.
Проксилид – массив данных, в котором Roistat передает информацию о заявке.
Описание алгоритма
При поступлении нового заказа Roistat начинает проверять созданные за последние 12 часов проксилиды. Если среди них нет дублей, то начинается проверка с учетом сделок (проверяются только сделки за последние 30 дней).
На полное совпадение проверяются следующие поля заявок: заголовок заявки (название), имя клиента, телефон, email, номер визита, а также дополнительные поля.
Заявки с одинаковыми значениями полей (название, имя, телефон, email, номер визита) считаются дублями и не заносятся в проект.
Одинаковые заявки с разными значениями дополнительных полей также относятся к дублям.
При проверке телефонные номера разных форматов (7499xxxxxxx, 8499xxxxxxx и 499xxxxxxx) считаются одинаковыми.
Оплаченные и отмененные сделки можно не проверять на дубли, так как клиент может зайти на сайт и оставить или отменить заказ несколько раз.
Чтобы узнать, какие статусы находятся в группе В работе, нужно открыть раздел Интеграции и перейти в настройки подключенной интеграции, где отображаются статусы сделок, распределенные по группам статусов Roistat:
При поступлении заявок через Коллтрекинг Roistat проверяет наличие в проекте заявок с тем же номером телефона и статусом В работе. Если Roistat находит их, то новые заявки не создаются.
При интеграции с целями работает только стандартная проверка на дубли.
Пользовательская проверка¶
В интеграциях amoCRM, Битрикс24 (сделки), Битрикс24 (лиды+сделки), RetailCRM (новая интеграция) и Salesforce при пользовательской проверке на дубли учитываются все заявки, заведенные в СRM-системе. Интеграция больше не будет создавать лишние дубли.
Ранее проверка осуществлялась только по заявкам, которые были созданы нашей системой.
Пользовательская проверка удобнее стандартной, так как отслеживает заявки по дополнительным параметрам за любое количество дней (в стандартной – только за 12 часов).
Алгоритм пользовательской проверки на дубли:
Процесс отправки заявки в CRM зависит от конкретной интеграции. Чтобы узнать, как отправляются заявки в конкретной CRM, читайте документацию по интеграции Roistat с CRM.
Чтобы настроить пользовательскую проверку:
В проекте Roistat откройте раздел Интеграции.
Перейдите в настройки подключенной CRM.
В окне настроек интеграции нажмите Настройка проверки на дубли:
Передвиньте вправо переключатель Включить проверку дублей, чтобы Roistat проверял заявки по указанным ниже параметрам. В этом случае правила проверки на дубли, описанные в начале статьи, не учитываются. Если переключатель кнопки оставлен в выключенном положении, Roistat будет проверять поступающие заявки по изначальному алгоритму.
Если включить опцию С таким же номером телефона, Roistat не будет создавать заявки от клиентов, чей телефон уже есть в проекте Roistat.
Если включить опцию С таким же email, Roistat не будет создавать заявки от клиентов, чей адрес электронной почты уже есть в проекте Roistat.
Если включена проверка и по номеру телефона, и по email, достаточно совпадения только по одному признаку, чтобы Roistat считал поступающую заявку дублем.
В настраиваемой проверке на дубли система не учитывает заголовки. Сделка будет помечена как дубль, если заголовки различаются, но при этом выполняется одно из указанных условий.
Для большинства CRM также можно указать действие, которое нужно выполнить в случае получения дублирующей заявки. Подробнее – в разделе Настройка действий при получении дублирующей заявки.
В поле За какой период учитывать заявки? укажите период, прошедший с момента создания заявки. Можно указать любое количество дней. Если оставить в поле значение 0, будут проверяться заявки за последние 90 дней.
В разделе Заявки в каких статусах проверять? нужно выбрать статусы, сделки в которых должны проверяться на дубли. В списке отображаются статусы из групп В работе,Оплаченные и Отмененные. Необходимо указать хотя бы один статус.
Нажмите кнопку Сохранить.
Roistat сравнивает поступающие заявки со всеми имеющимися в проекте заявками, подходящими под параметры в пунктах 4-7. Сделки, которые Roistat определил как дубли, отображаются в разделе Диагностика проекта → Список отправленных заявок с пометкой Дубль в графе Статус.
Параметр ‘is_need_check_order_in_processing’ => ‘0’ не участвует в пользовательской проверке на дубли.
Почему важно указывать период для учета заявок
По некоторым причинам сделки могут долго оставаться в неактуальном статусе, хотя по факту работа с ними закончена. Если в пункте 6 указан период 0 (= 90 дней), и при проверке на дубли Roistat находит идентичную сделку с указанным в пункте 7 статусом, поступающая сделка считается дублем и не добавляется в проект. В этом случае теряются сделки, которые объективно следует добавлять в проект. Уточнение периода в пункте 6 решает эту проблему. Сделки, идентичные уже добавленным в проект вне указанного периода, Roistat не считает дублями и добавляет их в проект.
Настройка действий при получении дублирующей заявки¶
Создание задач и комментариев по дублирующей сделке¶
Для того, чтобы менеджеры могли успешно отрабатывать заявки-дубли, можно включить создание задач и комментариев к дублю. Эта возможность доступна при интеграции с amoCRM, Битрикс24, RetailCRM, ExoCRM, 1С Битрикс, Ramex, Advantshop, РемОнлайн, Webasyst, OpenCart 3.0, Архимед, HubSpot, Salesforce. При интеграции с Мой Склад и EnvyCRM можно создать только комментарий к дублю.
Вы также можете установить время на выполнение задачи, созданной при получении дубля. Эта возможность работает следующим образом: при обнаружении дубля менеджеру ставится задача с текстом Повторная заявка от клиента и указывается время, за которое менеджер должен выполнить заявку. После этого менеджер связывается с клиентом и дополняет текущую заявку новой информацией. Это помогает не терять повторные заявки от клиентов и не накапливать лишние заявки.
В разделе Диагностика проекта → Список отправленных заявок можно самостоятельно проверить, в какой сделке была создана задача и комментарий:
Возможность создавать задачи и комментарии по дублям доступна только в пользовательской проверке на дубли.
Чтобы менеджер не пропускал повторные заявки, нужно настроить автоматическое создание дополнительных задач и комментариев в сделке, с которой работает менеджер.
При включенной функции Создать задачу в текущей сделке Roistat создает задачу только в одной сделке. Текст задачи, которую должен выполнить менеджер, будет браться из проксилида.
При включенной функции Создать комментарий в текущей сделке Roistat отправляет ссылку на запись повторного звонка.
При интеграции с amoCRM к дублирующей заявке можно добавить комментарий и задачу, если Roistat отправляет заявки в статус Неразобранное и если оригинальная сделка не находится в статусе Неразобранное.
Перевод оригинальной сделки в определенный статус¶
Если вы используете amoCRM, Битрикс24 или RetailCRM, вы можете автоматически переводить оригинальную сделку в определенный статус, если Roistat находит дубль этой сделки. Например, по сделкам, которые уже находятся в статусе В работе, могут поступать повторные заявки. В таких случаях удобно автоматически перевести сделку обратно в статус Первичный контакт, чтобы обработать ее нужным образом. Вместо Первичный контакт вы можете указать любой статус.
Чтобы настроить это действие, активируйте опцию Перевести текущую сделку в статус и выберите нужный статус (список загрузится из подключенной CRM):
Данная опция работает только при создании заявок через Roistat.
Технический аудит: поиск дублей страниц
Технический аудит: поиск дублей страниц
Продолжаем серию статей о техническом аудите. Наверняка многие слышали, что дубли страниц – это плохо. Сегодня, как и обещали, подробнее разберемся в этой теме.
Что такое дубли страниц?
Страницы считаются дублями, когда они доступны по разным адресам, но при этом имеют одинаковое содержание. Поисковые роботы такие страницы признают некачественными и удаляют из выдачи ранжируя только одну из них.
Дубли страниц могут появиться по разным причинам. Например, на сайте интернет-магазина дубли могут появляться, когда страница одного товара присутствует в разных категориях сайта по разным URL. Но могут быть и другие причины, которые связаны с неправильной организацией структуры сайта, при автогенерации документов, некорректных настройках или неправильной кластеризации.
Чем так опасны дубли страниц?
В индекс попадет меньше полезных страниц.
Поисковому роботу потребуется значительно больше ресурсов для полного переобхода ресурса. Важно, некоторые страницы робот будет довольно редко обходить, т.к. у поисковой системы на каждый сайт выделен определённый крауленговый бюджет.
Неверно распределяется внутренний ссылочный вес.
Имея ссылки на дубли документов часть внутренней ссылочной массы будет распределяться между оригиналом и копией, что уменьшит значимость основной страницы. Встречались ситуации, когда на копию было больше ссылок, чем на оригинал и выдаче появлялся дубль.
Теряется внешний ссылочный вес.
Если пользователь решит поделиться информацией со страницы дубля, то он будет ссылаться именно на нее, а значит вы потеряете полезную естественную ссылку. Если по данной ссылке будут переходы, то поведенческие факторы учтутся для страницы дубля.
Разделение поведенческих факторов на 2 документа.
Получается, дубли страниц довольно опасны с точки зрения SEO. Они критично воспринимаются поисковыми системами и могут привести к серьезным потерям в трафике.
Кроме этого, за повторяющийся контент можно получить санкции от поисковых систем. Для Гугла они будут выражаться в резком, а для Яндекса в более плавном проседании позиций.
Если вы хотите узнать больше об этом фильтре, напишите в комментариях, и мы с удовольствием расскажем вам о нем подробнее.
Откуда берутся дубли?
Дублями считается, как полное совпадение контента на страницах, так и частичное, когда некоторая часть контента дублируется на ряде страниц, хоть они и не являются абсолютными копиями. В целом, поисковики наиболее критично относятся к полным дублям, но не стоит забывать о том, что и частичные дубли также могут негативно сказываться на позициях.
Рассмотрим основные причины возникновения дублей:
Генерация дублей CMS:
Распространенной причиной появления дублей являются ошибки в CMS. Например, часто дубли генерирует WordPress, т.к. страница учитывается только по последней части URL:
Страницы по разным URL могут друг друга дублировать.
Одна и та же страница расположена по адресу с «www» и без «www»:
Для поисковых систем подобные домены считают, как 2 разных сайта поэтому это приводит к полному дублированию всего сайта.
Дубли страниц с протоколами http и https:
Аналогично пункту 2, но в данном случае, разные протоколы по которым доступен сайт.
Страницы с прописными и строчными буквами в URL:
Дубли страницы по адресам:
Один из этих адресов может быть основным адресом страницы по умолчанию.
Пример дублей (на момент написания статьи):
Дубли, сгенерированные реферальной ссылкой
Обычно такие страницы содержат специальный get-параметр, который добавляется к URL. И если они, не меняя содержание, меняют сам параметр в URL, то становятся дублями. В данном случае рекомендуем настроить rel= «canonical» на страницу без параметра.
К возникновению дублей приводят и ошибки в иерархии URL.
Например, один и тот же товар может быть доступен по адресам:
Например, в Bitrix часто можно встретить такие дубли, когда URL товаров привязывают к разным категориям и в каждой категории товары формируются по ссылке формата: сайт+категория+товар:
Полные дубли легче найти и устранить, чем частичные. Чаще всего причина их появления зависит от особенностей CMS и навыков разработчика сайта.
Что касается частичных дубликатов, то их найти сложнее.
Главными причинами появления частичных дублей являются:
Страницы пагинации, фильтров, сортировок.
При том, что URL изменился и робот будет индексировать его как отдельную страницу основной SEO – контент будет продублирован.
Страницы комментариев, характеристик, отзывов.
Часто встречается ситуация, когда при выборе необходимой вкладки на странице товара происходит добавление параметра в URL адрес, но сам контент фактически не меняется.
Несмотря на то, что эти страницы имеют разный адрес, их содержимое совпадает на 100%.
Версии для скачивания и для печати.
Такие страницы полностью дублируют контент основных страниц, но при этом имеют упрощенную версию из-за отсутствия большого количества строк кода.
Решением для таких дублей является настройка атрибута rel=»canonical», который укажет на основной адрес.
Дубли в скрытых (всплывающих) блоках.
Часто информация дублируется в блоках, которые появляются после клика или наведения курсора на элемент, например, на кнопку.
Такими блоками могут быть: формы обратной связи, политика конфиденциальности.
Наличие не уникальных тегов Title, Description, H1.
Иногда такие страницы, тоже ПС принимают за дубли. Теги Title, Description, H1 должны содержать информацию, описывающую страницу, на которой они находятся. Так как на сайте не должно быть одинаковых страниц, то и мета-теги должны быть уникальными на каждой странице и не должны дублироваться.
К появлению дублей могут приводить и другие причины, например, человеческий фактор, т.е. банальное дублирование статей. А некоторые ошибки могут возникать и по причине отсутствия редиректа со старой страницы на новую, из-за особенностей отдельных скриптов и плагинов. С каждой такой проблемой лучше разбираться по отдельности.
Теперь давайте рассмотрим, как можно найти внутренние дубли на сайте.
Поиск ошибок в Яндексе:
Переходим в раздел: “Страницы в поиске”:
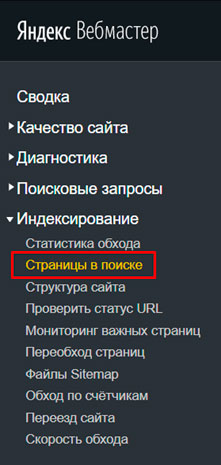
Далее выбираем вкладку “Исключенные страницы”
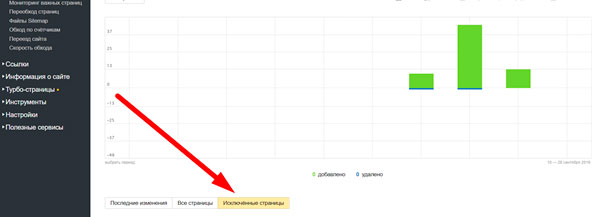
В столбце Статус указываем фильтрацию по “Дубль”
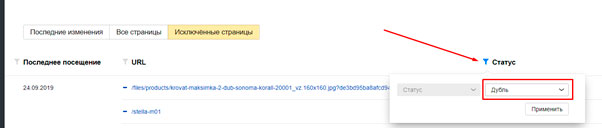
В результате увидим все страницы, признанные дублями.
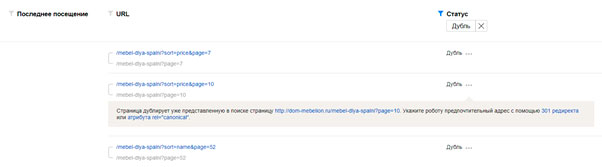
Поиск дублей в Google:
Переходим в раздел “Покрытие”
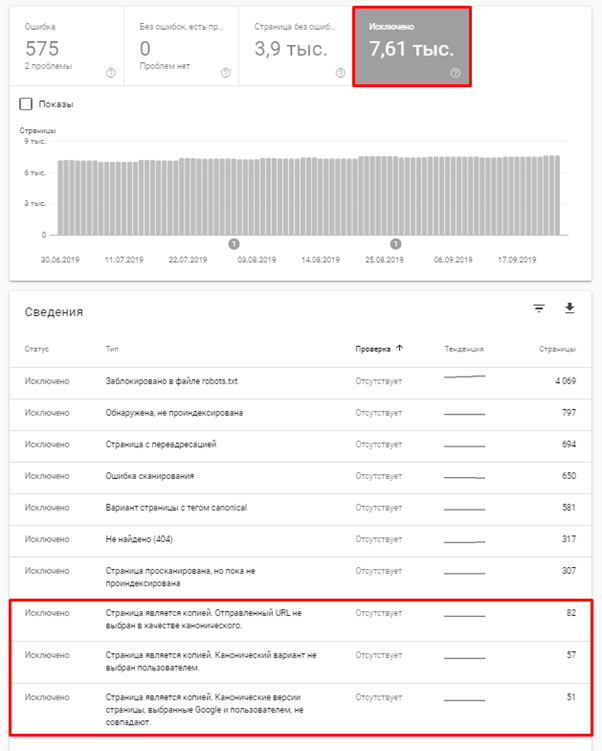
Смотрим вкладку “Исключено”. Здесь может быть 3 варианта ошибок с дублями (представлено на скрине)
Проверить страницы на совпадающие заголовки можно даже тогда, когда у вас нет доступа к панели. Для этого нужно ввести в поисковую строку соответствующий запрос.
Для Яндекса:
site: vashdomen.ru title:”заголовок”
Конечно, здесь нужно указать свой домен и тег Title, дубль которого вы ищете. Обратите внимание, что здесь необходимо добавлять тег Title полностью, а не только некоторые слова из него.
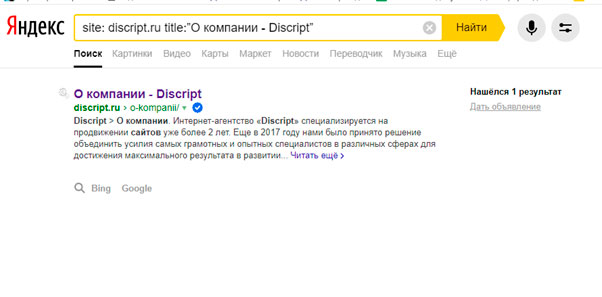
Мы видим, что дублей нет
Для Google:
site: vashdomen.ru intitle:заголовок
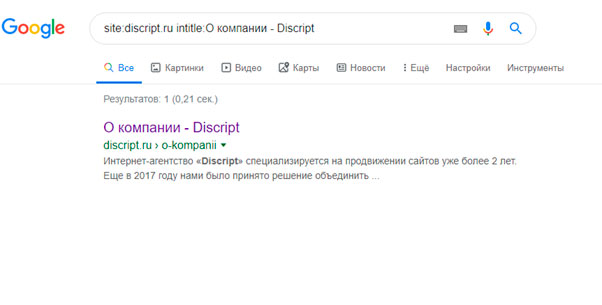
Для Яндекса и Google запрос site:vashdomen.ru inurl:prodvizhenie поможет найти прямое вхождение «prodvizhenie» в URL документов. Но ведь это еще не дубли. А чтобы найти здесь дубли, необходимо выданные поисковиком страницы просмотреть вручную.
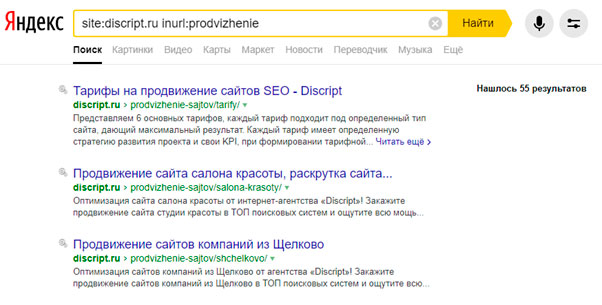
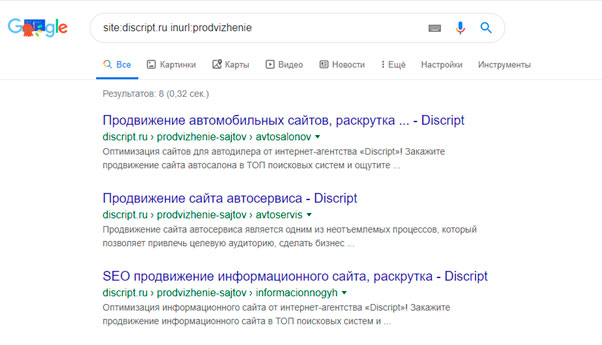
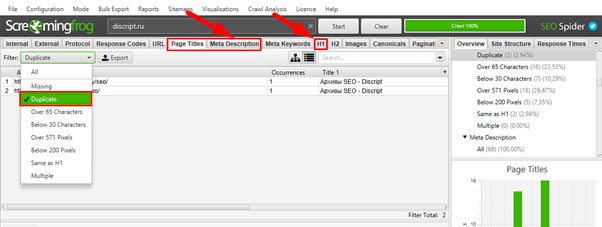
Для поиска дублей можно использовать программу Screaming Frog Seo Spider.Запуская паука на сайт, программа выгружает полный список адресов, который потом можно отсортировать по совпадению тегов description и title и таким образом выявить возможные дубли.
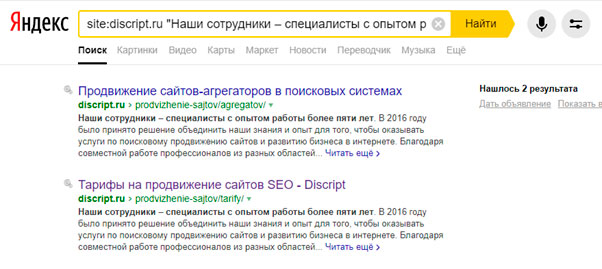
Дубли можно искать также по контенту.
Представленный способ помогает найти неуникальный контент. При этом в title и мета-теги могут быть частично уникальными.Чтобы выявить на сайте подобные страницы, подойдет цитатный поиск или поиск части текста. Для этого нужно ввести запрос: site:vashdomen.ru “текст” и совершить поиск на сайте по части текста страниц. Сам текст при этом вводится в кавычках. Это нужно для того, чтобы найти страницы с точно таким же порядком и формой слов, как в запросе. При этом поиск будет произведен только в рамках сайта. Если же необходимо найти дубли по всему интернету, то оператор “site” указывать не нужно. В таком случае запрос будет иметь вид: «Фраза с проверяемой страницы».
Найти частичные дубли можно, используя сервис https://seoto.me. Результат будет выглядеть таким образом:
Что делать дальше?
Когда на сайте найдены дубли, остается решить, что именно с ними делать. Здесь также может быть несколько вариантов. Но перед тем, как удалить дубли страниц нужно понять, почему они появились, т.к. простое удаление может не решить проблему в целом, а значит через время появятся новые дубли по тем же причинам.
Специально для этого был введен атрибут rel=«canonical». Сегодня его понимает и Гугл, и Яндекс. Такой вариант считается лучшим для страниц сортировок, пагинации, фильтров, utm- страниц и клонирования одной позиции в нескольких списках.
Можно запретить индексацию дублей в файле «robots.txt».
Для этого нужно использовать директиву Disallow, которая запрещает поисковому роботу индексацию определенных разделов или типов страниц. Такой способ хорошо подходит для дублей, частично повторяющих контент основных страниц.

Стоит отметить, что, если страница указана в robots.txt с директивой Disallow, то в Google документ все равно может оказаться в выдаче. Например, если она была проиндексирована раньше или на нее есть ссылки. Инструкции robots.txt носят рекомендательный характер для поисковых роботов и не могут дать гарантии удаления дублей.
Для того, чтобы удалить дубли страниц, созданные вручную, нужно сперва проанализировать трафик, который идет на них, определить наличие внешних и внутренних ссылок, а также наличие документов в индекс. Если документа в индексе нет, то его можно удалять с сайта. Если же страницы есть в поисковой базе, то нужно оценить, сколько поискового трафика они дают, сколько внутренних и внешних ссылок на них проставлено и после этого выбрать наиболее полезную. Далее нужно настроить 301- редирект со старой страницы на актуальную и поправить ссылки на релевантные.
Однако лучше всего постараться не допускать появления дублей, т.е. проводить своевременную профилактику. Для этого необходимо найти и устранить уже имеющиеся полные дубли, после чего:
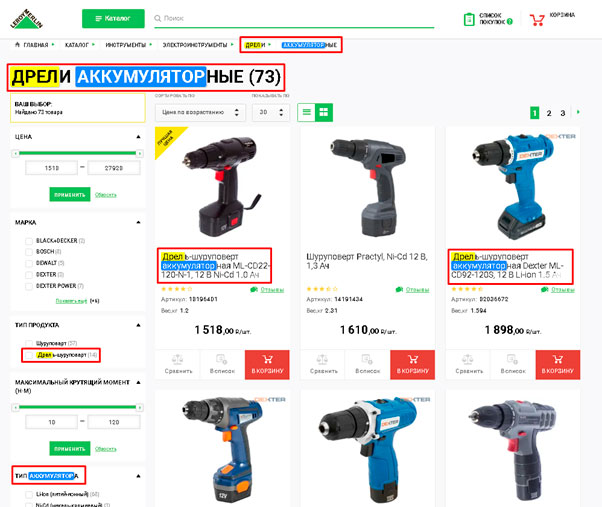
В случае использования шаблонной оптимизации каждая страница будет иметь уникальные вхождения за счет переменной, которая является ключом для нее:
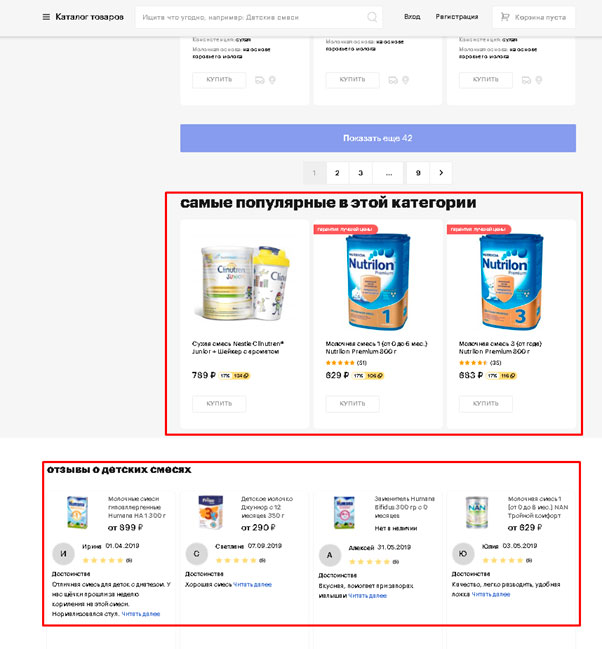
Использование UGC контента подразумевает уникализацию страниц путем выведения уникальных фрагментов. Это могут быть отзывы, которые оставляют сами пользователи, видео обзоры и т.д.
Например, отзывы на странице: https://goods.ru/catalog/detskie-smesi/
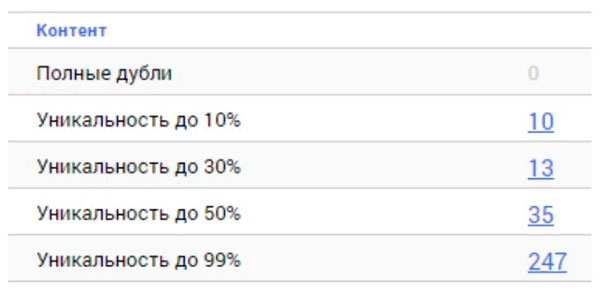
Как массово проверить уникальность страниц между собой?
Вопрос определения дубликатов страниц и уникальности текстов внутри сайта является одним из важнейших в списке работ по техническому аудиту. От наличия дублей страниц зависит как общее самочувствие сайта, так и распределение краулингового бюджета поисковых систем, возможно расходуемого впустую, да и в целом ранжирование сайта может испытывать трудности из-за большого числа дублированного контента.

И если для проверки уникальности отдельных текстов в интернете можно легко найти большое количество сервисов и программ, то для проверки уникальности группы определенных URL между собой подобных сервисов существует немного, хотя сама по себе проблема является важной и актуальной.
Какие варианты проблем с не уникальным контентом могут быть на сайте?
1. Одинаковый контент по разным URL
Обычно это страница с параметрами и та же самая страница, но в виде ЧПУ (человеко-понятный УРЛ).
Данная проблема легко решается любым веб-краулером, которой сравнив все страницы сайта, обнаружит, что у двух из них одинаковые хеш-коды (MD5), и сообщит об этом оптимизатору, которому останется поставить задачу, все тому же программисту, на установку 301 редиректов на страницы с ЧПУ.
Однако не все бывает так однозначно.
2. Частично совпадающий контент
Подобный контент образуется, когда мы имеем разные страницы, но, по сути, с одинаковым или схожим содержанием.
Пример 1
На сайте по продаже пластиковых окон, в новостном разделе, копирайтер год назад написал поздравление с 8 марта на 500 знаков и дал скидку на установку пластиковых окон в 15%.
А в этом году контент-менеджер решил «схалтурить», и не мудрствуя лукаво, нашел ранее размещенную новость со скидками, скопировал ее, и заменил размер скидки с 15 на 12% + дописал от себя 50 знаков с дополнительными поздравлениями.
Таким образом, в итоге мы имеем два практически идентичных текста, схожих на 90%, которые сами по себе являются нечеткими дубликатами, одному из которых по хорошему требуется срочный рерайт.
При этом, для сервисов технического аудита данные две новости будут разными, так как ЧПУ на сайте уже настроены, и контрольные суммы у страниц не совпадут, как ни крути.
В итоге, какая из страниц будет ранжироваться лучше – большой вопрос…
Но новости они такие – имеют свойство быстро устаревать, поэтому возьмем пример поинтереснее.
Пример 2
У вас на сайте есть статейный раздел, либо вы ведете личную страничку по своему хобби / увлечению, например это «кулинарный блог».
И, к примеру, в вашем блоге набралось уже порядком статей за все время, более 100, а то и вовсе несколько сотен. И вот вы подобрали тему и написали новую статью, разместили, а впоследствии каким-то образом обнаружилось, что аналогичная статья уже была написана 3 года назад. Хотя, казалось бы, перед написанием контента вы пробежались по всем названиям, открыли Excel со списком размещенных тем, но не учли, что прошлое содержимое статьи «Как приготовить горячий шоколад в домашних условиях» сильно совпадает с только что написанным материалом. А при проверке этих двух статей в одном из онлайн-сервисов получается, что они уникальны между собой на 78%, что, конечно же, не хорошо, так как из-за частичного дублирования возникает канибализация поисковых запросов между этими страницами, а у поисковой системы возникают вопросы и сложности при ранжировании подобных дублей.
Само собой, каждый копирайтер после написания статьи должен проверять ее на уникальность в одном из известных сервисов, а каждый СЕОшник обязан проверять новый контент при размещении на сайте в тех же сервисах.
Но, что делать, если к вам только-только пришел сайт на продвижение и вам нужно оперативно проверить все его страницы на дубли? Либо, на заре открытия своего блога вы написали кучу однотипных статей, а теперь, скорее всего из-за них сайт начал проседать. Не проверять же руками 100500 страниц в онлайн сервисах, добавляя на проверку каждую статью руками и затрачивая на это уйму времени.
BatchUniqueChecker
Именно для этого мы и создали программу BatchUniqueChecker, предназначенную для пакетной проверки группы URL на уникальность между собой.
Принцип работы BatchUniqueChecker прост: по заранее подготовленному списку URL программа скачивает их содержимое, получает PlainText (текстовое содержимое страницы без блока HEAD и без HTML-тегов), а затем при помощи алгоритма шинглов сравнивает их друг с другом.
Таким образом, при помощи шинглов мы определяем уникальность страниц и можем вычислить как полные дубли страниц с 0% уникальностью, так и частичные дубли с различными степенями уникальности текстового содержимого.
В настройках программы есть возможность ручной установки размера шингла (шингл – это количество слов в тексте, контрольная сумма которых попеременно сравнивается с последующими группами внахлест). Мы рекомендуем установить значение = 4. Для больших объемов текста от 5 и выше. Для относительно небольших объемов – 3-4.
Значимые тексты
Помимо полнотекстового сравнения контента, в программу заложен алгоритм «умного» вычленения так называемых «значимых» текстов.
То есть, из HTML-кода страницы мы получаем только лишь контент, содержащийся в тегах H1-H6, P, PRE и LI. За счет этого мы как бы отбрасываем все «не значимое», например, контент из меню навигации сайтов, текст из футера либо бокового меню.
В результате подобных манипуляций мы получаем только «значимый» контент страниц, который при сравнении покажет более точные результаты уникальности с другими страницами.
Список страниц для их последующего анализа можно добавить несколькими способами: вставить из буфера обмена, загрузить из текстового файла, либо импортировать из Sitemap.xml с диска вашего компьютера.
Программа BatchUniqueChecker бесплатна, занимает всего 4 Мб в архиве и не требует установки.
Таким образом, благодаря многопоточной работе, проверка сотни и более URL может занять всего несколько минут, на что в ручном режиме, через онлайн-сервисы, мог бы уйти день или более.
Все это поможет существенно сэкономить время сео-специалиста на поиск дубликатов и облегчить анализ качества текстов внутри вашего сайта.