Машинное обучение: прогнозируем цены акций на фондовом рынке
Как с помощью нейронных сетей предсказывать цены акций на фондовой бирже ― рассказываем в а даптированной статье инженера Кембриджского университета Вивека Паланиаппана.

Коммерческий автор и переводчик
Машинное и глубокое обучение стали новой эффективной стратегией, которую для увеличения доходов используют многие инвестиционные фонды. В статье я объясню, как нейронные сети помогают спрогнозировать ситуацию на фондовом рынке — например, цену на акции (или индекс). В основе текста мой проект, написанный на языке Python. Полный код и гайд по программе можно найти на GitHub. Другие статьи по теме читайте в блоге на Medium.
От редакции. Статья не для новичков. Чтобы применить модель, нужно знать основы Python, теорию вероятности, статистику и моделирование данных. Необходимые знания можно получить на онлайн-курсе «Data Scientist» в Нетологии.
Нейронные сети в экономике
Изменения в сфере финансов происходят нелинейно, и иногда может показаться, что цены на акции формируются совершенно случайным образом. Традиционные методы временных рядов, такие как модели ARIMA и GARCH, эффективны, когда ряд является стационарным — его основные свойства со временем не изменяются. А для этого требуется, чтобы ряд был предварительно обработан с помощью log returns или приведён к стационарности по-другому. Однако главная проблема возникает при реализации этих моделей в реальной торговой системе, так как при добавлении новых данных стационарность не гарантируется.
Решением такой проблемы могут быть нейронные сети, которые не требуют стационарности. Нейронные сети изначально очень эффективны в поиске связей между данными и способны на их основе прогнозировать (или классифицировать) новые данные.
Обычно проект Data Science состоит из следующих операций:
 Сбор данных — обеспечивает набор необходимых свойств.
Сбор данных — обеспечивает набор необходимых свойств.
 Предварительная обработка данных — часто пугающий, но необходимый шаг перед использованием данных.
Предварительная обработка данных — часто пугающий, но необходимый шаг перед использованием данных.
 Разработка и реализация модели — выбор типа нейронной сети и её параметров.
Разработка и реализация модели — выбор типа нейронной сети и её параметров.
 Модели бэктестинга (тестирование на исторических данных) — ключевой шаг любой торговой стратегии.
Модели бэктестинга (тестирование на исторических данных) — ключевой шаг любой торговой стратегии.
 Оптимизация — поиск подходящих параметров.
Оптимизация — поиск подходящих параметров.
Входные данные для нашей нейронной сети — данные о ценах на акции за последние 10 дней. С их помощью мы спрогнозируем цены на следующий день.
Сбор данных
К счастью, необходимые для этого проекта данные можно найти на Yahoo Finance. Данные можно собрать, используя их Python API pdr.get_yahoo_data(ticker, start_date, end_date или напрямую с сайта.
Предварительная обработка данных
В нашем случае данные нужно разбить на обучающие наборы, состоящие из десяти прошлых цен и цены следующего дня. Для этого я определил класс Preprocessing, который будет работать с обучающими и тестовыми данными.
Внутри класса я определил метод get_train(self, seq_len), который преобразовывает обучающие входные и выходные данные в NumPy массивы, задавая определённую длину окна (в нашем случае 10). Весь код выглядит так:
Аналогично я определил метод, который преобразовывает тестовые данные X_test и Y_test.
Прогнозирование фондового рынка с использованием нейронных сетей

В современном мире всё с большей остротой проявляется интерес к качественному прогнозированию финансовых рынков. Это связано с быстрым развитием высоких технологий и, соответственно, с появлением новых инструментов анализа данных. Однако тот технический анализ, которым привыкли пользоваться большинство участников рынка, не эффективен. Прогнозы на основе экспоненциальных скользящих средних, осцилляторах и прочих индикаторах не дают ощутимый результат, т.к. экономика часто бывает иррациональна, потому что движима иррациональными мотивациями людей.
В последние годы, у финансовых аналитиков стали вызывать большой интерес так называемые искусственные нейронные сети – это математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей – сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге при мышлении, и при попытке смоделировать эти процессы. Впоследствии эти модели стали использовать в практических целях, как правило, в задачах прогнозирования. Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения – одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение. Способности нейронной сети к прогнозированию напрямую следуют из ее способности к обобщению и выделению скрытых зависимостей между входными и выходными данными. После обучения сеть способна предсказать будущее значение некой последовательности на основе нескольких предыдущих значений и/или каких-то существующих в настоящий момент факторов. Следует отметить, что прогнозирование возможно только тогда, когда предыдущие изменения действительно в какой-то степени предопределяют будущие. Например, прогнозирование котировок акций на основе котировок за прошлую неделю может оказаться успешным, тогда как прогнозирование результатов завтрашней лотереи на основе данных за последние 50 лет почти наверняка не даст никаких результатов.
Рассмотрим на практике применение метода прогнозирования с помощью нейронных сетей. Для примера возьмём данные индекса ММВБ в период с 01.10.2008 по 03.04.2009. Задача состоит в том, что на основе представленной статистической информации необходимо сделать прогноз на 10 дней. Как видно из графика (рис.1), с 01.10.08 по 28.10.08 индекс ММВБ «просел» примерно на 534 пункта. После чего последовал рост до максимальной отметки в 871 пункт. Далее, некоторое время, рынок находился в боковом тренде, затем наметилась восходящая тенденция. В данном примере будем строить прогноз для одной переменной (остальные аналогично), но для того, чтобы выбрать ту из четырех переменных, которая наиболее сильно поможет спрогнозировать остальные, построим корреляционную матрицу.
Итак, построив матрицу парных корреляций (табл.1), делаем вывод о том, что переменная LOW наиболее сильно коррелирует с остальными. Займёмся прогнозом данной переменной.
Нелинейные по своей сути нейронные сети, позволяют с любой степенью точности аппроксимировать произвольную непрерывную функцию, не взирая на отсутствие или наличие какой-либо периодичности или цикличности. Поскольку временной ряд представляет собой непрерывную функцию (на самом деле нам известно значение этой функции лишь в конечном числе точек, но её можно легко непрерывно продолжить на весь рассматриваемый отрезок), то применение нейронных сетей вполне оправдано и корректно.
Построим тысячу нейронных сетей различной конфигурации в пакете STATISTICA, обучим их, а затем выберем десять наилучших.
В результате идентификации процесса построения сетей мы получили следующие результаты: выбранные сети, как можно заметить, имеют различные конфигурации (табл.2).
В результате обучения была найдена нейронная сеть, соответствующая модели 7 (рис.2) с хорошей производительностью (регрессионное отношение: 0,253628, ошибка: 0,003302). Нетрудно заметить, что производительность сетей с архитектурой Радиально Базисной Функции (РБФ) в среднем хуже производительности сетей с архитектурой Многослойно персептрона. Во многом это объясняется тем, что сети с архитектурой РБФ плохо экстраполируют данные (это связано с насыщением элементов скрытой структуры). Для оценки правдоподобности модели 7 построим гистограмму частот (рис.3). Данная гистограмма является самой симметричной по сравнению с другими моделями. Это подтверждает стандартные предположения о нормальности остатков. Следовательно, модель 7 больше всего подходит для данного временного ряда.
Осуществим проекцию для прогнозирования временного ряда. В результате имеем прогноз (рис.4, табл.3). Как видно из графика, нейронная сеть верно спрогнозировала направление тренда. Однако, требовать от этого метода анализа более точных данных, особенно в период мирового экономического кризиса как минимум некорректно.
Как и предполагалось, нейронные сети дали хороший результат. Во многом это обусловлено сложностью и нелинейностью структуры данного ряда, тогда как классические методы рассчитаны на применение к рядам с более заметными и очевидными структурными закономерностями. Но даже, несмотря на все видимые положительные качества нейронных сетей не стоит считать их некоей «панацеей». Во-первых, нейронные сети являются «черным ящиком», который не позволяет в явном виде определить вид зависимостей между членами ряда. Таким образом, конкретную нейронную сеть можно «научить» строить прогноз лишь на строго фиксированное количество шагов вперед (которое мы указываем в спецификации этой сети), следовательно, имеет место сильная зависимость от вида задачи. Во-вторых, при наличии явной линейности, простоты структуры в задаче, способность нейронных сетей к обобщению оказывается более слабой по отношению к классическим методам. Объясняется это как раз нелинейностью сетей по своей сути.
В общем случае для достижения наилучшего результата необходимо использовать нейронные сети вкупе с грамотной стратегией управления капиталом.
Список использованной литературы:
1. Э.А.Вуколов. Основы статистического анализа. Издательство «Форум», Москва
2008г.
2. В. Боровников. STATISTICA: искусство анализа данных на компьютере. 2003г.
3. Недосекин А.О. Нечетко-множественный анализ риска фондовых инвестиций. Изд.
Сезам, 2002г.
Ранее статья публиковалась в материалах 3-ей региональной научной конференции ВолгГТУ в 2009 году (Том 3).
Машинное обучение: прогнозируем цены акций на фондовом рынке
Переводчик Полина Кабирова специально для «Нетологии», адаптировала статью инженера Кембриджского университета Вивека Паланиаппана о том, как с помощью нейронных сетей создать модель, способную предсказывать цены акций на фондовой бирже.
Машинное и глубокое обучение стали новой эффективной стратегией, которую для увеличения доходов используют многие инвестиционные фонды. В статье я объясню, как нейронные сети помогают спрогнозировать ситуацию на фондовом рынке — например, цену на акции (или индекс). В основе текста мой проект, написанный на языке Python. Полный код и гайд по программе можно найти на GitHub. Другие статьи по теме читайте в блоге на Medium.
Нейронные сети в экономике
Изменения в сфере финансов происходят нелинейно, и иногда может показаться, что цены на акции формируются совершенно случайным образом. Традиционные методы временных рядов, такие как модели ARIMA и GARCH эффективны, когда ряд является стационарным — его основные свойства со временем не изменяются. А для этого требуется, чтобы ряд был предварительно обработан с помощью log returns или приведён к стационарности по-другому. Однако главная проблема возникает при реализации этих моделей в реальной торговой системе, так как при добавлении новых данных стационарность не гарантируется.
Решением такой проблемы могут быть нейронные сети, которые не требуют стационарности. Нейронные сети изначально очень эффективны в поиске связей между данными и способны на их основе прогнозировать (или классифицировать) новые данные.
Обычно data science проект состоит из следующих операций:
Сбор данных
К счастью, необходимые для этого проекта данные можно найти на Yahoo Finance. Данные можно собрать, используя их Python API pdr.get_yahoo_data(ticker, start_date, end_date) или напрямую с сайта.
Предварительная обработка данных
Модели нейронных сетей
Для проекта я использовал две модели нейронных сетей: Многослойный перцептрон Румельхарта (Multilayer Perceptron — MLP) и модель Долгой краткосрочной памяти (Long Short Term Model — LSTM). Кратко расскажу о том, как работают эти модели. Подробнее о MLP читайте в другой статье, а о работе LSTM — в материале Джейкоба Аунгиерса.
MLP — самая простая форма нейронных сетей. Входные данные попадают в модель и с помощью определённых весов значения передаются через скрытые слои для получения выходных данных. Обучение алгоритма происходит от обратного распространения через скрытые слои, чтобы изменить значение весов каждого нейрона. Проблема этой модели — недостаток «памяти». Невозможно определить, какими были предыдущие данные и как они могут и должны повлиять на новые. В контексте нашей модели различия за 10 дней между данными двух датасетов могут иметь значение, но MLP не способны анализировать такие связи.
Для этого используется LSTM или Рекуррентные нейронные сети (Recurrent Neural Networks — RNN). RNN сохраняют определенную информацию о данных для последующего использования, это помогает нейронной сети анализировать сложную структуру связей между данными о ценах на акции. Но с RNN возникает проблема исчезающего градиента. Градиент уменьшается, потому что количество слоев повышается и уровень обучения (значение меньше единицы) умножается в несколько раз. Решают эту проблему LSTM, увеличивая эффективность.
Реализация модели
Важный этап работы с ценами на акции — нормализация данных. Обычно для этого вы вычитаете среднюю погрешность и делите на стандартную погрешность. Но нам нужно, чтобы эту систему можно было использовать в реальной торговле в течение определенного периода времени. Таким образом, использование статистики может быть не самым точным способом нормализации данных. Поэтому я просто разделил все данные на 200 (произвольное число, по сравнению с которым все другие числа малы). И хотя кажется, что такая нормализация ничем не обоснована и не имеет смысла, она эффективна, чтобы убедиться, что веса в нейронной сети не становятся слишком большими.
Начнем с более простой модели — MLP. В Keras строится последовательность и поверх неё добавляются плотные слои. Полный код выглядит так:
С помощью Keras в пяти строках кода мы создали MLP со скрытыми слоями, по сто нейронов в каждом. А теперь немного об оптимизаторе. Популярность набирает метод Adam (adaptive moment estimation) — более эффективный оптимизационный алгоритм по сравнению с стохастическим градиентным спуском. Есть два других расширения стохастического градиентного спуска — на их фоне сразу видны преимущества Adam:
AdaGrad — поддерживает установленную скорость обучения, которая улучшает результаты при расхождении градиентов (например, при проблемах с естественным языком и компьютерным зрением).
RMSProp — поддерживает установленную скорость обучения, которая может изменяться в зависимости от средних значений недавних градиентов для веса (например, насколько быстро он меняется). Это значит, что алгоритм хорошо справляется с нестационарными проблемами (например, шумы).
Adam объединяет в себе преимущества этих расширений, поэтому я выбрал его.
Теперь подгоняем модель под наши обучающие данные. Keras снова упрощает задачу, нужен только следующий код:
Когда модель готова, нужно проверить её на тестовых данных, чтобы определить, насколько хорошо она сработала. Это делается так:
Информацию, полученную в результате проверки, можно использовать, чтобы оценить способность модели прогнозировать цены акций.
Для модели LSTM используется похожая процедура, поэтому я покажу код и немного объясню его:
Обратите внимание, что для Keras нужны данные определенного размера, в зависимости от вашей модели. Очень важно изменить форму массива с помощью NumPy.
Модели бэктестинга
Когда мы подготовили наши модели с помощью обучающих данных и проверили их на тестовых, мы можем протестировать модель на исторических данных. Делается это следующим образом:
Однако, это упрощенная версия тестирования. Для полной системы бэктестинга нужно учитывать такие факторы, как «ошибка выжившего» (survivorship bias), тенденциозность (look ahead bias), изменение ситуации на рынке и транзакционные издержки. Так как это только образовательный проект, хватает и простого бэктестинга.
Прогноз моей модели LSTM на цены акций Apple в феврале
Для простой LSTM модели без оптимизации это очень хороший результат. Он показывает, что нейронные сети и модели машинного обучения способны строить сложные устойчивые связи между параметрами.
Оптимизация гиперпараметров
Для улучшения результатов модели после тестирования часто нужна оптимизация. Я не включил её в версию с открытым исходным кодом, чтобы читатели могли сами попробовать оптимизировать модель. Тем, кто не умеет оптимизировать, придется найти гиперпараметры, которые улучшат производительность модели. Есть несколько методов поиска гиперпараметров: от подбора параметров по сетке до стохастических методов.
Я уверен, с оптимизацией моделей знания в сфере машинного обучения выходят на новый уровень. Попробуйте оптимизировать модель так, чтобы она работала лучше моей. Сравните результат с графиком выше.
Вывод
Машинное обучение непрерывно развивается — каждый день появляются новые методы, поэтому очень важно постоянно обучаться. Лучший способ для этого — создавать интересные проекты, например, строить модели для прогноза цен на акции. И хотя моя LSTM-модель недостаточно хороша для использования в реальной торговле, фундамент, заложенный при разработке такой модели, может помочь в будущем.
Можно ли прогнозировать цену ценных бумаг нейронной сетью?

Когда рассматривается задача прогнозирования временных рядов нейронной сетью у читателя (слушателя, зрителя, …) часто возникает идея о том, что можно же сетью прогнозировать и цену акций, обретя возможность узнать, когда стоит докупить, а когда продать. Временами даже встречаются работы, в которых описывается, как именно можно нейронной сетью прогнозировать этот самый курс акций. Примером здесь может быть работа[1], там авторы приводят даже некоторые результаты. А вот в книге Ф. Шолле “Глубокое обучение на Python”[2], имеется вполне недвусмысленное предупреждение о том, что не стоит пытаться пытаться использовать машинное обучение для предсказаний курсов ценных бумаг. Шолле объясняет это тем, что в случае рынка, данные о прошлом состоянии являются плохой основой для предсказания будущего состояния. В работе [3]авторы вообще приходят к выводу, что курс ценных бумаг это мартингал (в математическом смысле этого слова), и наилучшим прогнозом (с точки зрения величины ошибки прогноза) его будущего состояния является его текущее состояние.
Так можно ли нейронной сетью прогнозировать курс ценных бумаг? Попробуем ответить на вопрос с разных точек зрения.
Теория
Предупреждение: нижеследующее объяснение выражает мое собственное представление о предмете, может использовать некорректные термины, быть в корне неверным и вообще. Так что если вы, дорогой читатель, понимаете в предмете больше меня, то рискуете умереть от смеха. Я предупредил.
Что такое акция? Акция это ценная бумага, которая удостоверяет право её держателя на получение части прибыли предприятия. Уже из одного этого следует, что цена акции должна быть связана с прибылью предприятия. Более того, цена связана не столько с фактической прибылью предприятия, сколько с ожидаемой прибылью, то есть цена выражает мнение рынка о том, какой будет эта прибыль. А мнение может быть ошибочным. Мы помним историю стартапа Theranos, который утверждал, что у них есть революционная технология анализа ДНК чуть ли не по одной капле крови, а потом оказалась, что точность анализа сопоставима с тычками пальцем в небо. Таким образом, цена акции зависит от субъективного мнения инвесторов о компании.
Посмотрим на рисунок ниже. На нём график изменения цены акций компании Maersk. Как видим, 2 апреля 2019 акция стоила 7718 DKK, а на следующий день — уже 7750. Почему? Причиной тому маленькая буква D внизу графика. 3 апреля выплачивались дивиденды, и, видимо, сумма была обещана хорошая, раз инвесторы начали скупать акции. То есть, к росту цен привело некоторое приближающееся событие.

Теперь посмотрим на ещё один график. Это курс акций нашего Яндекса в те дни, когда в сеть просочились слухи о том, что Сбербанк собирается его купить. Обычно, на таких слухах цена акций как раз резко взлетает (ну ещё бы, компания-покупатель будет выкупать акции с рынка и всем хочется, чтобы акции выкупили именно у него…), но в этот раз инвесторы, видимо, решили, что покупка частного Яндекса государственным Сбербанком не несёт ничего хорошего.
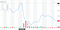
По мнению специалистов Отдела Небеснопальцевого Метода Познания НИИ Банальных Исследований, отсюда следует довольно простой вывод: цена акций зависит, в первую очередь, от мнения инвесторов о будущем компании, а не от её текущего состояния, и уж тем более не от текущей цены на акции как таковой. Поэтому прогнозировать будущую цену на основе текущей (или нескольких предыдущих) не имеет смысла.
Прогнозировать что-то нужно на основе того, от чего это что-то действительно зависит. В случае цен на акции нужно учитывать это внешние события, которые вряд ли удастся предсказать нейронной сетью. То, что разорившихся трейдеров больше, чем тех, кто заработал целое состояние, как бы намекает на то, что и человек не всегда может предсказать будущее изменение цен.
Практика
Как известно, в теории теория и практика неразделимы, но на практике это не так. Попробуем что-нибудь спрогнозировать, и посмотрим, что получится.
Мы будем обучать нейронную сеть, которая по (n) ценам предскажет (n+1)-ю. При этом мы предполагаем, что время между двумя последовательными замерами одинаково. Для начала, нам потребуется набор данных, то есть те самые цены, брать данные мы будем с Yahoo Finance.
Для начала попробуем прогнозировать изменение цен по дням, то есть, каждому дню у нас будет соответствовать одна величина. Мы будем прогнозировать цену закрытия на основе нескольких цен закрытия за предыдущие дни, а в качестве подопытного будет выступать Maersk.
Как им пользоваться можно ознакомится тут. Теперь обратимся к бирже:
Подробно прочитать про функцию history и то, какие параметры она принимает, и какие константы поддерживаются для параметров period и interval можно тут.
Итак, запросим данные:
Теперь в переменной history у нас данные о ценах в виде pandas DataFrame, посмотрим на них подробнее:

Итак, Keras даёт нам TimeseriesGenerator, его и будем использовать для получения обучающих данных. Подробнее об этом генераторе — по ссылке. Проблема здесь в том, что мы хотим учитывать ещё и выплату дивидендов, так как, как мы обнаружили, что она влияет на цену. Напишем функцию, которая сгенерирует нам обучающую выборку. Аргументами этой функции будут набор данных и количество входных сигналов, нужное для получения одного прогноза. Мы не будет сейчас делить данные на пакеты, мы только расширим каждую строку признаком того, будут ли выплачиваться дивиденды. Мы воспользуемся классом TimeseriesGenerator чтобы получить один большой массив обучающих данных, сгенерированный с использованием скользящего окна.
Функция принимает два параметра: набор данных, преобразование которого нужно выполнить ( data ) и количество значений цены закрытия, на основе которых будем выполнять прогнозирование ( value_num ).
Мы упомянули пакеты, так что стоит пояснить, что это вообще такое. Обучение нейронной сети выполняется градиентным методом, который требует вычисления градиента функции потерь (отсюда и название). Самым простым является метод градиентного спуска. Классический подход предполагает, что градиент функции потерь вычисляется для всей обучающей выборки. Но тут есть недостатки. Во-первых, это может быть весьма накладно с вычислительной точки зрения — обучающая выборка может быть очень большой. Во-вторых, замечено, что при обучающих выборках очень большого размера, величина градиента может оказаться очень большой, и могут начаться проблемы с тем, что такие числа просто не помещаются в их машинное представление. Второе, конечно, имеет смысл в самых крайних случаях. Знающие люди отмечают, что нам, на самом деле, не очень-то и нужно точное значение градиента целевой функции[4]. Нам нужна оценка того, в какую сторону смещаться, чтобы минимизировать функцию потерь. Поэтому мы можем оценить градиент на основе некоторого подмножества обучающих примеров, чтобы определить это направление движения. Конечно, нам всё же придётся обойти все примеры, но теперь мы знаем, что нам не обязательно обрабатывать их все сразу. Мы можем разделить обучающую выборку на части равного размера (то есть на пакеты, batch) и вычислять градиент для каждого пакета отдельно, корректируя веса нейронной сети только на основе такого, “частичного”, градиента. После того, как обработали все пакеты, можно считать, что завершили одну эпоху обучения. В процессе обучения эпох может быть несколько, их количество зависит от задачи и самого хода обучения. Те же знающие люди также отмечают, что примеры должны быть распределены по пакетам случайно[4], то есть если два примера в обучающей выборке расположены друг за другом, они не должны попасть в один пакет, или, во всяком случае, должны быть расположены в ином порядке и не друг за другом.
Итак, проверим нашу функцию и сгенерируем обучающие данные, исходя из того, что для получения прогноза достаточно 4-х значений.
Посмотрим на один пакет обучающих примеров.
Как видим, это вектор, последний элемент которого указывает на то, будут ли выплачены дивиденды в тот день, для которого выполняется прогнозирование.
Мы видим, что величина значений цен довольно высока. Действительно, цена закрытия изменяется в интервале \(<767.7, 12740.0>\) что говорит о том, что нужно нормализовать значения. Воспользуемся методом нормализации MinMax.
Мы нормализуем исходные данные, так что обучающую выборку нужно сгенерировать снова.
Посмотрим на нормализованные данные.
Пришло время, наконец, собрать сеть и обучить её. Итак, наша сеть будет иметь (N+1) вход и один выход. Входы соответствуют замерам цены акции, а также содержат признак того, что в целевой день выплачиваются дивиденды, а выход соответствует цене закрытия для целевого дня. Величину N, число значений, на основе которых прогнозируется результат, нам предстоит определить. Поэтому напишем функцию, которая будет генерировать нам сети с разным числом входов. Мы используем конструкцию n+1 чтобы добавить вход, отвечающий за дивиденды.
Прежде чем переходить непосредственно к обучению, разделим обучающую выборку на две части. Первую часть будем использовать для обучения, а вторую — для тестирования, и никогда не будем использовать ни один элемент тестовой выборки при обучении. Это позволит нам понять, как наша сеть обрабатывает данные, который ей не были известны на этапе обучения.
Ура, наконец-то создаём сеть:
Напишем функцию, которая позволит нам выбрать, какое число входов даёт наилучший результат. На вход функции подадим минимальное и максимальное число входов, которые нужно проверить и количество эпох, в течение которых нужно обучать сеть. Функция обойдёт интервал, заданный минимальным и максимальным числом входов, создаст сеть, обучит её и протестирует. В результате мы сможем сравнить, какая сеть показала лучший результат.
Теперь обучим сети, меняя число входов от 2 до 10 и обучая в течения 20 эпох.
Дождавшись окончания процесса, получим краткую информацию о результатах. Для каждой сети получим её размер и значения ошибки обучения и тестирования на последней эпохе.
Как видим, значение ошибки при тестировании всегда несколько больше, чем при обучении. Это нормально и говорит о том, что незнакомые данные сеть обрабатывает несколько хуже, чем известные.
Построим график зависимости ошибки при тестировании в зависимости от количества входов.
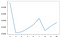
Итак, из графика видно, для какого числа входов мы получили наименьшую ошибку. Результат может меняться в зависимости от того, сколько данных уже накопилось. То есть, чем больше времени пройдёт с момент написания этих строк, тем больше шансов, что результат поменяется.
Кстати, любопытное наблюдение: если запустить этот скрипт два раза подряд, то мы с высокой вероятностью получим разные результаты. То есть для разных запусков минимальную ошибку покажут разные сети. Так как сети отличаются только числом входов, то такая изменчивость результатов говорит о том, что результат прогноза мало зависит от количества входов. Это, в свою очередь, подтверждает изначальный тезис о том, что сетью не получится прогнозировать цену акций. Мы видим, что сеть учится минимизировать ошибку не используя звсе входы, вероятно, приходя к выводу, выход не зависит ото всех входов.
Нужно помнить, что это ошибка не для цены акции, а для нормализованной цены акции. Попробуем вычислить фактическую погрешность, “разнормализовав” ошибку. Получим значение фактической ошибки для всей сетей.
Нехилая ошибка, даже для того числа входов, где мы получаем наименьшую ошибку, фактическое значение погрешности велико. Я бы не стал вкладывать куда-то, если прогноз результата имеет такую ошибку. И другим бы не советовал.
Посмотрим на график самого предсказания. Красным здесь обозначено ожидаемое значение, а синим — предсказание.
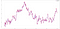
Вот тут можно посмотреть тот же график, но большего размера. Можно увеличить и посравнивать. Нетрудно увидеть, что линии совпадают нечасто.
Выводы
Мы получили большое значение ошибки для незнакомых данных. Это говорит о том, что наша сеть не справилась с задачей и не смогла предсказать цену закрытия для акций. Возможно, можно повысить точность результата, поменяв архитектуру сети или увеличив число эпох. Собрать больше данных вря д ли получится, так как мы и так использовали данные за всё время торгов, потому расширять диапазон некуда. Обучать сеть на данных от нескольких компаний, вероятно, не самая удачная идея, так ак курс акций разных компаний может изменяться по разным законам, и смешение их в один набор данных вряд ли приведёт к чему-то полезному.
Следует помнить, что наша нейронная сеть на самом деле не прогнозирует цену ценных бумаг как таковую. Вместо этого она пытается предположить, каким будет следующее значение временного ряда, на основе нескольких известных значений. Это связано с тем, что цена акций не кодирует никаким образом как она будет изменятся в следующий момент. То, что цена росла на протяжении какого-то времени не означает, что она не упадёт в следующий момент. На цену в гораздо большей мере влияют внешние события, которые нейронная сеть не прогнозирует, чем цена за предыдущее время.
Возможно, сеть можно было бы использовать для кратковременных прогнозов, чтобы понять поведение курса в течение нескольких минут, исходя из предположения, что чем меньше временной промежуток, для которого мы прогнозируем, тем меньше шансов, что за него успеет произойти внешнее событие, которые повлияет на цену. Однако есть подозрения, что для таких прогнозов лучше использовать линейную регрессию, а не нейронную сеть.
Если посмотреть на график изменения цены с течением времени, то можно увидеть, что график похож на случайный. Возможно, это не так далеко от истины, если мы имеем только сами цены и не знаем о внешних событиях. То есть, для нейронной сети цена действительно может выглядеть как мартингал, то есть [почти] непрогнозируемый временной ряд. Так что здесь я согласен с Ф. Шолле по поводу того, что нейронной сетью курс акций лучше не прогнозировать.
Если уж очень хочется заработать не за счёт вдумчивого чтения финансовой отчётности, а за счёт математического анализа биржевых показателей, то стоит посмотреть на Quantitative Analysis. Говорят, работает.