Предиктивные технологии один из элементов цифровизации производства

В индустриальном секторе России запускают пилотные проекты по предиктивному обслуживанию. Первые модели уже работают на металлургических заводах и энергоблоках генерирующих компаний, по итогам 2017 года объем рынка оценивается в 100 млн долларов США.
За счет PdM промышленники намерены сократить сроки простоя оборудования и повысить эффективность своих мощностей. Предиктивные технологии являются одним из элементов цифровизации производства. Какие компании разрабатывают предиктивные технологии? Какие барьеры мешают рынку стремительно развиваться?
Оптимизация ошибок
В промышленности набирает популярность новый цифровой сервис «предиктивное обслуживание» (predictive maintenance, PdM). Услуга внедряется для сбора и анализа информации о состоянии оборудования, для прогнозирования сроков ремонтных работ и предотвращения сбоев производства.
В отличие от традиционного профилактического обслуживания, прогнозирование строится за счет массивов данных, цифровых моделей, а не благодаря усредненной статистике. В числе основных компонентов PdM — сбор и обработка текущей информации, раннее обнаружение неисправностей и ошибок, оптимизация ресурсов.
По данным Markets and Markets, мировой рынок предиктивного обслуживания в 2020 году достигнет 1,9 млрд долларов США (против 582 млн в 2015 году). Ключевые игроки в мире — General Electric, Siemens, ABB, Emerson, IBM, SAS, Schneider Electric и другие.
Прогноз для индустрии
В России предиктивная аналитика пока что на стартовых позициях: по экспертным оценкам, рынок по итогам 2017-го года составил 100 млн долларов США, через год показатель может вырасти до 200 млн. В последнее время индустриальный сектор все активнее применяет PdM.

По словам директора направления интеллектуальных приложений компании «Цифра» (входит в ГК «Ренова») Константина Горбача, задачи предиктивного техобслуживания актуальны для клиентов, использующих сложное и дорогое оборудование. Это отрасли, где выход из строя элемента влечет существенные потери и угрожает безопасности: ТЭК, металлургия, нефтехимия, транспорт. Раннее выявление неполадок позволяет предотвращать аварии и сокращать затраты.
« Система удаленного мониторинга и прогностики повышает прозрачность эксплуатации оборудования для менеджмента »,— уточнил технический директор системы прогностики состояния оборудования «ПРАНА» АО «РОТЕК» Максим Липатов.
Стоимость внедрения PdM на предприятиях формируется по-разному: затраты на пилотные проекты могут составить сумму в несколько миллионов рублей, промышленное внедрение — от несколько сотен миллионов.
« За последние два года интерес к прогнозной аналитике в России вырос. На нашем рынке основные игроки — это «РОСТЕК» с системой «ПРАНА», Datadvance, Сlover Group и компании-интеграторы. В нашей практике были и пилотные проекты за 10 млн рублей, и промышленные внедрения за 1 млн долларов США »,— рассказал гендиректор Datadvance Сергей Морозов.
Защита для гигаватта
В 2017 году к PdM подключились энергетические компании. Например, холдинг «Т Плюс» подписал контракт с «РОТЕК» по внедрению системы прогностики «ПРАНА» на 16 энергоблоках. «РОТЕК» подключает к собственному ситуационному центру турбины, котлы-утилизаторы и дожимные компрессоры генерирующей компании. За счет такого решения менеджмент энергетики планируют сократить ремонтные затраты и сроки простоя оборудования, находить конструктивные дефекты оборудования заблаговременно.
« Десять электростанций компании будут защищены от технологических рисков. Это важнейший шаг на пути к масштабной цифровизации энергетики: общая мощность подключаемого к системе «ПРАНА» оборудования превысит 3 ГВт »,— пояснил председатель совета директоров «РОТЕК» Михаил Лифшиц.
Технологию также начинают использовать металлургические группы. В золотодобывающей компании Nordgold с помощью PdM налажена система ремонта. Впрочем, некоторые практики требуют инвестиций и расходов на их поддержание в дальнейшем, отмечает менеджер по организации обслуживания горной техники компании Александр Брежнев.
Сервис стали применять на предприятии ПАО «Северсталь»— Череповецком металлургическом комбинате. На производстве запущена в работу PdM, чтобы сократить количество простоев на стане горячей прокатки 2000.

« Предиктивная модель выявляет вероятность перегрева подшипника шестеренных клетей — одну из наиболее частых и ресурсозатратных причин остановки агрегата. Это первая модель в области предиктивных ремонтов, внедренная на производстве ЧерМК в рамках реализации цифровой стратегии компании », — отмечают в пресс-службе «Северстали».
Специалисты компании разработали цифровую модель, чтобы получать данные с датчиков температуры и формировать прогноз. В случае отклонения показателей, полученных со стана, от нормы оператор получает соответствующее оповещение. Это позволяет предотвратить незапланированную остановку стана.
« Мы ожидаем, что благодаря расчетам предиктивной модели количество простоев сократится на 80%. В наших планах внедрить похожие модели для других видов отказов на стане-2000, а также на других агрегатах »,— комментирует директор по ремонтам дивизиона «Северсталь Российская сталь» Сергей Добродей.
Экономический эффект
По оценкам экспертов, PdM-сервис сейчас находится только в стадии становления в регионах РФ, заказчики пока что не осознали потенциал направления.
« Экономический эффект от внедрения предиктивного обслуживания может составить сотни миллионов рублей, если брать в расчет Газпром и РЖД »,— подсчитал директор по консалтингу компании Datalytica Алексей Шовкун.
На сегодняшний момент, отмечают разработчики, несколько барьеров мешают широко распространяться технологиям. Так, большая часть оборудования на производствах не оснащена датчиками для передачи информации, на предприятиях нет систем сбора данных и онлайн-мониторинга. К тому же на заводах часто ведут недостоверно журналы о дефектах и ремонтах. Неготовность персонала к IT-решениям и недоверие к новой концепции обслуживания сдерживают внедрение PdM-систем на промпредприятиях России.
Статьи, которые Вам могут быть интересны:




Россия открывает в Крыму медцентры Завод «ЭТЕРНО» Газопровод Турецкий поток Судостроительный комплекс «Звезда»
Предикативная аналитика: как предсказать эпидемию и успех в бизнесе

Что такое предикативная аналитика
Предикативная (или предиктивная, прогнозная) аналитика — это прогнозирование, основанное на исторических данных. С помощью статистических инструментов можно выявить закономерности в изменениях показателей в предыдущих периодах и предсказать, как они будут вести себя в будущем. Например, проанализировав котировки акций, можно просчитать обвал или изменение цен. Банки используют предикативную аналитику, когда оценивают заемщика, анализируя финансовые показатели и рассчитывая вероятность того, что клиент не сможет выплатить кредит.
Крупные компании создают целые отделы, занимающиеся предикативной аналитикой. Они преследуют разные цели — от оптимизации затрат на рекламу до повышения эффективности производства. Считается, что из всех видов бизнес-аналитики именно предикативная аналитика приносит наибольшую выгоду компаниям.
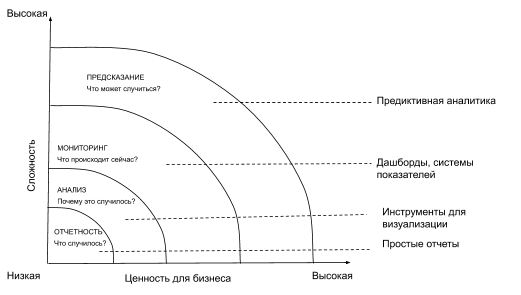
Как строится процесс
Основа прогнозной аналитики — большие данные (от англ. big data). Это огромные массивы информации, которые невозможно обработать с помощью привычных инструментов. Сейчас ИТ-компании предлагают готовые программы, которые анализируют большие данные и визуализируют их в виде дашбордов — наглядных таблиц, графиков и отчетов. Самый актуальный дашборд на сегодняшний день был создан центром системных наук и инжиниринга Университете Джона Хопкинса. Он демонстрирует количество заболевших коронавирусом во всех странах.
Большие данные появляются постоянно — их генерируют компании, устройства и мы сами, когда пользуемся смартфонами и компьютерами, делаем покупки и путешествуем. Кроме того, они легко собираются и оцифровываются: например, если раньше мы покупали продукты на рынках и расплачивались наличными, то теперь чаще оплачиваем товары банковскими картами или делаем заказы в интернет-магазине.

Распространенные примеры данных:
Если перечисленные источники уже можно назвать «классическими», то в последние годы компании научились обрабатывать менее очевидные данные: зарплаты игроков американского футбола, содержание фильмов и географические координаты ударов молнии.
Построение прогноза состоит из нескольких этапов:
Предикативная аналитика не может быть точной на 100%. Иначе, например, биржа не имела бы смысл — каждый мог бы предсказать, как поведут себя те или иные акции. В реальности на каждый бизнес-показатель влияет множество факторов, но точность предикативной модели можно повышать, работая над качеством данных и обучая ее.
Примеры применения предикативной аналитики
Компании анализируют историю покупок и текущую активность клиента. Если по итогам анализа покупатель попадает в сегмент тех, кто потенциально может перейти к конкурентам, то ему могут предложить скидку, бонусы или подарок.

HR-специалисты используют предикативную аналитику, чтобы заранее выявить, кто из работников уволится, кто из кандидатов на вакансию преуспеет, сколько позиций нужно открыть в следующем году, сколько сотрудников воспользуются разными опциями медицинской страховки и т.д. Google использует ее, чтобы сохранить кадры — если аналитика предсказывает, что ценный работник скоро уйдет из компании, ему предлагают повышение или другую должность.
Анализируя данные об использовании оборудования, можно определить, когда оно будет нуждаться в профилактическом ремонте. Так, в феврале Mail.ru Group объявила, что создаст для «Сухого» цифровую платформу предикативной аналитики. Данные о работе промышленного оборудования и параметрах выполнения операций позволят прогнозировать исправность станков и осуществлять их своевременное обслуживание.
В этой сфере прогнозная аналитика используется особенно широко. Например, с ее помощью выявляются мошеннические транзакции. Банки смотрят на данные прошлых лет о нормальном поведении: расходах, обычном времени и географии транзакций. В случае аномалий организация получает уведомление и может запросить у клиента дополнительное подтверждение операции.

Прогнозная аналитика особенно эффективна в интернет-маркетинге, где легко собрать информацию и быстро внести изменения. Она помогает снизить расходы на рекламу, показать объявление, подходящее конкретному пользователю, квалифицировать посетителя сайта как будущего платящего клиента, улучшить клиентский опыт и т.д.
Специалисты сервиса BlueDot в декабре 2019 года определили, что вспышка заболевания будет именно в провинции Хубэй, опубликовав первую научную публикацию, в которой были предсказания о глобальном распространении вируса.

Бывают неожиданные области применения предикативной аналитики с искусственным интеллектом. О них рассказал технический директор Redmadrobot Data Lab Алексей Соколов:
«Системы, построенные на машинном обучении, стремительно развиваются. Основная «пища» для алгоритмов такого рода — это данные и вычислительные мощности, и их становится все больше. Через пять лет машинные алгоритмы будут пронизывать все вокруг точно также, как электричество, — добавляет Алексей Соколов. — Скорее всего, государства научатся корректно регулировать интеллектуальные технологии, беспилотные автомобили станут нормой, а в медицине произойдут прорывы, которые позволяют людям жить дольше».
Подписывайтесь и читайте нас в Яндекс.Дзене — технологии, инновации, эко-номика, образование и шеринг в одном канале.
Предиктивная аналитика на пальцах
Я занимаюсь Data Science и Machine Learning в компании Redmadrobot. Нас знают в основном как разработчика мобильных приложений, но практика DS и ML в роботах тоже развита.
Например, мы делаем предиктивную аналитику: это такой класс методов Data Science, с помощью которого можно предсказать какие-то важные для клиента показатели в будущем. В этой статье я на пальцах объясню, как работает предиктивная аналитика и как именно она помогает, например, просчитать выручку и сэкономить деньги.
К нам приходит, скажем, владелец большой розничной сети с вполне конкретным запросом: хочу знать, где открыть новую точку и сколько выручки я с нее получу. Реально ли это? Вполне.
Сначала мы смотрим, какие данные уже есть у заказчика. Их еще называют внутренними данными.
У магазина обычно уже есть какие-то данные по существующим точкам: ассортимент, товарооборот, площадь торгового зала и так далее. Используя только эти данные, мы можем обучить модель и попытаться предсказать, например, выручку для каждой точки: для этого мы делим существующие данные в пропорции 70/30, обучаем модель на 70% данных, а на оставшихся 30% проверяем, насколько точно наша модель научилась предсказывать выручку для точки.
Проблема в том, что точность такой модели может быть невысокой: ей просто не хватает данных для обучения. Другими словами, если у нас есть только внутренние данные от магазинов, этого может быть недостаточно, чтобы с приличной точностью предсказать, сколько магазин будет выручать за месяц.
Что делать в этом случае? Обогащать данные, то есть дополнять то, что уже есть у клиента, внешними данными.
Внешних данных бывает огромное множество.
Погода, курсы валют, график запуска ракет SpaceX — все это внешние данные по отношению к нашему клиенту.
Понятно, что не все внешние данные нам нужны, и не все из них мы можем достать. На этом этапе к нам подключается аналитик: он хорошо разбирается в типах и источниках внешних данных, и может дать экспертную оценку, какие из них будут релевантны. Перед разработкой модели проводится исследование, которое помогает понять, какие данные нам будут полезны, а какие нет.
В случае с магазином нам могут быть полезны, например, такие данные, как проходимость конкретной точки, какие конкуренты стоят рядом, сколько денег выручают торговые точки в этом районе.
На основе этих гипотез мы можем подтянуть внешние данные и обучить модель, уже используя их. Предсказательная сила в этом случае обычно улучшается. Мы можем обучать модель несколько раз, добавляя и убирая какие-то наборы данных, добиваясь все большей точности.
Некоторые сервисы-агрегаторы данных отдают их свободно, иногда даже в удобном формате xml или json — как, например, сервис OpenStreetMap, где можно получить географические данные об объекте. Бывают публичные базы данных, например от Google — это уже собранные большие наборы данных по различным тематикам, которые можно найти в открытом доступе и свободно использовать для обучения своей модели.
Некоторые данные находятся в открытом доступе, но их неудобно использовать. Тогда приходится парсить сайты, то есть вытаскивать данные в автоматическом режиме (до тех пор, пока это законно, конечно — но в большинстве случаев это законно).
А некоторые данные приходится покупать или договариваться об их использовании — например, если работать с операторами фискальных данных, которые могут разрешить использовать некоторую информацию о чеках.
В каждом случае мы решаем, насколько нам нужны эти данные, насколько они повысят точность модели и насколько это важно для заказчика. Предположим, какой-то набор данных позволит нам сделать модель на 10% точнее. Насколько это хорошо для заказчика? Сколько денег он сэкономит или получит, если предсказания нашей модели будут на 10% точнее? Стоит ли это того, чтобы покупать этот набор данных? Чтобы понимать это, нам нужно действительно много знать про клиента — поэтому на этапе понимания задачи мы задаем много вопросов про его бизнес, источники прибыли и особенности работы.
Как проверить (и доказать клиенту), что наша модель действительно имеет смысл? Что она предсказывает результат с нужной нам вероятностью?
Делим все данные, которые у нас есть, случайным образом в пропорции 80/20. С 80% мы будем работать и обучать на них модель, это наша тренировочная выборка. 20% пока отложим — они нам понадобятся позже, чтобы проверить на них модель и убедиться, что все работает. Это валидационная выборка.
Тренировочную выборку делим на обучающую и тестовую выборки (70/30). На 70% обучаем модель. На 30% проверяем. Когда точность нас устраивает — проверяем модель теперь уже окончательно, на валидационной выборке, то есть на тех данных, которые модель никогда не видела. Это позволяет нам убедиться, что модель действительно предсказывает с заданной точностью.
Как правило, точность модели на тестовой и валидационной выборке почти совпадает. Если они сильно отличаются — скорее всего, дело в данных: возможно, они были поделены на обучающую и валидационную выборки не случайным образом, либо данные неоднородны.
Когда мы обсуждаем с клиентом задачу, мы среди прочего определяем с ним критерии успешности проекта. Как понять, что мы выполнили задачу? Какая точность должна быть у получившейся модели и почему именно такая?
Проект мы всегда начинаем с MVP — это относительно дешевая проверка наших гипотез, это модель, которая уже может приносить ценность. Пробуем обучать модель на имеющихся данных и находим некий baseline — минимальную точность модели (например, 75%). Эту точность мы будем все время стараться повышать — до тех пор, пока это рентабельно и имеет смысл.
Когда точность модели нас наконец устраивает, мы упаковываем получившуюся модель в веб-сервис или мобильное приложение с удобным интерфейсом. В нашем примере с открытием магазина и прогнозированием его выручки веб-сервис мог бы выглядеть как интерактивная карта, где разные районы подсвечивались бы разными цветами в зависимости от перспективности открытия магазина здесь, а для каждой выбранной точки отрисовывалась бы плашка с прогнозом выручки магазина, поставленного в этой точке.
Отличие MVP от промышленного решения в том, что модель MVP не может дообучаться. А точность любой модели со временем деградирует, и ее надо дообучать. Поэтому для промышленного решения мы реализуем один из двух вариантов поддержки: либо мы поддерживаем ее самостоятельно, постоянно дообучая модель (и увеличивая ее точность), либо реализуем цикл переобучения модели непосредственно внутри самого софта.
Поддержка со стороны живой команды, конечно, дороже. Но минус автоматического переобучения в том, что оно не может учесть внезапных изменений характера данных. Оно не учтет, например, что в результате каких-нибудь санкций магазин перестал продавать определенные типы товаров и его выручка снизилась. Тогда точность модели сильно упадет, и ее надо будет переобучать вручную, добавляя недостающие данные.
1. Веб-сервис или мобильное приложение с удобным интерфейсом, которое наглядно показывает клиенту ответ на его вопрос (например, где открывать магазин и сколько у него будет выручки).
2. Под капотом — модель, которая с заданной (и оговоренной) точностью выдает предсказания на основе имеющихся данных — внутренних данных клиента и внешних данных, которые мы приняли решение собирать и использовать в этой модели.
3. Поддержку модели, реализованную либо как постоянные доработки модели со стороны живой DS-команды, либо как встроенная функция периодического переобучения внутри самой программы. Модель поддержки выбирается в зависимости от характера данных и бизнес-задач, которую решает модель.
4. Наглядное подтверждение тому, что Data Science и Machine Learning — не просто модные технологии, а инструменты, которые помогают быстро и точно решать реальные задачи бизнеса.
Предиктивная аналитика в маркетинге: где применяется, какой эффект можно получить
Сегодня мы начинаем цикл статей о предиктивной аналитике – современном инструменте прогнозирования продаж и маркетинга. Например, COVID-19 вызвал волну прогнозов: уровень заражения, убытки на фондовом рынке, проблемы цепочки поставок и производства. У этого списка нет конца. Практически невозможно просматривать новости, не увидев еще одного предсказания о том, как мы переживем «новую реальность». Хорошая новость заключается в том, что в неопределенные времена прогнозы могут помочь нам принимать более правильные решения и планировать будущее. В бизнес-аналитике и маркетинге этот процесс называется «предиктивной аналитикой».
Эффективный маркетинг всегда заключался в распознавании и предвидении потребностей клиентов. Прогнозный маркетинг включает в себя все инструменты, процессы и правила для применения предиктивной аналитики на основе искусственного интеллекта к стратегиям продаж и маркетинга. Он работает путем сбора и анализа данных о клиентах из растущего списка источников данных, включая CRM-системы, опросы, каналы социальных сетей и другие платформы взаимодействия с клиентами. Эти знания затем применяются ко всему маркетинговому процессу, охватывающему все этапы взаимодействия с клиентом и каждый канал коммуникации бренда, чтобы определить будущие риски и возможности. Компании, успешно внедрившие предиктивную аналитику вместе с технологией машинного обучения, понимают, что только сбор и хранение данных не даст никаких действенных идей для эффективных продаж и маркетинга.
Вот некоторые из областей, в которых машинное обучение и предиктивная аналитика окажут серьезное влияние:
— Снижение затрат. По мере того, как жизненный цикл клиента становится короче и усложняется, внедрение прогнозной аналитики и технологий машинного обучения поможет компаниям проводить более эффективные маркетинговые кампании, что приведет к сокращению расходов и увеличению доходов.
— Перспективное планирование. Бизнес-организации могут внедрять прогнозную аналитику, чтобы получить представление о будущем успехе своих новых продуктов и/или услуг. Это особенно полезно, когда доступных исторических данных недостаточно для прогнозирования или когда прошлое не указывает на будущее. Прогнозная аналитика помогает компаниям принимать обоснованные решения без учета прошлого опыта.
В упрощенном виде предиктивная аналитика работает в маркетинге через регрессионный анализ. При регрессионном анализе аналитик берет две переменные и рассчитывает коэффициент регрессии, чтобы определить шансы того, что клиент купит продукт. Например, можно использовать уровень дохода и спрос на продукт для расчета коэффициента регрессии. Если между двумя переменными существует сильная связь, это указывает на то, что уровень дохода является важным фактором спроса на продукцию. Можно построить анализ на множестве переменных, учитывая совокупность факторов влияния на определенный признак (например, как возраст и доход влияют на размер среднего чека).
Также возможно исключить неэффективные процессы и уменьшить отток. Вы можете лучше понять клиентов и разработать маркетинговые кампании, которые не позволят им уйти. Также появляется возможность автоматизировать маркетинговые процессы, чтобы сократить расходы и сэкономить время.
Предиктивная аналитика определяет новые маркетинговые возможности с помощью трех различных моделей:
— Совместная фильтрация: предиктивная аналитика может предугадывать тип продуктов и услуг, которые клиент, скорее всего, купит, на основе истории покупок. Таким образом, предоставляется хорошая возможность для допродажи и перекрестных продаж. Цифровые гиганты, такие как Amazon и Netflix, используют совместную фильтрацию для продажи дополнительных продуктов и услуг.
— Кластерная модель: с помощью этой модели вы можете разделить клиентскую базу на разные нишевые сегменты на основе любой переменной, такой как возраст, уровень дохода, демографические данные и средний объем заказа. Существует несколько различных кластерных моделей, включая кластеризацию на основе бренда, кластеризацию на основе продукта и кластеризацию по поведению.
Более детально мы рассмотрим предиктивную аналитику в следующих публикациях.
Прогнозирование осуществляется с помощью пакета SPSS.