Полнотекстовый поиск по сайту — бич современного интернета
Реализация хорошего поиска по сайту — часто сильно недооцененная по сложности задача. Поиск является слабым местом сайтов настолько часто, что когда я вижу строку поиска, у меня сразу же возникает предвзятое ощущение предстоящего фиаско. И чтобы лишний раз не расстраиваться, я сразу переадресую свой вопрос гуглу или яндексу и быстро нахожу то, что требовалось. Что же делать, чтобы как-то улучшить эту ситуацию?
Форма поиска по сайту от Яндекса и Гугла
Качество поиска
Для начала нужно понять, из чего вообще складывается понятие качества поиска. Качество поиска зависит от многих факторов. О многих из них можно прочитать в книге известного поискового оптимизатора кандидата технических наук Игоря Ашманова. (Скажу по секрету, что недавно видел её на torrents.ru). Все факторы условно можно разбить на три категории: полнота, точность и ранжирование.
Полнота
Причина этого чаще всего в том, что на большинстве сайтов реализован поиск только по динамическим данным из-за того, что поисковая программа получает данные из базы данных. Более того, обычно вебмастер (или создатель CMS) решает, какие таблицы в БД самые важные, а какие недостойны внимания. В результате «за бортом» поиска остаются некоторые «малозначимые» динамические данные и все статические страницы.
С другой стороны, если поставить целью обеспечение максимальной полноты поиска, то в результатах может оказаться много «мусорных» и дублирующихся страниц, что тоже негативно сказывается на лояльность пользователей.
Точность
Точность поиска — это характеристика соответствия найденных страниц поисковому запросу. В неё входят учет морфологии, снятие омонимии, учет опечаток, поиск по синонимам и др. Например, если пользователь ищет «количество голов Аршавина», то ясно, что головы тут ни при чем, и нужно показывать только информацию про забитые голы. Вот еще один интересный пример омонимии. Но это высший пилотаж, а самое простое, что хочет увидеть пользователь — это поиск по всем возможным словоформам.
Полнотекстовый поиск и его возможности
Многие СУБД поддерживают методы полнотекстового поиска (Fulltext search), которые позволяют очень быстро находить нужную информацию в больших объемах текста.
В отличие от оператора LIKE, такой тип поиска предусматривает создание соответствующего полнотекстового индекса, который представляет собой своеобразный словарь упоминаний слов в полях. Под словом обычно понимается совокупность из не менее 3-х не пробельных символов (но это может быть изменено). В зависимости от данных словаря может быть вычислена релевантность – сравнительная мера соответствия запроса найденной информации.
В статье рассказывается как работать с полнотекстовым поиском на примере БД MySQL, а так же приведу примеры «нестандартного» использования данного механизма.
В MySQL возможности полнотекстового поиска (только для MyISAM-таблиц) поддерживаются начиная с версии 3.23.23. В последующих версиях механизм потерпел существенные доработки и расширения, в тоге превратившись в мощное средство для создания поисковых механизмов веб-приложений. Главная особенность – быстрый поиск слов в очень больших объемах текстовой информации.
Индекс FULLTEXT
Итак, чтобы работать с полнотекстовым поиском, сначала нам нужно создать соответствующий индекс. Он называется FULLTEXT, и может быть наложен на поля CHAR, VARCHAR и TEXT. Причем, как и в случае с обычным индексом – если происходит поиск по 2-м полям, то нужен объединенный индекс 2-х полей, используйте поиск по одному полю – нужен индекс только этого поля. Например:
CREATE TABLE `articles` (
`id` int(10) unsigned NOT NULL auto_increment,
`title` varchar(200) default NULL,
`body` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `ft1` (`title`,`body`),
FULLTEXT KEY `ft2` (`body`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
В этом примере создается таблица с 2-мя полнотекстовыми индексами: ft1 и ft2, которые можно использовать для поиска в полях title и body, или только в body. Только в поле title искать не получится.
Конструкция MATCH-AGAINST
Собственно для самого полнотекстового поиска в MySQL используется конструкция MATCH(filelds)… AGAINST(words). Она может работать в различных режимах, которые достаточно сильно между собой отличаются. Для всех действует следующее правило: данная конструкция возвращает условную релевантность, но способ вычисления которой может быть разным в зависимости от режима. Еще стоит добавить что во всех режимах поиск всегда регистрозависимый. Далее более подробно о каждом из них.
MATCH-AGAINST IN NATURAL LANGUAGE MODE
— это основной вид поиска, который используется по умолчанию, т.е. если режим не указан:
SELECT * FROM `articles` WHERE MATCH (title,body) AGAINST (‘database’);
В этом примере мы ищем слово database в полях title и body таблицы articles на основе индекса ft1 (см. пример создания таблицы выше). Выборка будет автоматически отсортирована по релевантности – это происходит в случае указания конструкции MATCH-AGAINST внутри блока WHERE и не задано условие сортировки ORDER BY.
Кстати, несмотря на возможности алиасов, при запросах конструкцию приходится повторять в разных местах, что усложняет запросы. Вот например нельзя написать так:
SELECT *, MATCH (title,body) AGAINST (‘database’) as REL
FROM `articles`
WHERE REL > 0;
— этот запрос выдаст ошибку: поле Rel не определено. Что бы работало, придется продублировать данную конструкцию:
SELECT *, MATCH (title,body) AGAINST (‘database’) as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST (‘database’) > 0;
Однако, сколько бы вы не использовали одну и туже конструкцию (разумеется с одинаковыми параметрами) она будет вычислена только один раз.
В примере выше в переменной REL будет вычислена релевантность. Эта величина зависит прежде всего от количества слов в полях tilte и body, того насколько близко данное слово встречается к началу текста, отношения количества встретившихся слов к количеству всех слов в поле и др.
Например, релевантность будет не нулевая, если слово database встретится либо в title, либо body, но если оно встретится и там и там, значение релевантности будет выше, нежели если оно два раза встретится в body.
Сама по себе релевантность ничего не определяет. Это лишь сравнительная характеристика, по которой можно сортировать результат выборки, не более того.
Еще следует заметить что для IN NATURAL LANGUAGE MODE действует так называемое «50% threshold». Это означает, что если слово встречается более чем в 50% всех просматриваемых полей, то оно не будет учитываться, и поиск по этому слову не даст результатов.
MATCH-AGAINST IN BOOLEAN MODE
В бинарном режиме, в отличие от других режимов, релевантность вычисляется несколько иначе — как условная мера совпадения заданного шаблона. Положение искомого шаблона в тексте, количество встретившихся вариантов роли не играют.
Самая важная особенность бинарного режима – возможность указания логических операторов. Сами операторы я приводить не буду, о них хорошо рассказано в оригинальной документации по MySQL.
Еще особенностями бинарного режима является отсутствие автоматической сортировки в случае указания условия WHERE, однако для сортировки можно использовать алиас:
SELECT *,
MATCH (title,body) AGAINST (‘+database MySQL’ IN BOOLEAN MODE) as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST (‘+database MySQL’ IN BOOLEAN MODE)
ORDER BY REL;
Пример выведет все записи содержащие слово database, но если в записи присутствует слово MySQL, то его релевантность будет выше. Записи будут отсортированы по релевантности.
В бинарном режиме отсутствует ограничение «50% threshold». Бинарный режим можно использовать и без создания полнотекстового индекса, однако это будет работать очень медленно.
MATCH-AGAINST IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
Или просто «WITH QUERY EXPANSION». Работает примерно также, как NATURAL LANGUAGE MODE, с той лишь разницей, то в результат поиска попадают не только совпадения с шаблоном, но и возможные логические совпадения. Это работает примерно так:
Сначала MySQL выполняет запрос аналогичный NATURAL LANGUAGE MODE и формирует результат. По этому результату производится попытка вычислить слова, которые так же имеют высокую релевантность для полученной выборки. В случае, если эти слова присутствуют производится поиск и по ним тоже, но значение их на релевантность будет существенно ниже. Отдается смешанная выборка – сначала те результаты, где слово присутствует, а потом те, которые были получены в результате «повторного» поиска.
WITH QUERY EXPANSION не рекомендуется использовать для больших объемов информации, так как в результат может попасть очень много лишнего.
Использование FULLTEXT SEARCH
Пара слов об алгоритмах поиска
Соответственно, с поисковым запросом надо сделать тоже самое. Режим поиска используется любой – как удобнее… А вообще поиск – это отдельная тема, про которую нужна отдельная статья.
Раскрытие связок многое-ко-многим
В некоторых случаях – не во всех – с помощью полнотекстового поиска можно раскрывать соотношения многое-ко-многим без привлечения третьей таблицы.
Допустим, у нас есть две большие таблицы: с пользователями и группами пользователей. Причем, каждый пользователь имеет отношение к большому количеству различных групп, в свою очередь группы включают в себя большое количество пользователей. При нормальном соотношении (т.е. раскрытии через 3-ю таблицу), что бы выбрать все группы, которые принадлежат к некоторому пользователю понадобиться сделать запрос, объединяющий 2 или 3 таблицы, что даже при присутствии индексов очень накладно.
Однако можно выполнить денормализацию по следующей схеме: 
Теперь, что бы выбрать группы, принадлежащие к пользователю 2 можно сделать:
SELECT *
FROM `groups`
WHERE MATCH (groups) AGAINST (‘+user2’ IN BOOLEAN MODE);
Это будет работать намного быстрее, чем исходный вариант (с 3-ей таблицей). Аналогично с группами, но если подобные выборки нам в принципе не нужны, то можно обойтись без соответствующего поля в таблице групп. Тогда получится что-то вроде «односторонней» связи M:N. То есть можно вычислить все M, которые принадлежат к N, не нельзя сделать обратного.
В этом случае, как правило, используется IN BOOLEAN MODE.
— Кстати, на эту схему очень хорошо ложится тегирование информации, но там не все так просто и это опять же отдельная тема.
Использование релевантности как меры отношения одного объекта к другому
Один из алгоритмов для вычисления статей, «похожих» на данную статью. Всё просто: берутся теги данной статьи, и делается полнотекстовый запрос по полю с тегами всех остальных статей с сортировкой по релевантности (если она нужна). Естественно, сначала вылезут те, которые содержат максимальное совпадение по тегам.
Можно и без учета тегов. Если статьи индексированы для полнотекстового поиска, из индекса выбираются с десяток наиболее употребляемых слов, после чего делается поиск по ним.
Или вот еще пример – интересы пользователей. Используя точно такую же схему можно легко найти других пользователей, у которых интересы наиболее соответствуют вашим.

Что такое полнотекстовый поиск?
Вы вряд ли получите какие-либо результаты поиска, если поисковые системы будут искать записи данных по точному совпадению. Например, приведенный ниже оператор SQL вряд ли вернет какие-либо записи, потому что, вероятно, не существует такого продукта с названием или описанием, точно таким же, как текстовая фраза «canned food with fish and tomato» в названии или описании.
Это может немного помочь, если мы будем использовать подстановочный знак «LIKE%», но вы будете получать только те записи, которые содержат точную текстовую фразу в полях данных.
Идея полнотекстового поиска состоит в том, чтобы разбивать текстовые фразы на токены. Текстовая фраза в приведенном выше примере разбита на следующие токены: «консервы», «еда», «с», «рыба», «и» и «помидоры». Затем поисковые системы ищут все записи, соответствующие любому из токенов. Чем больше токенов соответствует записи, тем больше она релевантна текстовой фразе. Следовательно, поисковые системы указывают на релевантность, выставляя оценку в результатах поиска. Вы можете получить результат поиска с огромным количеством записей, если токены в строке запроса содержат общие слова, такие как «еда», и многие продукты могут соответствовать одному или нескольким токенам. Однако вы всегда можете отфильтровать результат по баллам, чтобы получить наиболее релевантные записи.
Короче говоря, и MySQL, и Elasticsearch разделяют схожие идеи полнотекстового поиска. Он предназначен для создания индексов путем разложения текстового содержимого на токены. Затем запрос разбивает текст запроса на токены и сопоставляет его с индексами. На основе результата сопоставления поисковые системы вычисляют оценку и присваивают результату поиска, который представляет релевантность.
Напротив, дизайн Elasticsearch легко настраивается. Процесс декомпозиции токена и выполнения запроса выполняется на основе набора анализаторов, токенизаторов и фильтров. Эти компоненты можно настроить и собрать вместе, чтобы реализовать более сложные функции.
У меня будет пошаговое руководство по использованию полнотекстового поиска в MySQL и Elasticsearch.
Образец набора данных
Демонстрация функций полнотекстового поиска основана на образце набора данных, который представляет собой набор записей библиотечной книги. Схема довольно проста со следующими столбцами: id, title и publishingPlace.

MySQL
Выполните приведенные ниже операторы SQL, чтобы создать таблицу библиотечной книги и импортировать образцы данных.
MySQL нуждается в настройке индекса для полнотекстового поиска, выполните приведенную ниже инструкцию, чтобы создать полнотекстовый индекс для ‘title’ и ‘publishingPlace’, предполагая, что читатели заинтересованы в поиске книг на основе этих двух полей данных.
Elasticsearch
Все операции CRUD в Elasticsearch выполняются с помощью вызовов REST API. Чтобы загрузить тот же набор записей образцов книги в Elasticsearch, запустите команду curl ниже, которая отправляет запрос POST для массовой вставки данных.
Простой поиск по ключевым словам
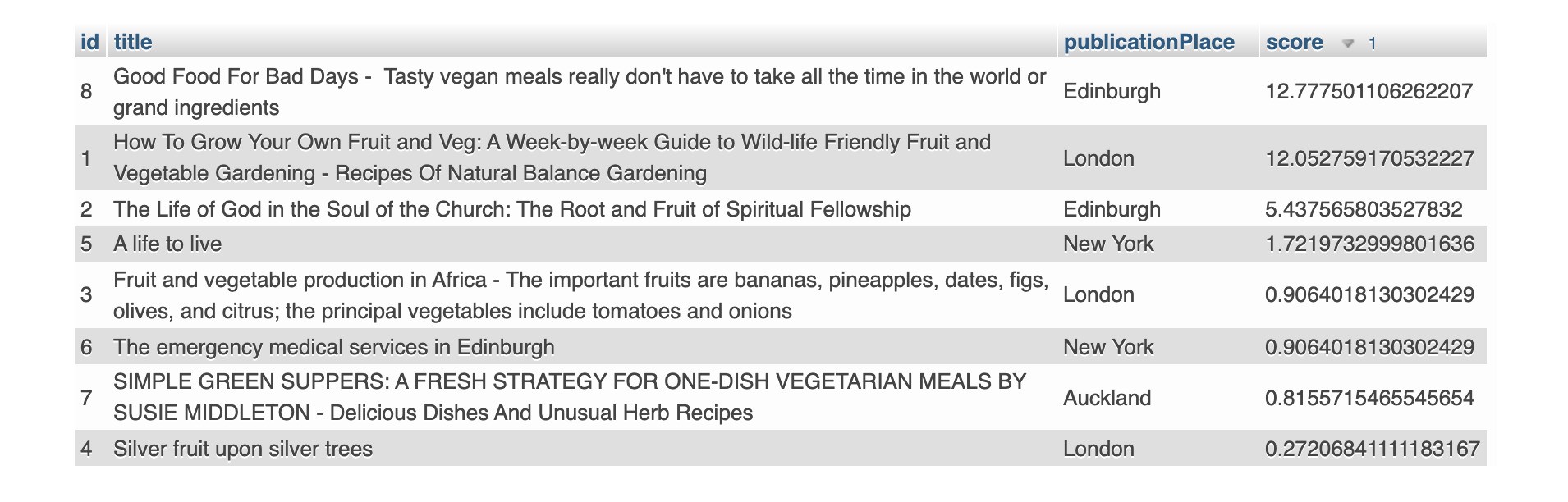
Начнем с простого поиска, допустим, мы ищем одно ключевое слово «edinburgh».
MySQL
Чтобы найти все записи, соответствующие этому ключевому слову, используйте match() в MySQL для выполнения полнотекстового запроса в логическом режиме. Запустите этот оператор SQL, чтобы найти «edinburgh».
Результат поиска присваивает каждой записи оценку, чтобы показать актуальность. Чем выше оценка, тем больше запись релевантна ключевому слову. Есть 3 записи с оценкой > 0 как название и публикация, которые соответствуют ключевому слову «edinburgh», в то время как другие записи не соответствуют ключевому слову, поэтому присваивается НУЛЕВОЙ балл.
Elasticsearch
Результат совпадает с результатом MySQL. 3 записи соответствуют ключевому слову «edinburgh», но присвоенные оценки не совпадают из-за другого механизма расчета релевантности в Elasticsearch.
Оценка точной настройки на основе указанных полей данных
Для некоторых случаев использования определенные поля данных более важны, и совпадениям ключевых слов в этих полях следует давать более высокий балл. Хотя MySQL не предлагает такой гибкости, ее можно достичь в Elasticsearch, добавив в поле данных символ вставки «^». В приведенном здесь примере показано, что поле «заголовок» в 3 раза важнее.
Поскольку «заголовок» более важен, записи с полем «заголовок», совпадающим с ключевым словом, получают более высокий балл.
Поиск с логическими условиями
Вы можете указать определенные критерии поиска, такие как И / ИЛИ / НЕ. Скажем, мы хотим найти книги, которые соответствуют ключевым словам «life» и «live». Для этого мы добавляем символ «+» перед каждым ключевым словом, чтобы указать, что это условие «И».
MySQL
BOOLEAN режим, предоставляемый MySQL, поддерживает запросы с логическими условиями. Давайте искать книги по ключевым словам «life» и «live».
Сейчас актуальна только книга «A life to live» с оценкой > 0, а все остальные книги с оценкой = 0.

Логический режим поддерживает не только оператор AND (+), но и другие символы, такие как NOT (
), более высокую релевантность (>), более низкую релевантность (
Поиск текстовой фразы
Каков результат поиска текстовой фразы, скажем, «Recipes Of A Delicious And Tasty Meal»? Поскольку текстовая фраза разбита на лексемы в нижнем регистре «recipes», «of», «a», «delicious», «and», «tasty» и «meal». Записи соответствуют большему количеству токенов, что означает, что они более релевантны текстовой фразе.
Люди обычно набирают текстовые фразы для запросов на человеческом языке. Принимая во внимание человеческий язык, для получения точных результатов необходимо особое внимание. Например, сопоставление тех слов, которые часто встречаются в английском языке, таких как «a», «an», «of», «the» и т.д., вряд ли приведет к значимым результатам. Эти слова называются «стоп-словами», поисковые системы должны игнорировать их в запросах текстовых фраз.
MySQL
MySQL поддерживает режим естественного языка, который игнорирует «стоп-слова» и выполняет поиск без учета регистра. Запустите этот оператор запроса, чтобы найти текстовую фразу.
Первые 3 записи с наибольшим количеством очков соответствуют большинству токенов во фразе поискового текста.

Elasticsearch
Настройки индекса по умолчанию Elasticsearch не содержат таких функций, как режим естественного языка, предлагаемых MySQL.
Вы увидите другой результат, когда отправите этот POST-запрос в Elasticsearch для поиска той же текстовой фразы.
Настройки по умолчанию учитывают стоп-слова при сопоставлении и подсчете очков. В результате результат поиска с наивысшим баллом, совпадающим с большинством стоп-слов, таких как «of» и «and», по-видимому, не имеет отношения к делу.
Не беспокойтесь, Elasticsearch на самом деле является очень мощной поисковой системой, поддержка поиска на естественном языке может быть осуществлена путем настройки фильтров токенов для стоп-слов в настройках индекса.
Elasticsearch предлагает 15 токензеров и более 50 фильтров токенов, которые подходят для различных сценариев использования. Чтобы добиться полнотекстового поиска, аналогичного MySQL, достаточно просто добавить в анализатор фильтр маркеров стоп-слов. На схеме ниже показано, что анализатор состоит из следующих компонентов:
Анализатор настраивается в настройках индекса и сопоставляется с полями данных «title» и «publishingPlace».
Отправьте этот запрос PUT, чтобы создать новый индекс с названием «library-book-text-phrase» (т.е. База данных в Elasticsearch) с новой конфигурацией анализатора и сопоставлением полей.
Затем отправьте этот запрос POST для копирования данных из исходного индекса «library-book» во вновь созданный индекс «library-book-text-phrase».
Давайте запустим тот же запрос по новому индексу «library-book-text-phrase». Теперь результат имеет больше смысла.
Мощная поисковая система способна не только выполнять поиск по соответствию токенов, но также понимать ключевые слова и расширять поиск других ключевых слов с аналогичным значением. Например, ожидается, что поисковые системы должны искать записи, которые соответствуют другим аналогичным ключевым словам, таким как «timber», «lumber» и «trees», при поиске по ключевому слову «woods».
MySQL может угадать, что вы ищете, используя режим «QUERY EXPANSION».
Когда мы ищем ключевое слово «зеленый». Будут возвращены 3 записи. Поле заголовка 2-й и 3-й записи на самом деле не содержит ключевого слова «green», но поисковая система каким-то образом предполагает, что содержание этой записи имеет отношение к ключевому слову «green».

Однако результаты поиска будут содержать больше «шума», если мы добавим больше ключевых слов в критерии поиска. Практически все книжные записи попадают в текстовую фразу «a good life» при поиске в режиме расширения запроса.
Невозможно точно настроить результат поиска, если вас не устраивает точность.
Elasticsearch предлагает несколько способов выполнить расширенный поиск, аналогичный режиму расширения, поддерживаемому MySQL. Вместо того, чтобы предоставлять фиксированное решение, использование токен-фильтров позволяет реализовать расширенный полнотекстовый поиск.
Давайте посмотрим на поддержку поиска по синонимам. Мы настраиваем фильтр токенов так, чтобы он расширял поиск до синонимов. Мы используем бесплатную лексическую базу данных WordNet. В целом в нем хранится более 20 тыс. слов и сопоставление с синонимами.
Конфигурация заключается в добавлении нового фильтра токенов для синонимов, и фильтр считывает сопоставления синонимов из файла WordNet.
Чтобы включить новые настройки индекса, загрузите файл WordNet и скопируйте его в elasticsearch/config/analysis, затем отправьте этот запрос PUT, чтобы создать новый индекс под названием «library-book-synonym-wordnet».
Затем отправьте этот запрос POST для копирования данных из исходного индекса «library-book» во вновь созданный индекс «library-book-synonym-wordnet».
Теперь найдите ключевое слово «green» в новом индексе. Затем вы получите список записей, который соответствует синониму «green».
Фильтр синонимов токенов Elasticsearch с настраиваемыми сопоставлениями слов
Отправьте этот запрос PUT, чтобы создать новый индекс и настраиваемый анализатор с фильтром токенов «synonym_filter».
После копирования данных во вновь созданный индекс отправьте этот запрос POST для поиска по ключевому слову «banana». Затем вы увидите, что результат содержит все записи, соответствующие ключевому слову «fruit».
Последние мысли
И MySQL, и Elasticsearch предоставляют мощные возможности полнотекстового поиска. Если ваша система использует MySQL в качестве хранилища данных, функцию полнотекстового поиска можно быстро включить, создав полнотекстовые индексы для целевых полей данных. Решение отлично работает для большинства случаев использования, поскольку оно предлагает пользователям быстрый способ поиска ключевых слов и текстовых фраз в нескольких полях данных. Однако, когда дело доходит до точной настройки и настройки результатов поиска, в MySQL доступны ограниченные возможности. Следовательно, Elasticsearch, вероятно, является лучшим вариантом для расширенных функций и индивидуального поведения поиска, поскольку решение легко настраивается и гораздо более гибкое.
2 лайфхака: альтернативы классическому поиску в Microsoft SQL Server
Привет, Хабр! Наши друзья из Softpoint подготовили интересную статью про Microsoft SQL Server. В ней разбирается два практических примера использования полнотекстового поиска:

Передаю слово автору
Эффективный поиск в гигабайтах накопленных данных — своеобразный «священный Грааль» учетных систем. Все хотят его найти и обрести бессмертную славу, но в процессе поисков раз за разом выясняется, что единственного чудодейственного решения нет.
Ситуация осложняется тем, что пользователи обычно хотят искать по вхождению подстроки — где-то выясняется, что нужный номер договора «закопан» посередине комментария; где-то оператор не помнит точно фамилию клиента, зато запомнил, что зовут его «Алексей Евграфович»; где-то просто нужно опустить повторяющуюся форму собственности ПОЮБЛ и искать сразу по названию организации. Для классических реляционных СУБД такой поиск — очень плохая новость. Чаще всего такой поиск по подстроке сводится к методичному пролистыванию каждой строки таблицы. Не самая эффективная стратегия, особенно если размер таблицы дорастает до нескольких десятков гигабайт.
В поисках альтернативы часто вспоминаю про «полнотекстовый поиск». Радость от найденного решения обычно быстро проходит после беглого обзора существующей практики. Быстро выясняется, что, по народному мнению, полнотекстовый поиск:
И, пока мы глубоко не погрузились в исследование, сразу договоримся о важном условии. Механизм полнотекстового поиска умеет гораздо больше, чем обычный поиск по строке. Например, можно определить словарь синонимов и по слову «контакт» находить «телефон». Или искать слова без учета формы и окончаний. Эти опции могут оказаться очень полезными для пользователей, но в этой статье мы рассматриваем полнотекстовый поиск только как альтернативу классическому поиску по строке. То есть, искать будем только ту подстроку, которая будет задана в строке поиска, без учета синонимов, без приведения слов к «нормальной» форме и прочей магии.
Как работает полнотекстовый поиск MS SQL
Функционал полнотекстового поиска в MS SQL частично вынесен из основной службы СУБД (ближе к концу статьи мы увидим, почему это может быть крайне полезно). Для поиска формируется особенный индекс со своей структурой, непохожей на привычные сбалансированные деревья.
Важно, что для создания индекса полнотекстового поиска необходимо, чтобы в ключевой таблице существовал уникальный индекс, состоящий всего из одной колонки — именно его полнотекстовый поиск будет использовать для идентификации строк таблицы. Часто у таблицы уже есть такой индекс по Primary Key, но иногда его придется создавать дополнительно.
Заполнение индекса полнотекстового поиска происходит асинхронно и вне транзакции. После изменения строки таблицы она ставится в очередь на обработку. Процесс обновления индекса получает из строки таблицы (row) все строковые значения, «подписанные» на индекс, и разбивает их на отдельные слова. После этого слова могут быть приведены к некоей «стандартной» форме (например, без окончаний), чтобы проще было искать по формам слова. Выкидываются «стоп-слова» (предлоги, артикли и другие слова, не несущие смысла). Оставшиеся соответствия «слово-ссылка на строку» записываются в индекс полнотекстового поиска.
Получается, каждая колонка таблицы, входящая в индекс, проходит такой конвейер:
Как было сказано, процесс обновления индекса асинхронный. Из этого следует:
Практические испытания. Поиск физ. лиц по ФИО
Наполнение таблицы данными
Для экспериментов создадим новую пустую базу с одной таблицей, где будут храниться «контрагенты». Внутри поля «описание» будет строка с названием договора, где будет упоминаться ФИО контрагента. Как-то так:
«Договор с Боровик Демьян Емельянович»
«Дог. с Боровик-Романов Анатолий Авдеевич»
Да, от такой «архитектуры» хочется сразу застрелиться, но, к сожалению, такое применение «комментариев» или «описаний» нередко среди бизнес-пользователей.
Дополнительно, добавим несколько полей «для веса»: если в таблице будет только 2 колонки, простое сканирование прочитает ее за мгновения. Нам нужно «раздуть» таблицу, чтобы скан оказался долгим. Это же приближает нас и к реальным бизнес-кейсам: мы ведь в таблице храним не только «описание», но и много другой [бес]полезной информации.
Следующий вопрос — где взять столько уникальных фамилий, имен и отчеств? Я, по старой привычке, поступил как нормальный российский студент, т.е. пошёл в Википедию:
Я написал sql-скрипт, который к каждой фамилии прикрепляет случайное число имен и отчеств. 5 минут ожидания и в отдельной таблице было уже 4,5 млн. комбинаций. Неплохо! На каждую фамилию приходилось от 20 до 231 комбинации имя+отчество, в среднем получилось по 97 комбинаций. Распределение по именам и отчествам оказалось немного смещённым «влево», но придумывать более взвешенный алгоритм показалось избыточным.
Данные подготовлены, можно начинать наши эксперименты.
Настройка полнотекстового поиска
Создадим полнотекстовый индекс на уровне MS SQL. Для начала нам нужно создать хранилище для этого индекса — полнотекстовый каталог.
Каталог есть, пытаемся добавить полнотекстовый индекс для нашей таблицы… и ничего не получается.
Как я говорил, для полнотектстового индекса нужен обычный индекс с одной уникальной колонкой. Вспоминаем, что нужное поле у нас уже есть – уникальный идентификатор id. Создадим по нему уникальный кластерный индекс (хотя хватило бы и некластерного):
После создания нового индекса мы наконец-то можем добавить индекс полнотекстового поиска. Подождем несколько минут, пока индекс заполнится (помним, что он обновляется асинхронно!). Можно переходить к тестам.
Тестирование
Начнем с самого простого сценария, приближенного к реальному применению поиска. Смоделируем «просмотр списка» — выборку окна из 45 строк с отбором по маске поиска. Выполняем запрос с новым полнотекстовым индексом, засекаем время — 0 сек — отлично!
Теперь старый, проверенный поиск через «лайк». На формирование результата ушло 3 секунды. Не так уж и плохо, тотального разгрома не получилось. Может тогда и нет смысла сложно настраивать полнотекстовый поиск — всё и так отлично работает?
На самом деле, мы упустили одну важную деталь: запрос выполнялся без сортировки. Во-первых, такой запрос в паре с «выбором первых N записей» возвращает негарантированный результат. Каждый запуск может возвращать случайные N записей и нет никакой гарантии, что два последовательных запуска дадут одинаковый набор данных. Во-вторых, если мы говорим про «просмотр списка скользящим окном» — обычно это самое «окно» отсортировано по какой-либо колонке, например, по имени. Оператору ведь нужно знать, что он получит, когда перейдет к следующему «окну».
Корректируем эксперимент. Добавляем сортировку, скажем, по номеру телефона:
Полнотекстовый поиск побеждает с оглушительным счетом: 0 секунд против 172 секунд!
Если посмотреть на планы запросов, становится понятно, почему так выходит. Из-за добавления упорядочения в текст запроса, при выполнении появилась операция сортировки. Это так называемая «блокирующая» операция, которая не может завершить запрос, пока не получит весь объем данных для сортировки. Мы не можем забрать первые попавшиеся 45 записей, нам надо отсортировать весь набор данных.
И вот на этапе получения данных для сортировки происходит драматическая разница. Поиску с «like» приходится просматривать всю доступную таблицу. На это и уходит 172 секунды. А вот у полнотекстового поиска есть своя оптимизированная структура, которая сразу возвращает ссылки на все нужные записи.
Но должна же быть и ложка дёгтя? Есть такая. Как было сказано в начале, полнотекстовый поиск может искать только от начала слова. И если мы захотим найти «Ивана Поддубного» по подстроке «*дуб*», полнотекстовый поиск не покажет ничего полезного.
К счастью, для поиска по ФИО это не самый востребованный сценарий.
Поиск документа по номеру
Попробуем что-нибудь посложнее. Второй популярный вариант использования поиска – нахождение документа по части его номера. Причем, часто номер документа состоит из двух частей: буквенного префикса и собственно номера, содержащего лидирующие нули.
Никаких пробелов или служебных символов между этими частями нет. При этом, искать по полному номеру чудовищно неудобно – приходится помнить, сколько лидирующих нулей после префикса должно стоять перед началом значащей части. Получается, что полнотекстовый поиск «из коробки» просто бесполезен в таком сценарии. Попробуем это исправить.
Для теста я создал новую таблицу document, в которую добавил 13,5 млн. записей с уникальными номерами вида «ОРГ». Нумерация шла по порядку, все номера начинались с «ОРГ». Можно начинать.
Предварительное разбиение номера
Полнотекстовый поиск умеет эффективно искать слова. Ну так давайте ему поможем и заранее разобьем «неудобный» номер на удобные слова. План действий такой:
Добавим дополнительную колонку в таблицу.
Триггер, заполняющий новую колонку, можно написать «в лоб», игнорируя возможные дубли (сколько повторяющихся троек в номере «МНГ0000012»?) А можно добавить немного XML-магии и записывать только уникальные части. Первая реализация будет быстрее, вторая – даст более компактный результат. По сути, выбор стоит между скоростью записи и скоростью чтения, выбирайте, что в вашей ситуации важнее. Сейчас же просто пройдемся скриптом, который обработает уже существующие номера.
Добавляем полнотекстовый индекс
И проверяем результат. Эксперимент тот же — моделирование «оконной» выборки из списка документов. Не повторяем предыдущих ошибок и сразу выполняем запрос с сортировкой, в данном случае по дате.
Работает! Теперь попробуем номер подлиннее:
И тут случается осечка. Длина поисковой строки больше, чем длина сохраненных «слов». По сути, в базе поиска просто нет ни одной строки в 4 символа, поэтому он честно возвращает пустой результат. Придётся бить поисковую строку на части:
Другое дело! У нас снова работает быстрый поиск. Да, он накладывает свои накладные расходы на обслуживание, но результат оказывается в сотни раз быстрее классического поиска. Отмечаем попытку засчитанной, но попробуем как-то упростить сопровождение – в следующем разделе.
Разобьем на слова по-своему!
В самом деле, кто сказал, что слова должны разделяться пробелами? Может быть, я хочу, чтобы между словами были нули! (и, если можно, префикс чтобы тоже как-то игнорировался и не мешался под ногами). В общем-то, ничего невозможного в этом нет. Вспомним схему работы полнотекстового поиска из начала статьи – за разбиение на слова отвечает отдельный компонент, wordbreaker, и, по счастью, Microsoft позволяет реализовать свой собственный «разбиватель слов».
И вот тут начинается интересное. Wordbreaker – это отдельная dll, которая подключается к движку полнотекстового поиска. В официальной документации сказано, что сделать эту библиотеку очень просто – достаточно реализовать интерфейс IWordBreaker. И приведена пара коротких листингов инициализации на C++. Очень удачно, я как раз нашел подходящий самоучитель!
(источник)
Если серьезно, документации по созданию собственного worbreaker’а в интернете исчезающе мало. Ещё меньше примеров и шаблонов. Но я все-таки нашёл проект доброго человека, который написал на C++ реализацию, разбивающую слова не по разделителям, а просто тройками (да, прямо как в предыдущем разделе!) Более того, в папке проекта уже есть заботливо скомпилированный бинарник, который надо просто подключить к движку поиска.
Просто подключить… На самом деле не очень просто. Пройдёмся по шагам:
Необходимо скопировать библиотеку в папку с SQL Server:
Зарегистрировать новый «язык» в полнотекстовом поиске
Вручную отредактировать несколько ключей в реестре (автор собирался автоматизировать процесс, но с 2016 года новостей нет. Впрочем, это изначально был «пример реализации», спасибо и на этом)
Подробно шаги описаны на странице проекта.
Готово. Удалим старый полнотекстовый индекс, потому что двух полнотекстовых индексов для одной таблицы быть не может. Создадим новый и проиндексируем наши номера документов. В качестве ключевой колонки указываем сами номера, никаких суррогатных предразбитых колонок больше не нужно. Обязательно указываем «язык номер 1», чтобы использовался именно свежеустановленный wordbreaker.
Работает! Работает так же быстро, как все примеры, рассмотренные выше.
Проверим по длинной строке, на которой споткнулся предыдущий вариант:
Поиск работает прозрачно для пользователя и программиста. Wordbreaker самостоятельно разбивает поисковую строку на части и находит нужный результат.
Получается, теперь нам не нужны дополнительные колонки и триггеры, то есть решение оказывается проще (читай: надёжнее), чем наша предыдущая попытка. Ну в плане поддержки такая реализация оказывается проще и прозрачнее, меньше вероятность возникновения ошибок.
Так, стоп, я сказал «надёжнее»? Мы ведь только что подключили какую-то стороннюю библиотеку к нашей СУБД! А что будет, если она упадет? Ещё ненароком утянет за собой всю службу базы данных!
Тут нужно вспомнить, как в начале статьи я упоминал про службу полнотекстового поиска, отделённую от основного процесса СУБД. Именно здесь становится понятно, почему это важно. Библиотека подключается к службе полнотекстового индексирования, которая может работать с пониженными правами. И, что более важно, если сторонние компоненты упадут, упадет только служба индексирования. Поиск на время остановится (но он и так асинхронный), а ядро СУБД продолжит работать, как будто ничего не случилось.
Подытожив. Добавление собственного wordbreaker’а может оказаться довольно сложной задачей. Но при игре «в долгую» эти усилия окупаются большей гибкостью и простотой обслуживания. Выбор, как обычно, за вами.
Зачем всё это нужно?
Пытливый читатель наверняка уже не раз задался вопросом: «всё это здорово, но как мне использовать эти возможности, если я не могу изменить поисковые запросы из моего приложения?». Резонный вопрос. Подключение полнотектстового поиска MS SQL требует изменения синтаксиса запросов и часто это просто невозможно в имеющейся архитектуре.
Можно попытаться обмануть приложение, «подсунув» вместо обычной таблицы одноимённую table-valued function, которая уже будет выполнять поиск так, как нам хочется. Можно попытаться привязать поиск как некий внешний источник данных. Есть ещё одно решение – Softpoint Data Cluster – специальная служба, которая устанавливается «впроброс» между исходным приложением и службой SQL Server, слушает проходящий трафик и может менять запросы «на лету» по специальным правилам. С помощью таких правил мы можем находить обычные запросы с LIKE и переделывать их на CONTAINS с обращением к полнотекстовому поиску.
К чему такие сложности? Всё-таки скорость поиска подкупает. В высоконагруженной системе, где операторы часто ищут записи по миллионным таблицам, скорость отклика имеет решающее значение. Экономия времени на самой частой операции выливается в десятки дополнительных обработанных заявок, а это живые деньги, которым рад любой бизнес. В конце концов, несколько дней или даже недель на изучение и внедрение технологии окупятся возросшей эффективностью операторов.