ASCII таблица

ASCII — A merican S tandard C ode for I nformation I nterchange.
ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились.
Управляющие символы ASCII (код символа 0-31)
Первые 32 символа в ASCII-таблице не имеют печатных кодов и используются для управления периферийными устройствами, телетайпами, принтерами и т.д.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL \0 | & #000; | Null char | |
| 1 | 001 | 0x01 | 00000001 | SOH | & #001; | Start of Heading | |
| 2 | 002 | 0x02 | 00000010 | STX | & #002; | Start of Text | |
| 3 | 003 | 0x03 | 00000011 | ETX | & #003; | End of Text | |
| 4 | 004 | 0x04 | 00000100 | EOT | & #004; | End of Transmission | |
| 5 | 005 | 0x05 | 00000101 | ENQ | & #005; | Enquiry | |
| 6 | 006 | 0x06 | 00000110 | ACK | & #006; | Acknowledgment | |
| 7 | 007 | 0x07 | 00000111 | BEL | & #007; | Bell | |
| 8 | 010 | 0x08 | 00001000 | BS | & #008; | Back Space | |
| 9 | 011 | 0x09 | 00001001 | HT \t | & #009; | Tab | |
| 10 | 012 | 0x0A | 00001010 | LF \n | & #010; | Новая строка | |
| 11 | 013 | 0x0B | 00001011 | VT | & #011; | Vertical Tab | |
| 12 | 014 | 0x0C | 00001100 | FF | & #012; | Form Feed | |
| 13 | 015 | 0x0D | 00001101 | CR \r | & #013; | Возврат каретки | |
| 14 | 016 | 0x0E | 00001110 | SO | & #014; | Shift Out / X-On | |
| 15 | 017 | 0x0F | 00001111 | SI | & #015; | Shift In / X-Off | |
| 16 | 020 | 0x10 | 00010000 | DLE | & #016; | Data Line Escape | |
| 17 | 021 | 0x11 | 00010001 | DC1 | & #017; | Device Control 1 (oft. XON) | |
| 18 | 022 | 0x12 | 00010010 | DC2 | & #018; | Device Control 2 | |
| 19 | 023 | 0x13 | 00010011 | DC3 | & #019; | Device Control 3 (oft. XOFF) | |
| 20 | 024 | 0x14 | 00010100 | DC4 | & #020; | Device Control 4 | |
| 21 | 025 | 0x15 | 00010101 | NAK | & #021; | Negative Acknowledgement | |
| 22 | 026 | 0x16 | 00010110 | SYN | & #022; | Synchronous Idle | |
| 23 | 027 | 0x17 | 00010111 | ETB | & #023; | End of Transmit Block | |
| 24 | 030 | 0x18 | 00011000 | CAN | & #024; | Cancel | |
| 25 | 031 | 0x19 | 00011001 | EM | & #025; | End of Medium | |
| 26 | 032 | 0x1A | 00011010 | SUB | & #026; | Substitute | |
| 27 | 033 | 0x1B | 00011011 | ESC | & #027; | Escape | |
| 28 | 034 | 0x1C | 00011100 | FS | & #028; | File Separator | |
| 29 | 035 | 0x1D | 00011101 | GS | & #029; | Group Separator | |
| 30 | 036 | 0x1E | 00011110 | RS | & #030; | Record Separator | |
| 31 | 037 | 0x1F | 00011111 | US | & #031; | Unit Separator | |
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Печатные символы ASCII (код символа 32-127)
Буквы, цифры, знаки препинания и другие символы расположенные на клавиатуре (англ.).
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
ASCII и шестнадцатеричное представление строк. Побитовые операции со строками
В литературе, которую я изучаю (например, по обратному инженерингу), для строк как само собой разумеющееся используются ASCII значения или запись в виде шестнадцатеричной строки. Подразумевается что читатели не только должны на лету конвертировать строки между обычным представлением, ASCII кодами символов, шестнадцатеричной и двоичной записью, но и должны уметь делать побитовые операции со строками.
На самом деле, это действительно не особенно сложная тема — достаточно один раз понять суть, а затем при необходимости можно пользоваться таблицами ASCII/Hex/Bin значений символов, либо конвертировать используя соответствующие утилиты или встроенные в языки программирования функции. Если у вас пробел в этих знаниях, то это статья должна вам помочь.
Смотрите также:
Для кого эта статья
Вам абсолютно точно нужно понимать суть ASCII кодирования символов, а также шестнадцатеричную запись строк если вы:
Примечание: правда, я исхожу из того, что вы знаете что такое:
По идее, это охватывается базовым курсом информатики и логики на любых специальностях в ВУЗе (некоторые учат это уже в школе) и это должен знать каждый — поэтому я не будут на этом останавливаться. Если вы не знаете даже этого, то прежде чем читать эту заметку, начните с ликвидации ваших более базовых пробелов про системы счисления.
Что такое ASCII
Не будем тратить время на экскурсы в историю о появлении ASCII — рассмотрим только с практической точки зрения.
А с практической точки зрения в ASCII каждому символу соответствует его порядковый номер. Этот порядковый номер можно записать десятичным числом, например, символу «h» соответствует 104, а символу «i» соответствует 105.
Любое десятичное число можно конвертировать в шестнадцатеричное, двоичное или восьмеричное число. Зачем конвертировать? Главная причина в том, что компьютер в своей основе не работает с десятеричными числами, а использует двоичные, которые удобно записывать в более компактном виде — конвертировать в шестнадцатеричные. Поэтому в определённых программах широко используются эти записи: в шестнадцатеричных редакторах, отладчиках. Также шестнадцатеричную/двоичную запись строк программист может использовать для различных манипуляций, например, с целью шифрования или другой обработки. Например, для тех же самых побитовых операций, к которым мы вернёмся позже.
Итак, вот таблицы символов, с их цифровым представлением в различных системах счисления:
Контрольные символы ASCII (некоторые из них больше не актуальны, так как подразумевают использование в телетайп связи)
Во многих языках программирования символ обозначается как «\n». Нажатие на клавишу ↵ Enter при выводе текста переводит строку.
В настоящее время символ вставляется нажатием комбинации клавиш Ctrl + Z и используется для обозначения конца файла в операционных системах «DOS» и «Windows».
Код этого символа происходит из первых текстовых процессоров с памятью на перфоленте: в них удаление символа происходило «забиванием» его кода дырочками (обозначавшими логические единицы).
Печатные символы ASCII
Расширенные символы ASCII
| Десятичное значение | Шестнадцатеричное | Двоичное | Символ | Описание |
|---|---|---|---|---|
| 128 | 80 | 10000000 | | |
| 129 | 81 | 10000001 | | |
| 130 | 82 | 10000010 | | |
| 131 | 83 | 10000011 | | |
| 132 | 84 | 10000100 | | |
| 133 | 85 | 10000101 | ||
| 134 | 86 | 10000110 | | |
| 135 | 87 | 10000111 | | |
| 136 | 88 | 10001000 | | |
| 137 | 89 | 10001001 | | |
| 138 | 8A | 10001010 | | |
| 139 | 8B | 10001011 | | |
| 140 | 8C | 10001100 | | |
| 141 | 8D | 10001101 | | |
| 142 | 8E | 10001110 | | |
| 143 | 8F | 10001111 | | |
| 144 | 90 | 10010000 | | |
| 145 | 91 | 10010001 | | |
| 146 | 92 | 10010010 | | |
| 147 | 93 | 10010011 | | |
| 148 | 94 | 10010100 | | |
| 149 | 95 | 10010101 | | |
| 150 | 96 | 10010110 | | |
| 151 | 97 | 10010111 | | |
| 152 | 98 | 10011000 | | |
| 153 | 99 | 10011001 | | |
| 154 | 9A | 10011010 | | |
| 155 | 9B | 10011011 | | |
| 156 | 9C | 10011100 | | |
| 157 | 9D | 10011101 | | |
| 158 | 9E | 10011110 | | |
| 159 | 9F | 10011111 | | |
| 160 | A0 | 10100000 | пробел | |
| 161 | A1 | 10100001 | ¡ | |
| 162 | A2 | 10100010 | ¢ | цент |
| 163 | A3 | 10100011 | £ | фунт |
| 164 | A4 | 10100100 | ¤ | знак валюты |
| 165 | A5 | 10100101 | ¥ | иена, юань |
| 166 | A6 | 10100110 | ¦ | сломанный бар |
| 167 | A7 | 10100111 | § | знак параграфа |
| 168 | A8 | 10101000 | ¨ | |
| 169 | A9 | 10101001 | © | копирайт |
| 170 | AA | 10101010 | ª | порядковый индикатор |
| 171 | AB | 10101011 | « | |
| 172 | AC | 10101100 | ¬ | |
| 173 | AD | 10101101 | ||
| 174 | AE | 10101110 | ® | зарегистрированная торговая марка |
| 175 | AF | 10101111 | ¯ | |
| 176 | B0 | 10110000 | ° | градус |
| 177 | B1 | 10110001 | ± | плюс-минус |
| 178 | B2 | 10110010 | ² | |
| 179 | B3 | 10110011 | ³ | |
| 180 | B4 | 10110100 | ´ | |
| 181 | B5 | 10110101 | µ | мю |
| 182 | B6 | 10110110 | ¶ | знак абзаца |
| 183 | B7 | 10110111 | · | |
| 184 | B8 | 10111000 | ¸ | |
| 185 | B9 | 10111001 | ¹ | |
| 186 | BA | 10111010 | º | порядковый индикатор |
| 187 | BB | 10111011 | » | |
| 188 | BC | 10111100 | ¼ | |
| 189 | BD | 10111101 | ½ | |
| 190 | BE | 10111110 | ¾ | |
| 191 | BF | 10111111 | ¿ | перевернутый знак вопроса |
| 192 | C0 | 11000000 | À | |
| 193 | C1 | 11000001 | Á | |
| 194 | C2 | 11000010 | Â | |
| 195 | C3 | 11000011 | Ã | |
| 196 | C4 | 11000100 | Ä | |
| 197 | C5 | 11000101 | Å | |
| 198 | C6 | 11000110 | Æ | |
| 199 | C7 | 11000111 | Ç | |
| 200 | C8 | 11001000 | È | |
| 201 | C9 | 11001001 | É | |
| 202 | CA | 11001010 | Ê | |
| 203 | CB | 11001011 | Ë | |
| 204 | CC | 11001100 | Ì | |
| 205 | CD | 11001101 | Í | |
| 206 | CE | 11001110 | Î | |
| 207 | CF | 11001111 | Ï | |
| 208 | D0 | 11010000 | Ð | |
| 209 | D1 | 11010001 | Ñ | |
| 210 | D2 | 11010010 | Ò | |
| 211 | D3 | 11010011 | Ó | |
| 212 | D4 | 11010100 | Ô | |
| 213 | D5 | 11010101 | Õ | |
| 214 | D6 | 11010110 | Ö | |
| 215 | D7 | 11010111 | × | знак умножения |
| 216 | D8 | 11011000 | Ø | |
| 217 | D9 | 11011001 | Ù | |
| 218 | DA | 11011010 | Ú | |
| 219 | DB | 11011011 | Û | |
| 220 | DC | 11011100 | Ü | |
| 221 | DD | 11011101 | Ý | |
| 222 | DE | 11011110 | Þ | |
| 223 | DF | 11011111 | ß | |
| 224 | E0 | 11100000 | à | |
| 225 | E1 | 11100001 | á | |
| 226 | E2 | 11100010 | â | |
| 227 | E3 | 11100011 | ã | |
| 228 | E4 | 11100100 | ä | |
| 229 | E5 | 11100101 | å | |
| 230 | E6 | 11100110 | æ | |
| 231 | E7 | 11100111 | ç | |
| 232 | E8 | 11101000 | è | |
| 233 | E9 | 11101001 | é | |
| 234 | EA | 11101010 | ê | |
| 235 | EB | 11101011 | ë | |
| 236 | EC | 11101100 | ì | |
| 237 | ED | 11101101 | í | |
| 238 | EE | 11101110 | î | |
| 239 | EF | 11101111 | ï | |
| 240 | F0 | 11110000 | ð | |
| 241 | F1 | 11110001 | ñ | |
| 242 | F2 | 11110010 | ò | |
| 243 | F3 | 11110011 | ó | |
| 244 | F4 | 11110100 | ô | |
| 245 | F5 | 11110101 | õ | |
| 246 | F6 | 11110110 | ö | |
| 247 | F7 | 11110111 | ÷ | крестик |
| 248 | F8 | 11111000 | ø | |
| 249 | F9 | 11111001 | ù | |
| 250 | FA | 11111010 | ú | |
| 251 | FB | 11111011 | û | |
| 252 | FC | 11111100 | ü | |
| 253 | FD | 11111101 | ý | |
| 254 | FE | 11111110 | þ | |
| 255 | FF | 11111111 | ÿ |
Как отличить двоичное, шестнадцатеричное и десятичное написание друг от друга
Конкретные нотации могут различаться в зависимости от языка программирования или используемой программы (printf, printf, xxd, hexdump и так далее), но обычно используются следующие правила:
По умолчанию целочисленный литерал (число) — это десятичное целое число.
Для обозначения двоичного целочисленного литерала перед ним используется 0b или 0B (ноль B). Иногда буква b ставится позади числа.
Для обозначения восьмеричного целочисленного литерала, перед ним используется 0 (ноль).
А для обозначения шестнадцатеричного целочисленного литерала, перед ним используется 0x или 0X (ноль X).
В Radare2 можно увидеть такую запись:
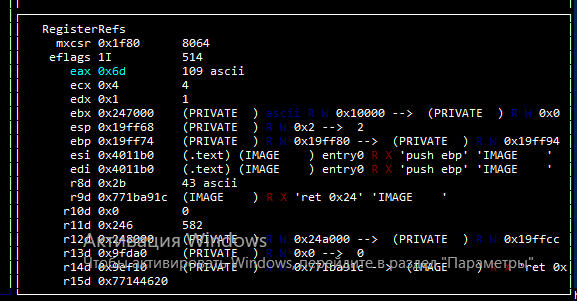
Обратите внимание на переменную eax, значение которой равно 0x6d, а затем дано пояснение 109 ascii. То есть в шестнадцатеричном виде значение переменной eax равно 0x6d, в десятеричном это 109 что соответствует символу m.
ASCII и HTML
Если в HTML коде перед десятичным кодом ASCII символа поставить &#, то веб-браузер отобразит этот символ.
К примеру, если использовать ', то веб-браузер покажет ‘ (одинарную кавычку). Некоторые преобразователи строк внутри веб-приложения также могут конвертировать написание символов &#XX в их ASCII представления. Поэтому безобидная запись ' внутри веб-приложения может превратиться в одинарную кавычку, которая может нарушить SQL запрос.
Аналогично можно использовать &#x, после которой нужно указать код символа в шестнадцатеричной системе, например, ' также покажет кавычку. Для разделения символов друг от друга, используйте точку с запятой, например, ‘hi’
Многие программы понимают шестнадцатеричную запись, правда вид записи может различаться от конкретной программы и языка программирования.
В JavaScript шестнадцатеричные строки записываются в виде экранированной последовательности:
Можно записать код символов в восьмеричной системе счисления:
Аналогично Bash понимает такие строки:
И PHP их обрабатывает верно:
Побитовые операции над строками
К побитовым операторам относятся:
Если вспомнить школьный/ВУЗовский курс логики, то там такие операции выполняются с нулями и единицами. То есть их можно выполнить с бинарными данными, например, с двоичными числами.
В языках программирования можно делать побитовые операции с десятичными числами, например Побитовое ИСКЛЮЧАЮЩЕЕ ИЛИ (XOR) в PHP:
Дело в том, что числа будут автоматически переведены в двоичный вид и операция будет выполнена уже над двоичными числами.
8 и 5 в двоичном виде это соответственно 1000 и 101, можно также из записать так: 1000 и 0101.
Получаем конечное число: 1101
То есть в PHP операция проделана правильно, даже не смотря на то, что мы указали не двоичные числа, а десятичные.
Когда говорят о побитовых операциях со строками, то имеют в виду, что используется ASCII код символа (который затем переводиться в двоичный вид). После выполнения требуемой операции, выполняется обратное преобразование — число переводиться в ASCII символ.
Кстати, про ИСКЛЮЧАЮЩЕЕ ИЛИ (XOR) — у этой операции есть интересное свойство:
То есть можно взять строки и выполнить между ними операцию XOR. В результате получиться бессмысленный набор символов. Затем если между этой бессмысленной строкой и любой из первоначальных строк вновь выполнить операцию XOR, то получиться вторая начальная строка.
На этом основано простейшее симметричное шифрование: исходный текст шифруется паролем с помощью XOR. То есть с первым символом текста и первыми символом пароля делается операция XOR, затем со вторым символом шифруемого текста и вторым символом пароля делается операция XOR и так далее, пока шифруемый текст не кончится. Поскольку пароль обычно короче шифруемого текста, то когда он заканчивается, вновь выполняется переход к первому символу пароля и так далее много раз.
В результате получается бессмысленный набор символов, которые можно расшифровать этим же паролем выполняя эту же операцию XOR.
Правда, зашифрованные таким образом тексты часто приводятся для тренировки в литературе по взлому шифров: если текст достаточно длинный, то с помощью статистического анализа того, как часто в нём встречаются символы и сравнивая эту частотность с естественной частотностью букв в языке, сначала вычисляют длину пароля, а затем и сам пароль. То есть это крайне ненадёжный шифр.
Вычитание числа из строки и прибавление к строкам числа
В статье «Анализ вредоносной программы под Linux: плохое самодельное шифрование» рассматривается шифрование, которое основано на прибавлении или вычитании числа к символу строки (на основе позиции символов). Как я думаю вы уже поняли, используется аналогичный приём: берётся ASCII код символа и из этого числа делается вычитание или находиться сумма с ним, а затем полученное число опять переводят в ASCII символ.
Побитовые операции с цифрами: нужно переводить в двоичную систему сами цифры или брать двоичные значения ASCII каждого символа?
Допустим, мы хотим сделать побитовую операцию 5 OR 7. Какой будет результат? Микропроцессор не работает ни с числами в десятичной системе, ни с ASCII строками — микропроцессор работает только двоичными числами.
То есть возникает вопрос:
2. Это ASCII строки?
Рассмотрим оба эти варианта, чтобы понять, насколько они различаются.
Число 5 в двоичной системе это 101, а число 7 в двоичной системе это 111.
В результате выполнения
Будет получено 111. То есть результатом данной операции является число 7.
5 и 7 — это ASCII строки
Смотрим таблицу ASCII символов, там цифре 5 соответствует код 00110101, а цифре 7 соответствует код 00110111. Делаем побитовую операцию OR между ними:
00110101 OR 00110111
Получаем: 110111, что в таблице ASCII символов также соответствует символу «7».
Итак, в принципе, можно напрямую переводить данные цифры в их двоичные значения, либо можно использовать двоичные значения их символов. Самое главное, придерживаться одной и той же схемы и преобразовывать с учётом выбранного пути. Ведь если вы делаете логическую операцию (например OR), с ASCII значением, а затем начинаете толковать полученный результат как число, то такое число (в нашем примере), будет равно 110111 = 55 (в десятичной системе). Или наоборот, вы сделали побитовую операцию между 101 OR 111, а затем полученный результат 111 начинаете трактовать как ASCII код символа — то тогда вместо числа вы получите управляющий символ «звуковой сигнал: звонок».
Заключение
Подытожим: у всех символов (печатных и непечатных) есть свой код ASCII. Кстати, ASCII — это ведь одна из многих кодировок. Существует много разных кодировок, например, очень популярна UTF8 и там у символов свои собственные коды. Причём используя экранированные последовательности можно записывать символы UTF8 по аналогии, как это показано с ASCII.
О том, как разными способами записать один и тот же символ (на примере “>”) смотрите здесь: https://security.stackexchange.com/questions/205967/character-escape-sequences-for
Эти техники могут использоваться в обходе фильтрации символов и слов.