Организация хранилища данных
В настоящее время однозначного определения ХД не существует, из-за того что разработано большое количество различных архитектур и технологий ХД, а сами хранилища используются для решения самых разнообразных задач. Каждый автор вкладывает в это понятие свое видение вопроса. Обобщая требования, предъявляемые к СППР, можно дать следующее определение ХД, которое не претендует на полноту и однозначность, но позволяет понять основную идею.
Хранилище данных — разновидность систем хранения, ориентированная на поддержку процесса анализа данных, обеспечивающая целостность, непротиворечивость и хронологию данных, а также высокую скорость выполнения аналитических запросов.
Инмон дал следующее определение ХД: предметно-ориентированный, интегрированный, неизменяемый и поддерживающий хронологию набор данных, предназначенный для обеспечения принятия управленческих решений.
Под предметной ориентированностью в данном случае подразумевается, что ХД должно разрабатываться с учетом специфики конкретной предметной области, а не аналитических приложений, с которыми его предполагается использовать. Структура ХД должна отражать представления аналитика об информации, с которой ему приходится работать.
Интегрированность означает, что должна быть обеспечена возможность загрузки в ХД информации из источников, поддерживающих различные форматы Данных и созданных в различных приложениях — учетных системах, базах данных, электронных таблицах и других офисных приложениях, поддерживающих структурированность данных (например, текстовые файлы с разделителями). При этом данные, допускающие различный формат (например, числа, дата и время), в процессе загрузки должны быть преобразованы к единому представлению. Кроме того, очень важно проверить загружаемые данные на целостность и непротиворечивость, обеспечить необходимый уровень их обобщения (агрегирования). Объем данных в хранилище должен быть достаточным для эффективного решения аналитических задач, поэтому в ХД может накапливаться информация за несколько лет и даже десятилетий.
Принцип неизменчивости предполагает, что, в отличие от обычных систем оперативной обработки данных, в ХД данные после загрузки не должны подвергаться каким-либо изменениям, за исключением добавления новых данных.
И наконец, поддержка хронологии означает соблюдение порядка следования записей, для чего в структуру ХД вводятся ключевые атрибуты Дата и Время. Кроме того, если физически упорядочить записи в хронологическом порядке, например в порядке возрастания атрибута Дата, можно уменьшить время выполнения аналитических запросов.
Важнейшим элементом ХД является семантический слой — механизм, позволяющий аналитику оперировать данными посредством бизнес-терминов предметной области. Семантический слой дает пользователю возможность сосредоточиться на анализе и не задумываться о механизмах получения данных.
Типичное ХД существенно отличается от обычных систем хранения данных. Главным отличием являются цели использования. Например, регистрация продаж и выписка соответствующих документов — задача уровня OLTP-систем, использующих обычные реляционные СУБД. Анализ динамики продаж и спроса за несколько лет, позволяющий выработать стратегию развития фирмы и спланировать работу с поставщиками и клиентами, удобнее всего выполнять при поддержке ХД.
Другое важное отличие заключается в динамике изменения данных. Базы данных в OLTP-системах характеризуются очень высокой динамикой изменения записей из-за повседневной работы большого числа пользователей (откуда, кстати, велика вероятность появления противоречий, ошибок, нарушения целостности данных и т. д.). Что касается ХД, то данные из него не удаляются, а пополнение происходит в соответствии с определенным регламентом (раз в час, день, неделю, в определенное время).
Чтобы ХД выполняло функции, соответствующие его основной задаче — поддержке процесса анализа данных, — оно должно удовлетворять требованиям, сформулированным Р. Кимбаллом, одним из авторов концепции ХД:
высокая скорость получения данных из хранилища;
автоматическая поддержка внутренней непротиворечивости данных;
возможность получения и сравнения срезов данных;
наличие удобных средств для просмотра данных в хранилище;
обеспечение целостности и достоверности хранящихся данных.
Чтобы соблюсти все перечисленные требования, для построения и работы ХД, как правило, используется не одно приложение, а система, в которую входит несколько программных продуктов. Одни из них представляют собой собственно систему хранения данных, другие — средства их просмотра, извлечения, загрузки и т. д.
В последние десятилетия технология ХД стремительно развивается. Десятки компаний предлагают на рынке свои решения в области ХД, и тысячи организаций уже используют это мощное средство поддержки аналитических проектов.
Процесс разработки ХД весьма трудоемок, некоторые организации затрачивают на него несколько месяцев и даже лет, а также вкладывают значительные финансовые средства. Основными задачами, которые требуется решить в процессе разработки ХД, являются:
выбор структуры хранения данных, обеспечивающей высокую скорость выполнения запросов и минимизацию объема оперативной памяти;
первоначальное заполнение и последующее пополнение хранилища;
обеспечение единой методики работы с разнородными данными и создание удобного интерфейса пользователя.
Круг задач интеллектуального анализа данных весьма широк, а сами задачи существенно различаются по уровню сложности. Поэтому в зависимости от специфики решаемых задач и уровня их сложности архитектура ХД и модели данных, используемых для их построения, могут различаться. Обобщенная концептуальная схема ХД:

Данные в ХД хранятся как в детализированном, так и в агрегированном виде. Данные в детализированном виде поступают непосредственно из источников данных и соответствуют элементарным событиям, регистрируемым OLTP-системами. Такими данными могут быть ежедневные продажи, количество произведенных изделий и т.д. Это неделимые значения.
Многие задачи анализа (например, прогнозирование) требуют использования Данных определенной степени обобщения. Например, суммы продаж, взятые по дням, Могут дать очень неравномерный ряд данных, что затруднит выявление характерных периодов, закономерностей или тенденций. Однако, если обобщить эти данные в пределах недели или месяца и взять сумму, среднее, максимальное и минимальное значения за соответствующий период, то полученный ряд может оказаться более информативным. Процесс обобщения детализированных данных называется агрегированием, а сами обобщенные данные — агрегированными (иногда — агрегатами). Обычно агрегированию подвергаются числовые данные (факты), они вычисляются и содержатся в ХД вместе с детализированными данными.
Поскольку один и тот же набор детализированных данных может породить несколько наборов агрегированных данных с различной степенью обобщения, объем ХД возрастает, иногда существенно. Иногда это приводит к «взрывному», неконтролируемому росту ХД и вызывает серьезные технические проблемы: хранилище «распухает», из-за того что непрерывный поток входных данных автоматически агрегируется в соответствии с настройками ХД. Однако с этим приходится мириться: если бы агрегированные данные не содержались в ХД, а вычислялись в процессе выполнения запросов, время выполнения запроса увеличилось бы в несколько раз.
Слово «метаданные» (от греч. meta и лат. data) буквально переводится как «данные о данных». Метаданные в широком смысле необходимы для описания значения и свойств информации с целью лучшего ее понимания, использования и управления ею. Любой человек, который читал книги или пользовался библиотекой, в той или иной мере имел дело с метаданными.
Метаданные — высокоуровневые средства отражения информационной модели и описания структуры данных, используемой в ХД. Метаданные должны содержать описание структуры данных хранилища и структуры данных импортируемых источников. Метаданные хранятся отдельно от данных в так называемом репозитарии метаданных.
Метаданные являются ключевым фактором успеха при разработке и внедрении ХД. Они содержат всю информацию, необходимую для извлечения, преобразования и загрузки данных из различных источников, а также для последующего использования и интерпретации данных, содержащихся в ХД.
Можно выделить два уровня метаданных — технический (административный) и бизнес-уровень. Технический уровень содержит метаданные, необходимые для обеспечения функционирования хранилища (статистика загрузки данных и их использования, описание модели данных и т. д.). Бизнес-метаданные обеспечивают пользователю возможность концентрироваться на процессе анализа, а не на технических аспектах работы с хранилищем; они включают бизнес-термины и определения, которыми привык оперировать пользователь.
Бизнес-метаданные образуют так называемый семантический слой. Пользователь оперирует близкими ему терминами предметной области: товар, клиент, продажи, покупки и т. д., а семантический слой транслирует бизнес-термины в низкоуровневые запросы к данным в хранилище.
С помощью аналитического приложения, используемого совместно с ХД, можно формировать запросы и получать по ним данные из хранилища. Данные могут визуализироваться непосредственно либо подвергаться обработке средствами аналитического приложения, тогда визуализируются результаты этой обработки. Спектр аналитических задач очень широк. Соответственно, и методики применения ХД для решения тех или иных задач весьма разнообразны. Тем не менее можно выделить три основных подхода к использованию ХД:
□ регулярные отчеты — подготовка отчетов стандартных форм, получаемых многократно с определенной периодичностью;
□ нерегламентированные запросы — возможность получать ответы на нестандартные, сформированные «по требованию» вопросы;
□ интеллектуальный анализ данных — поддержка процесса интеллектуального анализа больших массивов данных с целью выявления скрытых закономерностей, структур и объектов, построения моделей, прогнозов и т. д.
Разработка и построение корпоративного ХД — это дорогостоящая и трудоемкая задача. Успешность внедрения ХД во многом зависит от уровня информатизации бизнес-процессов в компании, установившихся информационных потоков, объема и структуры используемых данных, требований к скорости выполнения запросов и частоте обновления хранилища, характера решаемых аналитических задач и т. д. Чтобы приблизить ХД к условиям и специфике конкретной организации, в настоящее время разработано несколько архитектур хранилищ — реляционные, многомерные, гибридные и виртуальные.
Реляционные ХД используют классическую реляционную модель, характерную для оперативных регистрирующих OLTP-систем. Данные хранятся в реляционных таблицах, но образуют специальные структуры, эмулирующие многомерное представление данных. Такая технология обозначается аббревиатурой ROLAP — Relational OLAP.
Многомерные ХД реализуют многомерное представление данных на физическом уровне в виде многомерных кубов. Данная технология получила название MOLAP — Multidimensional OLAP.
Гибридные ХД сочетают в себе свойства как реляционной, так и многомерной модели данных. В гибридных ХД детализированные данные хранятся в реляционных таблицах, а агрегаты — в многомерных кубах. Такая технология построения ХД называется HOLAP — Hybrid OLAP.
Что такое хранилища данных
Лекция 10. Хранилища данных
Тест FASMI
Данные, применяемые для анализа, стали выделять в отдельные БД, которые стали называться хранилища данных (ХД, Data Warehouse). Концепция ХД – это концепция подготовки данных для последующего анализа. Предполагает:
1) Интеграцию и согласование данных из различных источников: OLTP-систем, информации из внутренних и внешних электронных архивов;
2) Разделение наборов данных OLTP и OLAP-систем.
OLAP-системы не заменяют собой OLTP-системы, а надстраиваются над ними, и используют транзакционные системы в качестве источников данных.
Схема функционирования СППР, основанной на концепции хранилища данных, приведена на рис.10.1.
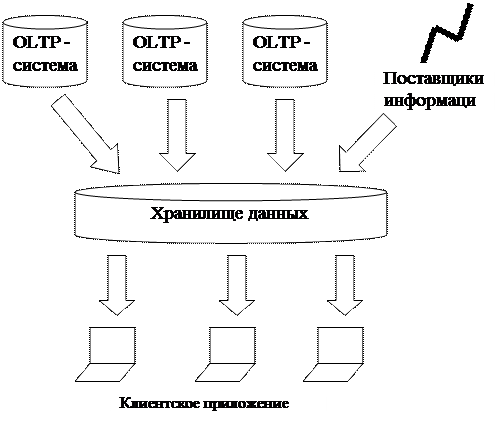
Рисунок 10.1 – Схема функционирования системы
Исходные данные для анализа производятся системами операционной обработки, поступают из электронных архивов и от поставщиков информации, например, on-line информационных агентств. Эти источники слабо связаны между собой, поэтому и данные, которые они представляют, имеют разную структуру, форматы представления.
Необходимо произвести согласование данных из разных источников, чтобы ими было удобно оперировать при анализе. Устранить дублирование и некорректные значения. Подготовленные данные загружаются в хранилище. Пользователи – аналитики осуществляют доступ к нему через клиентские приложения.
В отличие от систем операционной обработки данных, в СППР, использующих концепцию ХД, критерии поиска и состав выдаваемой в виде отчета информации не фиксируется при ее разработке, пользователи оперируют в основном к заранее не регламентированным запросам.
Использование ХД в СППР преследует следующие цели:
1) Своевременное обеспечение аналитиков всей информацией, необходимой для выработки решений;
2) Создание единой модели данных организации;
3) Создание интегрированного источника данных, предоставляет удобный доступ к разнородной информации.
10.2 Свойства ХД:
1. Ориентация на предметную область. Хранилище должно разрабатываться с учетом специфики предметной области, а не приложений, оперирующих данными. Структура хранилища должна отражать представления аналитика об информации, с которой ему приходится работать. Например, если система операционной обработки поставщика товаров работает с понятиями „сделка”, „заявка”, то хранилище должно использовать понятия „клиенты”, „товары” и „производители”.
2. Интегрированность. Информация загружается в хранилище из приложений, созданных разными разработчиками. Необходимо объединить данные этих приложений, приведя их к единому синтаксическому и семантическому виду. Например, в таблицах БД полученных из разных источников могут встречаться атрибуты, которые по-разному представлены, но обозначают те же понятия. Например, месяц года может быть „январь” или, в другой таблице, „янв.” или „1”. В процессе загрузки в хранилище требуется преобразовывать эти атрибуты к единому представлению. Важно также провести проверку поступающих данных на целостность и непротиворечивость. Характерный для хранилища прием – хранение агрегированных данных. Аналитика редко интересует информация о конкретных днях и часах, ему более важны данные о месяцах, кварталах или даже годах. Чтобы при выполнении аналитических запросов избежать выполнения операций группирования, данные должны (группироваться) обобщаться (агрегироваться) при загрузке в хранилище. Объем накопленных данных должен быть достаточным для решения аналитических задач с требуемым качеством. Используемые ХД содержат информацию, накопленную за годы и даже десятилетия. Итак:
2.1 Преобразование данных к единому представлению.
2.2 Проверка на целостность и непротиворечивость.
2.3 Агрегирование данных.
3. Поддержка хронологии. Для выполнения большинства аналитических запросов необходим анализ тенденций развития явлений или характера изменений значений переменной во времени.
4. Неизменяемость данных. Данные после загрузки в ХД остаются неизменными, внесение каких либо изменений, кроме добавления записи, не предполагается. Важно использование надежного оборудования, которое обеспечивает защиту от сбоев. Не важно защита транзакций, блокировки процессов и т.д.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Основные концепции хранилищ данных
Основные положения концепции ХД
Принято считать, что у истоков концепции ХД стоял технический директор компании Prism Solutions Билл Инмон, который в начале 1990-х гг. опубликовал ряд работ, ставших основополагающими для последующих исследований в области аналитических систем.
Инмон дал следующее определение ХД: предметно-ориентированный, интегрированный, неизменяемый и поддерживающий хронологию набор данных, предназначенный для обеспечения принятия управленческих решений.
Под предметной ориентированностью в данном случае подразумевается, что ХД должно разрабатываться с учетом специфики конкретной предметной области, а не аналитических приложений, с которыми его предполагается использовать. Структура ХД должна отражать представления аналитика об информации, с которой ему приходится работать.
Интегрированность означает, что должна быть обеспечена возможность загрузки в ХД информации из источников, поддерживающих различные форматы данных и созданных в различных приложениях — учетных системах, базах данных, электронных таблицах и других офисных приложениях, поддерживающих структурированность данных (например, текстовые файлы с разделителями). При этом данные, допускающие различный формат (например, числа, дата и время), в процессе загрузки должны быть преобразованы к единому представлению. Кроме того, очень важно проверить загружаемые данные на целостность и непротиворечивость, обеспечить необходимый уровень их обобщения (агрегирования). Объем данных в хранилище должен быть достаточным для эффективного решения аналитических задач, поэтому в ХД может накапливаться информация за несколько лет и даже десятилетий.
Принцип неизменчивости предполагает, что, в отличие от обычных систем оперативной обработки данных, в ХД данные после загрузки не должны подвергаться каким-либо изменениям, за исключением добавления новых данных.
И наконец, поддержка хронологии означает соблюдение порядка следования записей, для чего в структуру ХД вводятся ключевые атрибуты Дата и Время. Кроме того, если физически упорядочить записи в хронологическом порядке, например в порядке возрастания атрибута Дата, можно уменьшить время выполнения аналитических запросов.
Задачи, решаемые ХД
Круг задач интеллектуального анализа данных весьма широк, а сами задачи существенно различаются по уровню сложности. Поэтому в зависимости от специфики решаемых задач и уровня их сложности архитектура ХД и модели данных, используемых для их построения, могут различаться. Обобщенная концептуальная схема ХД представлена на рис. 4.
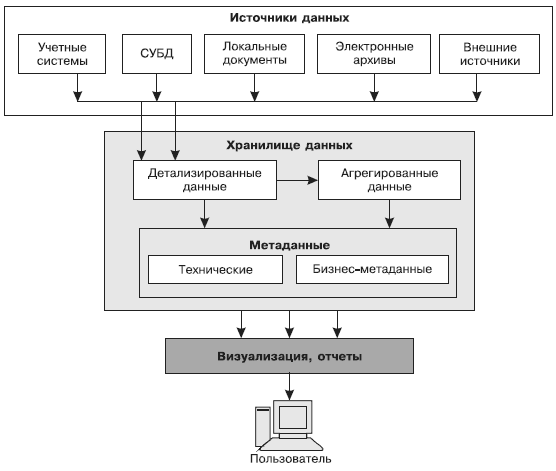
Рис. 4. Концептуальная схема ХД
Согласно схеме данные извлекаются из различных источников и загружаются в ХД, которое содержит как собственно данные, представленные в соответствии с некоторой моделью, так и метаданные.
Детализированные и агрегированные данные
Данные в ХД хранятся как в детализированном, так и в агрегированном виде. Данные в детализированном виде поступают непосредственно из источников данных и соответствуют элементарным событиям, регистрируемым OLTP-системами. Такими данными могут быть ежедневные продажи, количество произведенных изделий и т.д. Это неделимые значения, попытка дополнительно детализировать которые лишает их логического смысла.
Многие задачи анализа (например, прогнозирование) требуют использования данных определенной степени обобщения. Например, суммы продаж, взятые по дням, могут дать очень неравномерный ряд данных, что затруднит выявление характерных периодов, закономерностей или тенденций. Однако, если обобщить эти данные в пределах недели или месяца и взять сумму, среднее, максимальное и минимальное значения за соответствующий период, то полученный ряд может оказаться более информативным. Процесс обобщения детализированных данных называется агрегированием, а сами обобщенные данные — агрегированными (иногда — агрегатами). Обычно агрегированию подвергаются числовые данные (факты), они вычисляются и содержатся в ХД вместе с детализированными данными.
Поскольку один и тот же набор детализированных данных может породить несколько наборов агрегированных данных с различной степенью обобщения, объем ХД возрастает, иногда существенно. Например, набор, содержащий данные о продажах по дням в течение года, помимо своих 360 значений, порождает 52 значения с обобщением по неделям и 12 — по месяцам. Если при этом вычисляются все виды агрегации — сумма, среднее, максимальное и минимальное значения за соответствующий период, — то количество хранящихся агрегированных значений составит уже (52 + 12) • 4 = 256. Иногда это приводит к «взрывному», неконтролируемому росту ХД и вызывает серьезные технические проблемы: хранилище «распухает», из-за того что непрерывный поток входных данных автоматически агрегируется в соответствии с настройками ХД. Однако с этим приходится мириться: если бы агрегированные данные не содержались в ХД, а вычислялись в процессе выполнения запросов, время выполнения запроса увеличилось бы в несколько раз.
Метаданные
Слово «метаданные» (от греч. meta и лат. data) буквально переводится как «данные о данных». Метаданные в широком смысле необходимы для описания значения и свойств информации с целью лучшего ее понимания, использования и управления ею. Любой человек, который читал книги или пользовался библиотекой, в той или иной мере имел дело с метаданными.
Всем хорошо известно, что в любой книге, помимо собственно текста, содержится значительное количество дополнительной информации. Цель ее заключается в том, чтобы, во-первых, помочь читателю быстрее ознакомиться с содержимым книги и осмыслить его, во-вторых, описать структуру книги для более эффективного поиска нужной информации. Для решения первой задачи служат такие элементы, как аннотация, комментарии, глоссарий, примечания и т.д. Для поиска нужной информации используются оглавление, названия глав, параграфов и разделов, номера страниц, колонтитулы, предметный указатель и т.д. Кроме этого, читателю могут понадобиться сведения об авторах или об издательстве. Вся эта информация, которая не является частью книги, а служит для повышения эффективности работы с ней, и представляет собой метаданные. В библиотеке метаданные применяются для поиска нужных изданий и отслеживания их перемещений, например, систематический или алфавитный каталоги, в которых используются названия книг, фамилии авторов, год издания и т.д. Таким образом, метаданные имеют очень большое значение при работе с различного рода информацией.
С точки зрения IT-технологий метаданные — любая информация, необходимая для анализа, проектирования, построения, внедрения и применения компьютерной информационной системы. Одно из основных назначений метаданных — повышение эффективности поиска. Поисковые запросы, использующие метаданные, делают возможным выполнение сложных операций по фильтрации и отбору данных.
Если рассматривать понятие «метаданные» в контексте технологии ХД, то его можно определить следующим образом.
Метаданные — высокоуровневые средства отражения информационной модели и описания структуры данных, используемой в ХД. Метаданные должны содержать описание структуры данных хранилища и структуры данных импортируемых источников. Метаданные хранятся отдельно от данных в так называемом репозитарии метаданных.
Метаданные являются ключевым фактором успеха при разработке и внедрении ХД. Они содержат всю информацию, необходимую для извлечения, преобразования и загрузки данных из различных источников, а также для последующего использования и интерпретации данных, содержащихся в ХД.
Можно выделить два уровня метаданных — технический (административный) и бизнес-уровень. Технический уровень содержит метаданные, необходимые для обеспечения функционирования хранилища (статистика загрузки данных и их использования, описание модели данных и т.д.). Бизнес-метаданные обеспечивают пользователю возможность концентрироваться на процессе анализа, а не на технических аспектах работы с хранилищем; они включают бизнес-термины и определения, которыми привык оперировать пользователь.
Фактически бизнес-метаданные представляют собой описание предметной области, для работы в которой создается аналитическая система или ХД. К формированию бизнес-метаданных должны активно привлекаться эксперты и аналитики, которые впоследствии и будут использовать систему для получения аналитических отчетов.
Бизнес-метаданные описывают объекты предметной области, информация о которых содержится в ХД, — атрибуты объектов и их возможные значения, соответствующие поля в таблицах и т.д. Бизнес-метаданные образуют так называемый семантический слой. Пользователь оперирует близкими ему терминами предметной области: товар, клиент, продажи, покупки и т.д., а семантический слой транслирует бизнес-термины в низкоуровневые запросы к данным в хранилище.
Способы использования ХД
С помощью аналитического приложения, используемого совместно с ХД, можно формировать запросы и получать по ним данные из хранилища. Данные могут визуализироваться непосредственно либо подвергаться обработке средствами аналитического приложения, тогда визуализируются результаты этой обработки.
Краткий обзор архитектур ХД
Разработка и построение корпоративного ХД — это дорогостоящая и трудоемкая задача. Успешность внедрения ХД во многом зависит от уровня информатизации бизнес-процессов в компании, установившихся информационных потоков, объема и структуры используемых данных, требований к скорости выполнения запросов и частоте обновления хранилища, характера решаемых аналитических задач и т.д. Чтобы приблизить ХД к условиям и специфике конкретной организации, в настоящее время разработано несколько архитектур хранилищ — реляционные, многомерные, гибридные и виртуальные.
Реляционные ХД используют классическую реляционную модель, характерную для оперативных регистрирующих OLTP-систем. Данные хранятся в реляционных таблицах, но образуют специальные структуры, эмулирующие многомерное представление данных. Такая технология обозначается аббревиатурой ROLAP — Relational OLAP.
Многомерные ХД реализуют многомерное представление данных на физическом уровне в виде многомерных кубов. Данная технология получила название MOLAP — Multidimensional OLAP.
Гибридные ХД сочетают в себе свойства как реляционной, так и многомерной модели данных. В гибридных ХД детализированные данные хранятся в реляционных таблицах, а агрегаты — в многомерных кубах. Такая технология построения ХД называется HOLAP — Hybrid OLAP.
Виртуальные ХД не являются хранилищами данных в привычном понимании. В таких системах работа ведется с отдельными источниками данных, но при этом эмулируется работа обычного ХД. Иначе говоря, данные не консолидируются физически, а собираются непосредственно в процессе выполнения запроса.
Кроме того, все ХД можно разделить на одноплатформенные и кросс-платформенные. Одноплатформенные ХД строятся на базе только одной СУБД, а кросс-платформенные могут строиться на базе нескольких СУБД.