Электронные средства сбора, обработки и отображения информации
Оглавление
Оптимальное кодирование
Большинство кодов, используемых при кодировании информации без учета статистических свойств источника и помех в канале связи, основано на системах счисления (двоичной, десятичной, восьмеричной, шестнадцатеричной).
Чем больше основание системы счисления, тем меньшее число разрядов требуется для представления данного числа, а следовательно, и меньшее время для его передачи. Однако с ростом основания усложняются устройства передачи и приема сигналов, так как логические элементы в этом случае должны иметь большее число устойчивых состояний. Если учитывать оба эти обстоятельства, то целесообразно выбрать систему, обеспечивающую минимум произведения основания кода т на количество разрядов п для выражения любого числа. Найдем этот минимум по графику для большого числа 60000 .
.

Из графика следует, что наиболее эффективной системой является троичная. Незначительно уступают ей двоичная и четверичная. Системы с основанием десять и более значительно хуже.
С точки зрения удобства физической реализации логических элементов и простоты выполнения в них арифметических и логических действий, предпочтение необходимо отдать двоичной системе.
Действительно, арифметические операции в двоичной системе достаточно просты:
Сложение по модулю в двоичной системе также просто:
0 0=0;
0=0;
0 1=1;
1=1;
1 1=0;
1=0;
1 0=1
0=1

Поскольку в восьмеричной системе числа выражаются короче, чем в двоичной, она широко используется как вспомогательная система при программировании (особенно для микро- и мини-ЭВМ в машинных кодах).
Чтобы сохранить преимущества двоичной системы, используют двоично-десятичные коды. В таком коде каждая цифра десятичного числа записывается в виде четырехразрядного двоичного числа. С помощью четырех разрядов можно образовать шестнадцать различных комбинаций, из которых любые десять могут составить двоично-десятичный код. Наиболее распространен код 8-4-2-1. Этот код относится к взвешенным кодам. Цифры в названии кода означают вес единиц в соответствующих двоичных разрядах. Он соответствует первым десяти комбинациям натурального двоичного кода (табл. 2.1).
Число в десятичном
Код 8-4-2-1 обычно используется как промежуточный при введении в вычислительную машину данных, представленных в десятичном коде.
Перевод чисел из десятичного в двоично-десятичный код осуществляется перфоратором в процессе переноса информации на перфоленту или перфокарту. Последующее преобразование в двоичный код осуществляется по специальной программе в самой машине. Двоично-десятичные коды с весами 5-1-2-1 и 2-4-2-1 используются при поразрядном уравновешивании в цифровых измерительных приборах (цифровые вольтметры и т.п.).
Недостатки взвешенных кодов: при передаче информации по каналам связи под действием помех отдельные элементы кода могут так исказиться, что будут приняты неверно. Например, вместо «0» будет принят элемент «1» или наоборот. Если будет искажен старший разряд, то ошибка будет значительно больше, чем при искажении младшего разряда. С этой точки зрения лучше применять невзвешенный код, у которого ошибки, вызванные помехами, были бы одинаковыми для любого разряда.
В невзвешенных кодах позициям (разрядам) кодовой комбинации не приписывают определенных весов. Вес имеет лишь вся кодовая комбинация в совокупности. Рассмотрим невзвешенный двоичный рефлексный код Грея (табл. 2.2).
Правило получения кода Грея: кодовую комбинацию натурального двоичного кода складывают по модулю 2 с такой же комбинацией, сдвинутой на один разряд вправо, при этом младший разряд сдвинутой комбинации отбрасывается.

Характерные особенности кода Грея:
1) каждая последующая комбинация всегда отличается от предыдущей только в одной позиции (в одном разряде);
2) смена значений элементов в каждом разряде (1 на 0 или 0 на 1) при переходе от комбинации к комбинации в коде Грея происходит вдвое реже, чем в натуральном двоичном коде. Это свойство кода Грея позволяет получить точность кодирования выше по сравнению с натуральным двоичным кодом при том же быстродействии схемы кодирования;
3) при сложении двух соседних комбинаций кода Грея по модулю 2 (mod 2) число единиц равно числу разрядов минус три (n-3). Это свойство кода Грея можно использовать для проверки правильности принятых комбинаций.
В коде Грея можно выделить оси симметрии (оси отражения), относительно которых наблюдается идентичность элементов в некоторых разрядах. Так, например, имеет место симметрия относительно оси, проведенной между числами 7 и 8 (идентичны три символа младших разрядов). Эта особенность и послужила основанием для введения термина «рефлексный», то есть отраженный код.
Рассмотренные свойства кода Грея показывают, что он удобен для аналого-цифрового преобразования различных непрерывных сообщений и их передачи по каналам связи (сервосистемы).
Недостатком кода Грея и других рефлексных кодов является то, что эти коды невзвешенные, их трудно обрабатывать с помощью ЭВМ, так как сложнее выполнять декодирование.
Преобразование кода Грея в натуральный двоичный код выполняется по правилу: старший разряд записывается без изменения, каждый следующий символ кода Грея нужно инвертировать, если в натуральном коде перед этим была получена «1», и оставить без изменения, если в натуральном коде был получен «0». (Пример:  ).
).
ЛЕКЦИЯ №4 ОПТИМАЛЬНОЕ И ЭФФЕКТИВНОЕ КОДИРОВАНИЕ
4.1 Понятие кодирования. Кодовое дерево.
В процессе кодирования каждая буква исходного алфавита представляется различными последовательностями, состоящими из кодовых букв или цифр.
Если исходный алфавит содержит m букв, то для построения равномерного кода с использованием D кодовых букв необходимо обеспечить выполнение следующего условия:
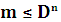 ,
,
где n- количество элементов кодовой последовательности.
Для построения равномерного кода достаточно пронумеровать буквы исходного алфавита и записать их в коды как n-разрядное число в D-ичной системе счисления.
Заметим, что поиск равномерного кода означает, что каждая буква исходного алфавита m кодируется кодовой последовательностью длинной n. Очевидно, что при различной вероятности появления букв исходного алфавита равномерный код является избыточным, так как энтропия, характеризующая информационную емкость сообщения максимальна при равновероятных буквах исходного текста:
 .
.
Пример. Для двоичного 5-рарядного кода букв русского алфавита информационная емкость составляет  5 бит,
5 бит, 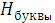 =4,35 бит.
=4,35 бит.
Устранение избыточности достигается применением неравномерных кодов, в которых буквы, имеющие наибольшие вероятности, кодируются короткими кодовыми последовательностями, а более длинные комбинации присваиваются редким, имеющим меньшую вероятность буквам.
Если i-ая буква, вероятность которой pi, получает кодовую комбинацию длины ni, то средняя длинна кода или средняя длина кодового слова равна:

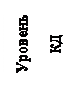   |
 |

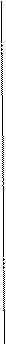


C1,C2,…,C11-кодовые слова. Уровень кодового дерева определяет длину кодового слова.
4.2 Теорема кодирования источников, неравенство Крафта.
Теорема Шеннона о кодировании источников устанавливает связь между средней длинной кодового слова и энтропией источника.
Для любого дискретного источника без памяти X с конечным алфавитом и энтропией H(X) существует D- ичный префиксный код, в котором средняя длинна кодового слова 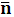 , удовлетворяет неравенству:
, удовлетворяет неравенству:
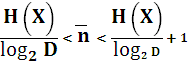
В префиксном коде никакое кодовое дерево не является префиксом другого кодового дерева. Это значит, что поток кодовых слов может использоваться без специального разделения этих слов. Например, если код 101 является кодом какой-то буквы, то в качестве кодов других букв нельзя использовать следующие комбинации: 1,10,10101, …и т.д.
Из теоремы Шеннона следует, что тем ближе длина кодового слова к энтропии источника, тем более эффективно кодирование. В идеальном случае, когда  , код называют эффективным. Эффективность кода оценивается величиной:
, код называют эффективным. Эффективность кода оценивается величиной:
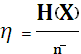 .
.
Если средняя длина 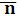 кодового слова является минимально возможной, то код еще и оптимальный. Теорема кодирования источников доказывается с использованием неравенства Крафта и формулируется следующим образом.
кодового слова является минимально возможной, то код еще и оптимальный. Теорема кодирования источников доказывается с использованием неравенства Крафта и формулируется следующим образом.
Для существования однозначно декодируемого D- ичного кода, содержащего k кодовых слов с длинами n1,n2,…,nk, необходимо и достаточно, чтобы выполнялось неравенство Крафта:
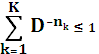
4.3 Методы оптимального кодирования. Сжатие данных.
Процедуру оптимального кодирования часто называют сжатием данных. Тогда задача сжатия данных есть минимизация технических затрат на хранение или передачу информации путем оптимального кодирования. На практике используют два вида сжатия данных:
2. Сжатие с потерями – устранение избыточности информации, которое приводит к безвозвратной потере некоторой доли информации, хотя это не принципиально для ее восстановления в интересах пользователя.
Сжатие без потерь наиболее применимо к числовым и текстовым данным. Применительно к вычислительной технике сжатие позволяет уменьшить количество бит информации, необходимого для хранения и передачи заданного объема этой информации, что дает возможность передавать сообщения более быстро или хранить более экономно. Такие программные средства, реализующие сжатие, называют архиваторами. Существует достаточно большое их разнообразие.
Методы сжатия данных были разработаны как математическая теория, которая до первой половины 80-х годов 20 века мало использовалась в компьютерной технике.
Методы или алгоритмы сжатия данных без потерь можно разделить на:
Они базируются на априорной статистике (вероятностях появления букв алфавита). Это главный недостаток таких кодов, так как априорная статистика кодов заранее не известна, а, следовательно, эффективному кодированию должен предстоять так называемый частотный анализ, т.е. анализ частоты появления символов в кодовой комбинации.
2.Адаптивные методы или алгоритмы. Например, модифицированные коды Хаффмана, арифметическое кодирование и др.
Здесь распределение вероятностей символов сначала считается равномерным на заданном интервале, а потом оно меняется по мере накопления статистики.
3.Динамические методы или алгоритмы. Они являются универсальными и не нуждаются в априорной статистике. Например, метод Лемпела- Зива.
Буквы исходного алфавита записываются в порядке убывания их вероятностей. Это множество разбивается так, чтобы вероятности двух подмножеств были примерно равны. Все буквы верхнего подмножества в качестве первого символа кода получают 1, а буквы нижнего подмножества-0. Затем последнее подмножество снова разбивается на два подмножества с соблюдением того же условия и проводят то же самое присвоение кодовым элементам второго символа. Процесс продолжается до тех пор, пока во всех подмножествах не останется по одной букве кодового алфавита.
| Буква xi | Вероятности pi | Кодовая последовательность | Длина кодового слова ni | pini | -pilog2pi |
| Номер разбиения | |||||
| x1 | 0,25 | 0,5 | 0,5 | ||
| x2 | 0,25 |  0 0 | 0,5 | 0,5 | |
| x3 | 0,15 |  0 0 | 0,45 | 0,4 | |
| x4 | 0,15 |  0 0 | 0,45 | 0,4 | |
| x5 | 0,05 |  0 0 | 1 | 0,2 | 0,2 |
| x6 | 0,05 | 0,2 | 0,2 | ||
| x7 | 0,05 | 0 | 0,2 | 0,2 | |
| x8 | 0,05 | 0 | 0,2 | 0,2 |
= 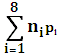 = (0,25*2+0,25*2+0,15*3+0,15*3+0,05*4+0,05*4+0,05*4+0,15*4)=2,7 бит
= (0,25*2+0,25*2+0,15*3+0,15*3+0,05*4+0,05*4+0,05*4+0,15*4)=2,7 бит
 =
=  1
1
4.3.2 Метод кодирования Хаффмана.
Этот метод всегда дает оптимальное кодирование в отличие от предыдущего, так как получаемая средняя длина кодового слова является минимальной.
Буквы алфавита сообщения располагают в порядке убывания вероятностей. Две последние буквы объединяют в один составной символ, которому приписывают суммарную вероятность. Далее заново переупорядочивают символы и снова объединяют пару с наименьшими вероятностями. Продолжают эту процедуру до тех пор, пока все значения не будут объединены. Это называется редукцией. Затем строится кодовое дерево из точки, соответствующей вероятности 1 (это корень дерева), причем ребрам с большей вероятностью присваивают 1,а с меньшей-0. Двигаясь по кодовому дереву от корня к оконечному узлу, можно записать кодовое слово для каждой буквы исходного алфавита.
| Буква xi | a | b | c | d | e | f |
| Вероятности pi | 0,05 | 0,15 | 0,05 | 0,4 | 0,2 | 0,15 |
| Кодовое слово | ||||||
| Длина кодового слова ni |








|

|








|
|






|
|
|
|
|
= 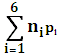 = (4*0,05 +3*0,15+4*0,05+0,4+3*0,2+3*0,15)= 2,3 бит
= (4*0,05 +3*0,15+4*0,05+0,4+3*0,2+3*0,15)= 2,3 бит
= 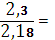 1,05
1,05
Из рассмотренного примера видно, что чем больше разница между вероятностями букв исходного алфавита, тем больше выигрыш кода Хаффмана по сравнению с простым блоковым кодированием.
Декодирование блока Хаффмана легко представить, используя кодовое дерево. Принятая кодовая комбинация анализируется посимвольно, в результате чего, начиная с корня дерева, мы попадаем в оконечный узел, соответствующий принятой букве исходного алфавита.
1.Различные длины кодовых слов приводят к неравномерным задержкам кодирования.
2.Сжатие снижает избыточность, что соответственно повышает предрасположенность к распространению ошибок, т.е. один ошибочно принятый бит может привести к тому, что все последующие символы будут декодироваться неверно.
3.Предполагаются априорные знания вероятности букв, которые на практике не известны, а их оценки часто бывают затруднительны.
4.3.3. Арифметическое кодирование.

Поэтому хотелось бы иметь такой алгоритм кодирования, который позволял бы кодировать символы менее чем 1 бит. Одним из таких алгоритмов является арифметическое кодирование, представленное в 70-х годах 20 века. При рассмотрении этого алгоритма будем исходить из того факта, что сумма вероятностей символов (и соответствующим им относительным частотам появления этих символов), всегда равна 1.Отсительные частоты появления могут определяться путем текущих статистических измерений исходного сообщения (это первый « проход» процедуры кодирования). Особенностью арифметического кодирования является то, что для отображения последовательности символов на интервале [0,1] используются относительные частоты их появления.
Пример определения частоты появления символов в сообщении
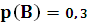

Результатом такого отображения является сжатие символов или посимвольное сжатие в соответствии с их вероятностями, т.е. результатом арифметического сжатия будет некоторая дробь из интервала [0,1], который представляется двоичной записью (это второй «проход» процедуры кодирования). Заметим, что такой двухпроходный алгоритм может быть реализован в ранее рассмотренных кодах Шеннона – Фано и Хаффмана.
Принципиальное отличие арифметического кодирования от предыдущих методов заключается в том, что кодированию подвергается сообщения целиком (весь набор символов или файл), а не символы по отдельности или их блоки.
Эффективность арифметического кодирования растет с увеличением длины сжимаемого сообщения. Заметим, что в кодах Шеннона – Фано и Хаффмана такого не происходит.
| Шаг кодирования | Поступающий символ | Интервал |
| нет | [ 0,1 ] | |
| a | [ 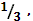 1] 1] | |
| b | [  ] ] | |
| a | 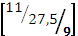 |
|
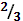
|







 1.
1.
 |
| |
|



 2.
2.
 | |||
|
|
1.  ,
,
2. 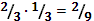 ,
,
3. 

|

|

|


 3.
3.
 | |||
|
|
1.  ,
,
2. 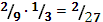 ,
,
3. 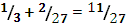
В таком алгоритме в конце сообщения должен стоять некий маркер, обозначающий конец сообщения.
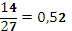
Код сообщения
Декодирование арифметического кода производится по его значению и тем же интервалам до восстановления исходного сообщения. На практике часто используют адаптивный арифметический алгоритм, когда на начальном этапе относительные частоты появления символов задаются некоторыми отрезками, либо принимаются равновероятными. А в процессе кодирования значение этих частот уточняются.
4.3.4 Алгоритм универсального кодирования методом Лемпела-Зива.
Этот алгоритм относится к классу универсальных потому, что он не требует априорных знаний о статистике символов. Такой метод носит менее математически обоснованный характер, но более практический.
Первый алгоритм разработан в 1971 году в Израиле Лемпелом и Зивом (LZ 77). Одной из причин популярности алгоритма LZ 77, а также семейства алгоритмов LZ 77, является их исключительная простота при высокой эффективности сжатия.
Пример. КРАСНАЯ КРАСКА
| Шаг кодирования | Словарь (8) | Буфер (5) | Код |
| …….. | КРАСН | ||
| …….К | РАСНА | ||
| ……КР | АСНАЯ | ||
| …..КРА | СНАЯ_ | ||
| ….КРАС | НАЯ _К | ||
| …КРАСН | АЯ_КР | ||
| .КРАСНАЯ | _КРАС | ||
| КРАСНАЯ_ | КРАСК | ||
| АЯ_КРАСК | А |
Для данного кода длину кодовой комбинации можно определить по следующей формуле:

 — операция округления в большую сторону.
— операция округления в большую сторону.
Такой алгоритм еще часто называют словарным. Очевидно, что сжатие будет иметь место, если длина полученной кодовой комбинации будет меньше кода того же сообщения при непосредственном кодировании. Для словарного кодирования учтено:
1.Часто повторяющиеся цепочки кодируются очень эффективно.
2.Редко повторяющиеся символы и их последовательности с течением времени удаляются из словаря.
3.Можно доказать, что словарное кодирование асимптотически оптимально, т.е. что длина кодового слова стремится к энтропии этого текста.
4.Практически достижимая степень сжатия для этих кодов 50-60 %.
В семейство алгоритмов LZ входит несколько моделей, которые модифицированы различными авторами в аспекте механизмов формирования кодовых групп, но во всех механизмах используется словарь. В настоящее время наибольшее распространение получил алгоритм LZW (1984 г.). В этом алгоритме длина кода уменьшается, так как не используется буфер. А кодирование проводится только по словарю, следовательно, кодовая группа определяется только длиной словаря.
Декодирование словарного кода происходит в обратном порядке и упрощается тем, что не требует поиска совпадений в словаре.
4.3.5 Особенности программ- архиваторов.
Если коды алгоритмов типа LZ передать для кодирования алгоритму Хаффмана или арифметическому алгоритму, то полученный двухшаговый алгоритм дает результат сжатия, подобный случайным программам-архиваторам, таким, как GZ, AGZ, PK zip. Наибольшую степень сжатия дают двухпроходные алгоритмы, которые последовательно сжимают два раза исходные данные, но они соответственно и работают в два раза медленнее. Большинство программ- архиваторов сжимают каждый файл по отдельности, хотя некоторые способны это делать в потоке файлов, что дает соответствующее увеличение степени сжатия, но и одновременно усложняет способы работы с полученным архивом. Например, замена в таком архиве файла на более новую версию может потребовать перекодирования всего архива. В общем потоке с файлами способен работать архиватор RAR, а в ОС Unix практически все архиваторы, такие как Gzip, Bzip2 и т.д.
| Расширение файла | Программа-архиватор | Тип кодирования |
| ark | arc, PKazc | LZW, Хаффана |
| zip | zip, PKzip, unzip, PKunzip | LZW, LZ77, Хаффмана, Шеннона – Фано |
| azj | azj | LZ77, Хаффмана |
| pak | pak | LZW |
| gif | графика | LZW |
| tif, tiff | факс | LZW |
4.3.6 Сжатие с потерями.
Сжатие с потерями используется в основном для трех видов данных:
Сжатие с потерями обычно происходит в два этапа:
1.Исходная информация с потерями приводится к виду, в котором ее можно эффективно сжимать алгоритмами второго этапа сжатия без потерь.
Основная идея сжатия графической информации с потерями состоит в следующем: каждая точка графической картинки характеризуется тремя равноценными атрибутами – яркость, цветность, насыщенность. Человек воспринимает их не как равные, т.е. полностью воспринимается информация о яркости, и гораздо меньшей степени о цветности и насыщенности, что позволяет отбрасывать часть информации о двух последних атрибутах без существенной потери качества изображения. Для сжатия графической информации с потерями в конце 80-х годов был установлен единый стандарт JPEG. В этом формате сложно регулировать степень сжатия, задавая степень потери качества.
Сжатие видеоинформации основано на том, при переходе от одного кадра к другому на экране обычно ничего не меняется, поэтому сжатая видеоинформация представляет собой запись некоторых базовых кадров и последовательности изменения в них, при этом часть информации естественно может отображаться. А сжатую таким образом информацию можно и дальше сжимать другими методами, но уже без потерь.
На сегодняшний день существует много форматов сжатия видеоинформации, но наиболее распространенным является MPEG. Этот стандарт был предложен в 1988 году и является практически единственным для спутникового телевидения и записи информации на DVD, CD и т.д.
Сжатие звуковой информации с потерями осуществляется на основе ограничении спектра звукового сигнала диапазоном реальной слышимости человека. Используют для этого различные стандарты сжатия звуковых файлов и достаточно часто MPEG без видеоданных.