Стильный Java, код, который работает всегда и везде, Фаэлла М., 2021
Стильный Java, код, который работает всегда и везде, Фаэлла М., 2021.
В современном мире разработки успешность приложения уже не определяется параметром «просто работает». Хороший программист должен знать возможности языка, практические приемы проектирования и платформенные средства для достижения максимальной производительности и жизнеспособности программ. Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.

Предисловие.
За прошедшие тридцать лет я написал немало книг по программированию, и неудивительно, что время от времени кто-нибудь обращается ко мне за советом о том, как это сделать. Я всегда прошу прислать образец главы. В большинстве случаев на этом все заканчивается, и меня это нисколько не огорчает. Ведь если кто-то не может написать даже главу, то дальше и обсуждать нечего. В январе 2018 года я получил сообщение от Марко Фаэллы — профессора Неапольского университета, с которым я уже встречался в Калифорнийском университете в Санта-Крус. Он попросил совета относительно проекта книги. Более того, он уже написал несколько глав! То, что я увидел, мне понравилось. Я похвалил работу автора и внес несколько предложений. На этом общение прервалось. Меня это не удивило. Один из редакторов сказал мне, что он знал великое множество людей, которые начинали писать книгу. и лишь немногих, кто ее дописал. В апреле 2019 года я получил новое сообщение — книга готовилась к печати в издательстве Manning и выглядела просто отлично. В августе Марко попросил меня написать предисловие, что я и делаю с огромным удовольствием.
Оглавление.
Предисловие.
Введение.
Благодарности.
О книге.
Об авторе.
Об обложке.
От издательства.
Часть I. Отправная точка.
Часть II. Свойства программного кода.
Приложения.
Скачать pdf
Ниже можно купить эту книгу по лучшей цене со скидкой с доставкой по всей России. Купить эту книгу
Стильный Java, код, который работает всегда и везде, Фаэлла М., 2021
Стильный Java, код, который работает всегда и везде, Фаэлла М., 2021.
В современном мире разработки успешность приложения уже не определяется параметром «просто работает». Хороший программист должен знать возможности языка, практические приемы проектирования и платформенные средства для достижения максимальной производительности и жизнеспособности программ. Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.

Предисловие.
За прошедшие тридцать лет я написал немало книг по программированию, и неудивительно, что время от времени кто-нибудь обращается ко мне за советом о том, как это сделать. Я всегда прошу прислать образец главы. В большинстве случаев на этом все заканчивается, и меня это нисколько не огорчает. Ведь если кто-то не может написать даже главу, то дальше и обсуждать нечего. В январе 2018 года я получил сообщение от Марко Фаэллы — профессора Неапольского университета, с которым я уже встречался в Калифорнийском университете в Санта-Крус. Он попросил совета относительно проекта книги. Более того, он уже написал несколько глав! То, что я увидел, мне понравилось. Я похвалил работу автора и внес несколько предложений. На этом общение прервалось. Меня это не удивило. Один из редакторов сказал мне, что он знал великое множество людей, которые начинали писать книгу. и лишь немногих, кто ее дописал. В апреле 2019 года я получил новое сообщение — книга готовилась к печати в издательстве Manning и выглядела просто отлично. В августе Марко попросил меня написать предисловие, что я и делаю с огромным удовольствием.
Оглавление.
Предисловие.
Введение.
Благодарности.
О книге.
Об авторе.
Об обложке.
От издательства.
Часть I. Отправная точка.
Часть II. Свойства программного кода.
Приложения.
Скачать pdf
Ниже можно купить эту книгу по лучшей цене со скидкой с доставкой по всей России. Купить эту книгу
Книга «Стильный Java. Код, который работает всегда и везде»
 Привет, Хаброжители! В современном мире разработки успешность приложения уже не определяется параметром «просто работает». Хороший программист должен знать возможности языка, практические приемы проектирования и платформенные средства для достижения максимальной производительности и жизнеспособности программ. Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.
Привет, Хаброжители! В современном мире разработки успешность приложения уже не определяется параметром «просто работает». Хороший программист должен знать возможности языка, практические приемы проектирования и платформенные средства для достижения максимальной производительности и жизнеспособности программ. Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.
Главная идея этой книги — показать мышление опытного разработчика с помощью сравнения свойств программного кода (или нефункциональных требований).
Схема на с. 12 связывает содержимое книги с широким спектром знаний, необходимых профессиональному разработчику. Изучение Java требует знакомства с классами, методами, полями и т.д. (здесь база не рассматривается). Далее освоение языка идет по трем путям:
В книге рассмотрены все эти области, но в несколько нетрадиционном виде. Вместо того чтобы освещать разные аспекты по отдельности, я смешал их в соответствии с потребностями определенной главы.
Каждая глава посвящена одному свойству программного кода, такому как скорость выполнения или удобочитаемость. Они не только важны и распространены, но и могут осмысленно применяться к малым кодовым единицам (например, к отдельному классу). Я постарался сосредоточиться на общих принципах и приемах программирования, а не на конкретных инструментах. В ряде случаев я ссылался на инструменты и библиотеки, которые помогут оценить и оптимизировать рассматриваемые свойства.
Ниже приведен краткий список глав и свойств кода, которые в них рассматриваются. Не пренебрегайте упражнениями в конце каждой главы. Они сопровождаются подробными решениями и завершают материал главы применением описанных методов в разных контекстах.
Глава 1. В первой главе описана задача программирования, которую мы будем решать (класс для представления резервуаров с водой). Здесь приведена наивная реализация, которая демонстрирует типичные заблуждения неопытных программистов.
Глава 2. Подробное описание эталонной реализации, обеспечивающей хороший баланс разных свойств.
Глава 3. Сосредоточившись на эффективности по времени, мы улучшим время выполнения эталонной реализации более чем на два порядка (в 500 раз) и увидим, что разные сценарии практического использования вынуждают нас идти на разные компромиссы.
Глава 4. Проведем эксперименты с эффективностью по затратам памяти и увидим, что по сравнению с эталонной реализацией затраты памяти сокращаются более чем на 50 % при использовании объектов и на 90 % — при отказе от использования отдельного объекта для каждого резервуара.
Глава 5. Постараемся достичь надежности за счет контрактного проектирования и усиления эталонного класса проверками во время выполнения, а также с помощью тестовых условий, основанных на контрактах методов и инвариантах классов.
Глава 6. Постараемся достичь надежности за счет модульного тестирования с помощью методов проектирования и выполнения набора тестов, а также рассмотрим метрики и средства тестового покрытия кода.
Глава 7. Произведем рефакторинг эталонной реализации для применения рекомендуемых методов создания чистого самодокументируемого кода.
Глава 8. В контексте конкурентности и потокобезопасности вспомним основные понятия синхронизации потоков и выясним, почему в нашем текущем примере необходимо применять нетривиальные механизмы для предотвращения взаимных блокировок и состояния гонки.
Глава 9. Рассмотрим возможность повторного использования: обобщим эталонный класс, чтобы он мог применяться в других приложениях с аналогичной общей структурой.
Приложение А. При обсуждении лаконичности кода я представлю компактную реализацию примера, объем исходного кода которого составит всего 15 % от эталонной версии. Конечно, получится заумный код, за который вас запинают на любом сеансе рецензирования кода.
Приложение Б. Наконец, мы соберем воедино все свойства и построим финальную версию класса, представляющего резервуары.
4.4. Черная дыра [Memory4]
Последняя реализация в этой главе — Memory4 — ухитряется использовать всего 4 байта для каждого дополнительного резервуара за счет более высокой временной сложности. Идея этой реализации состоит в использовании одного статического массива с одной ячейкой на каждый резервуар, выполняющей сразу две функции. Для некоторых индексов массив содержит индекс следующего резервуара той же группы, как если бы группы хранились в связанных списках. Для резервуаров, у которых нет следующего резервуара (они изолированы или завершают свой список), в массиве хранится объем воды этого резервуара (и каждого резервуара той же группы).
Я предлагаю хранить и индексы, и объемы воды в одном массиве. Первые — целые числа, вторые — вещественные. Какой тип должен иметь массив? В голову приходят два варианта, приводящие к одинаковым затратам памяти (4 байта на резервуар):
1. Массив типа int, в котором содержимое ячейки должно интерпретироваться как объем воды и его можно делить на постоянную величину (фактически реализация чисел с фиксированной точкой). Например, если все объемы будут делиться на 10 000, они будут определяться с 5 цифрами в дробной части.
2. Массив типа float, в котором, чтобы содержимое ячейки интерпретировалось как индекс, необходимо убедиться, что значение является неотрицательным целым числом. В конце концов, неотрицательные целые числа (до некоторого значения) являются частным случаем чисел с плавающей точкой.
В листинге 4.12 я выбрал второй вариант, который выглядит проще, хотя, как вы вскоре увидите, у него есть свои недостатки.
Листинг 4.12. Memory4: поле — конструктор не нужен
Есть небольшая проблема: в формате с плавающей точкой «положительный нуль» не отличается от «отрицательного». Эту неоднозначность можно устранить, считая, что нуль всегда обозначает объем, и никогда не использовать его в качестве индекса следующего резервуара. Чтобы не терять нулевую ячейку, увеличьте все индексы, хранящиеся в массиве, на 1 (смещение). Например, если за резервуаром 4 следует резервуар 7, nextOrAmount[4] == 8.
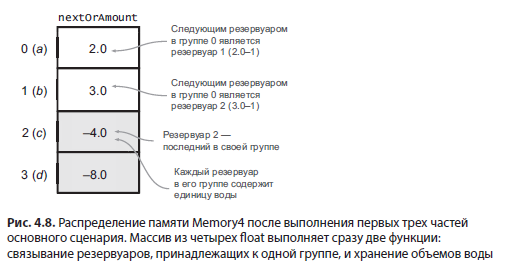
На рис. 4.8 представлено распределение памяти этой реализации после выполнения первых трех частей основного сценария. Значение 2,0 в первой ячейке — смещенный указатель на следующий резервуар — означает, что первый резервуар (a) связан с резервуаром под номером 1 (b). Значение –4,0 в третьей ячейке указывает, что c является последним резервуаром в своей группе, а каждый резервуар в этой группе содержит 4,0 единицы воды.

Например, из-за расширенного диапазона тип float способен точно представить число 1E10 (10^10 или 10 млрд), чего не позволяет сделать целочисленный тип. Оба типа могут представить значение 1E8 (100 млн), но если переменная float содержит 1E8, то при увеличении на 1 она останется равной 1E8. У чисел с плавающей точкой не хватает значащих цифр для представления числа 100 000 001.
Расстояние между 1E8 и следующим числом типа float превышает 1. Хотя число 1E8 входит в диапазон чисел float, оно не входит в непрерывный целочисленный диапазон float, то есть в диапазон целых чисел, которые могут быть представлены точно и без разрывов. В табл. 4.7 приведены непрерывные целочисленные диапазоны для большинства числовых примитивных типов.
Неожиданный вопрос 5
Выберите тип данных и исходное значение переменной x таким образом, чтобы цикл
while (x+1==x) <> выполнялся бесконечно.
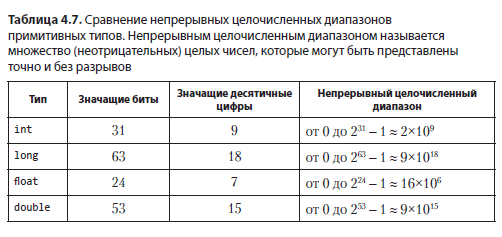
Использование float в качестве индекса массива — не лучшая идея. Оно сработает, только если индексы остаются в непрерывном целочисленном диапазоне, границы которого заметно меньше Integer.MAX_VALUE. Чтобы уточнить, насколько меньше, нужно учесть, что неотрицательные целые числа содержат 31 значащий бит, тогда как неотрицательные числа с плавающей точкой имеют только 24 значащих бита. Так как 31 – 24 = 7, порог для float в 2^7 = 128 раз меньше Integer.MAX_VALUE.
Если создать более 2^24 резервуаров, начнут происходить странные вещи и потребуется включить проверки времени выполнения в метод newContainer. Но эта глава посвящена потреблению памяти, поэтому будем придерживаться плана и оптимизировать только одно свойство кода за раз, а с факторами надежности подождем до главы 6. Остальной исходный код Memory4 можно найти в репозитории (https://bitbucket.org/mfaella/exercisesinstyle).
4.4.1. Временная сложность и затраты памяти
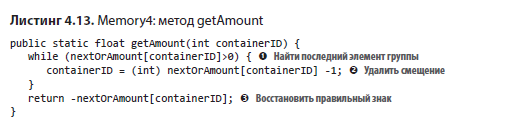
За крайнюю экономию памяти приходится платить замедлением выполнения, как видно из табл. 4.9. Методы connect и addWater должны вычислять размер группы по заданному индексу произвольного резервуара группы. Для этого приходится возвращаться к первому резервуару группы, а затем обходить весь виртуальный список резервуаров для определения длины. Найти первый резервуар в группе не так просто, ведь это единственный элемент группы, на который не ссылается другой указатель. Чтобы найти его, необходимо обойти список в обратном порядке, что требует квадратичного времени.
4.5. Баланс затрат памяти и времени
Начнем с краткой сводки требований по памяти для четырех версий резервуаров из этой главы и сравним их с реализацией Reference из главы 2.
Как видно из табл. 4.10, разумный выбор коллекций и способов кодирования позволяет добиться значительной экономии памяти. Чтобы выйти за рамки, представленные служебными затратами объектов, нам пришлось нарушить API из главы 1 и идентифицировать резервуары целыми числами вместо объектов резервуаров. Все реализации этой главы также жертвуют удобочитаемостью — и, как следствие, удобством сопровождения. Стремление к эффективности использования памяти ведет к использованию низкоуровневых типов (в основном массивов) вместо высокоуровневых коллекций и специальных кодировок, вплоть до применения значений float в качестве индексов массивов в Memory4. Во многих рабочих средах такие приемы считаются нежелательными, но им находится место в узкоспециализированных ситуациях с жесткими ограничениями по памяти, как в некоторых встроенных системах, или с необходимостью хранить огромные объемы данных в основной памяти.
Самыми сложными реализациями из двух глав являются те, которые максимизируют соответствующее свойство программного кода: Speed3 обеспечивает максимальную скорость выполнения, а Memory4 — максимальную эффективность использования памяти. Кроме того, при сокращении требований к памяти до 4 байт на резервуар в Memory4 временная сложность повышается до квадратичной. Этого следует ожидать — подобные компромиссы типичны при выборе баланса между временем и затратами памяти.
С другой стороны, Speed3 демонстрирует отличную эффективность: затраты памяти близки к Memory2 — минимуму, которого нам удалось добиться без отказа от стандартного API. Следовательно, в большинстве ситуаций при отсутствии жестких ограничений по памяти следует выбирать Speed3.
4.6. А теперь совсем другое
Пришло время применить методы экономии памяти в другом сценарии: работе с мультимножествами. Мультимножеством называется множество, которое может содержать дубликаты. Так, мультимножество
Спроектируем реализацию мультимножества MultiSet, которая эффективно расходует память и поддерживает следующие методы:
1. Предположим, вы вставляете n разных объектов c возможностью многократной вставки одного объекта и всего есть m вставок (то есть m по крайней мере не меньше n). Сколько байт потребуется для их хранения?
2. Какова временная сложность операций add и count в вашей реализации?
Как выясняется, существуют две реализации, оптимальные по затратам памяти, а выбор между ними зависит от предполагаемого количества дубликатов.
4.6.1. Малое количество дубликатов
Если предполагаемое количество дубликатов невелико, можно воспользоваться одним массивом для объектов и присоединять каждый вставляемый объект в конец массива — как для первого вхождения, так и для дубликатов.
Как упоминалось в этой главе, использование ArrayList вместо простого массива абсолютно оправданно, потому что коллекция занимает чуть больше памяти, но очень сильно упрощает реализацию. Более того, в отличие от массивов, ArrayList хорошо работает с обобщениями.
Реализация должна выглядеть примерно так:
С новой библиотекой потоков можно переписать метод count в однострочной реализации:
Метод add выполняется за постоянное (амортизированное) время (раздел 3.3.5), а count — за линейное время. Затраты памяти после m вставок n разных объектов составят 56 + 4 × m байт (не зависит от n):
4.6.2. Большое количество дубликатов
Если дубликаты встречаются часто, лучше использовать два массива: для хранения самих объектов и для хранения количества повторений каждого объекта. Если вы знакомы с библиотекой коллекций, то догадаетесь, что эта задача идеально подходит для Map. Однако обе стандартные реализации Map (HashMap и TreeMap) представляют собой связанные структуры и занимают намного больше памяти, чем две коллекции ArrayList.
В итоге у вас получится нечто такое:
Остаток реализации я оставлю вам для самостоятельной работы. Проследите, чтобы i-й элемент repetitions (который вы получаете от repetitions.get(i)) содержал количество повторений объекта elements.get(i).
Для ускорения выполнения вставка должна проверять первый массив и определять, что вставляется: новый объект или дубликат. В худшем случае оба метода add и count будут выполняться за линейное время.
Затраты памяти после m вставок n разных объектов составят 100 + 28 × n байт (не зависит от m):
4.7. Реальные сценарии использования
В главах 3 и 4 рассматривались два основных фактора, влияющих на эффективность алгоритма: время и затраты памяти. Было показано, что задача может быть решена разными способами (например, с использованием ArrayList вместо HashSet для хранения групп резервуаров). Выбор того или иного метода обычно приводит к компромиссу между эффективностью по времени и затратам памяти. Лучший выбор зависит от контекста решаемой задачи. Рассмотрим пару сценариев с высокой эффективностью по затратам памяти.
— Пакет android.util содержит несколько классов, предоставляющих альтернативы для стандартных коллекций Java с меньшими затратами памяти. Например, SparseArray — эффективная по памяти реализация карты (или ассоциативного массива), связывающей целочисленные ключи с объектами. (В упражнении 2 этой главы вам будет предложено проанализировать этот класс.)
— Все классы Android, относящиеся к работе с графикой, используют для представления координат, углов поворота и т. д. значения float с одинарной точностью вместо значений double. Пример можно найти в классе android. graphics.Camera.
Марко Фаэлла — преподаватель computer science в Неаполитанском университете имени Фридриха II (Италия). Помимо академических исследований в области computer science Марко увлеченно занимается преподаванием и программированием. Последние 13 лет он ведет курсы про-граммирования повышенной сложности, а также является автором учебника для желающих получить сертификат Java-разработчика и видеокурса по потокам в языке Java.
Для Хаброжителей скидка 25% по купону — Java
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Стильный Java, код, который работает всегда и везде, Фаэлла М., 2021
Стильный Java, код, который работает всегда и везде, Фаэлла М., 2021.
В современном мире разработки успешность приложения уже не определяется параметром «просто работает». Хороший программист должен знать возможности языка, практические приемы проектирования и платформенные средства для достижения максимальной производительности и жизнеспособности программ. Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.

Предисловие.
За прошедшие тридцать лет я написал немало книг по программированию, и неудивительно, что время от времени кто-нибудь обращается ко мне за советом о том, как это сделать. Я всегда прошу прислать образец главы. В большинстве случаев на этом все заканчивается, и меня это нисколько не огорчает. Ведь если кто-то не может написать даже главу, то дальше и обсуждать нечего. В январе 2018 года я получил сообщение от Марко Фаэллы — профессора Неапольского университета, с которым я уже встречался в Калифорнийском университете в Санта-Крус. Он попросил совета относительно проекта книги. Более того, он уже написал несколько глав! То, что я увидел, мне понравилось. Я похвалил работу автора и внес несколько предложений. На этом общение прервалось. Меня это не удивило. Один из редакторов сказал мне, что он знал великое множество людей, которые начинали писать книгу. и лишь немногих, кто ее дописал. В апреле 2019 года я получил новое сообщение — книга готовилась к печати в издательстве Manning и выглядела просто отлично. В августе Марко попросил меня написать предисловие, что я и делаю с огромным удовольствием.
Оглавление.
Предисловие.
Введение.
Благодарности.
О книге.
Об авторе.
Об обложке.
От издательства.
Часть I. Отправная точка.
Часть II. Свойства программного кода.
Приложения.
Скачать pdf
Ниже можно купить эту книгу по лучшей цене со скидкой с доставкой по всей России. Купить эту книгу
Книга «Стильный Java. Код, который работает всегда и везде»
 Привет, Хаброжители! В современном мире разработки успешность приложения уже не определяется параметром «просто работает». Хороший программист должен знать возможности языка, практические приемы проектирования и платформенные средства для достижения максимальной производительности и жизнеспособности программ. Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.
Привет, Хаброжители! В современном мире разработки успешность приложения уже не определяется параметром «просто работает». Хороший программист должен знать возможности языка, практические приемы проектирования и платформенные средства для достижения максимальной производительности и жизнеспособности программ. Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.
Главная идея этой книги — показать мышление опытного разработчика с помощью сравнения свойств программного кода (или нефункциональных требований).
Схема на с. 12 связывает содержимое книги с широким спектром знаний, необходимых профессиональному разработчику. Изучение Java требует знакомства с классами, методами, полями и т.д. (здесь база не рассматривается). Далее освоение языка идет по трем путям:
В книге рассмотрены все эти области, но в несколько нетрадиционном виде. Вместо того чтобы освещать разные аспекты по отдельности, я смешал их в соответствии с потребностями определенной главы.
Каждая глава посвящена одному свойству программного кода, такому как скорость выполнения или удобочитаемость. Они не только важны и распространены, но и могут осмысленно применяться к малым кодовым единицам (например, к отдельному классу). Я постарался сосредоточиться на общих принципах и приемах программирования, а не на конкретных инструментах. В ряде случаев я ссылался на инструменты и библиотеки, которые помогут оценить и оптимизировать рассматриваемые свойства.
Ниже приведен краткий список глав и свойств кода, которые в них рассматриваются. Не пренебрегайте упражнениями в конце каждой главы. Они сопровождаются подробными решениями и завершают материал главы применением описанных методов в разных контекстах.
Глава 1. В первой главе описана задача программирования, которую мы будем решать (класс для представления резервуаров с водой). Здесь приведена наивная реализация, которая демонстрирует типичные заблуждения неопытных программистов.
Глава 2. Подробное описание эталонной реализации, обеспечивающей хороший баланс разных свойств.
Глава 3. Сосредоточившись на эффективности по времени, мы улучшим время выполнения эталонной реализации более чем на два порядка (в 500 раз) и увидим, что разные сценарии практического использования вынуждают нас идти на разные компромиссы.
Глава 4. Проведем эксперименты с эффективностью по затратам памяти и увидим, что по сравнению с эталонной реализацией затраты памяти сокращаются более чем на 50 % при использовании объектов и на 90 % — при отказе от использования отдельного объекта для каждого резервуара.
Глава 5. Постараемся достичь надежности за счет контрактного проектирования и усиления эталонного класса проверками во время выполнения, а также с помощью тестовых условий, основанных на контрактах методов и инвариантах классов.
Глава 6. Постараемся достичь надежности за счет модульного тестирования с помощью методов проектирования и выполнения набора тестов, а также рассмотрим метрики и средства тестового покрытия кода.
Глава 7. Произведем рефакторинг эталонной реализации для применения рекомендуемых методов создания чистого самодокументируемого кода.
Глава 8. В контексте конкурентности и потокобезопасности вспомним основные понятия синхронизации потоков и выясним, почему в нашем текущем примере необходимо применять нетривиальные механизмы для предотвращения взаимных блокировок и состояния гонки.
Глава 9. Рассмотрим возможность повторного использования: обобщим эталонный класс, чтобы он мог применяться в других приложениях с аналогичной общей структурой.
Приложение А. При обсуждении лаконичности кода я представлю компактную реализацию примера, объем исходного кода которого составит всего 15 % от эталонной версии. Конечно, получится заумный код, за который вас запинают на любом сеансе рецензирования кода.
Приложение Б. Наконец, мы соберем воедино все свойства и построим финальную версию класса, представляющего резервуары.
4.4. Черная дыра [Memory4]
Последняя реализация в этой главе — Memory4 — ухитряется использовать всего 4 байта для каждого дополнительного резервуара за счет более высокой временной сложности. Идея этой реализации состоит в использовании одного статического массива с одной ячейкой на каждый резервуар, выполняющей сразу две функции. Для некоторых индексов массив содержит индекс следующего резервуара той же группы, как если бы группы хранились в связанных списках. Для резервуаров, у которых нет следующего резервуара (они изолированы или завершают свой список), в массиве хранится объем воды этого резервуара (и каждого резервуара той же группы).
Я предлагаю хранить и индексы, и объемы воды в одном массиве. Первые — целые числа, вторые — вещественные. Какой тип должен иметь массив? В голову приходят два варианта, приводящие к одинаковым затратам памяти (4 байта на резервуар):
1. Массив типа int, в котором содержимое ячейки должно интерпретироваться как объем воды и его можно делить на постоянную величину (фактически реализация чисел с фиксированной точкой). Например, если все объемы будут делиться на 10 000, они будут определяться с 5 цифрами в дробной части.
2. Массив типа float, в котором, чтобы содержимое ячейки интерпретировалось как индекс, необходимо убедиться, что значение является неотрицательным целым числом. В конце концов, неотрицательные целые числа (до некоторого значения) являются частным случаем чисел с плавающей точкой.
В листинге 4.12 я выбрал второй вариант, который выглядит проще, хотя, как вы вскоре увидите, у него есть свои недостатки.
Листинг 4.12. Memory4: поле — конструктор не нужен
Есть небольшая проблема: в формате с плавающей точкой «положительный нуль» не отличается от «отрицательного». Эту неоднозначность можно устранить, считая, что нуль всегда обозначает объем, и никогда не использовать его в качестве индекса следующего резервуара. Чтобы не терять нулевую ячейку, увеличьте все индексы, хранящиеся в массиве, на 1 (смещение). Например, если за резервуаром 4 следует резервуар 7, nextOrAmount[4] == 8.
На рис. 4.8 представлено распределение памяти этой реализации после выполнения первых трех частей основного сценария. Значение 2,0 в первой ячейке — смещенный указатель на следующий резервуар — означает, что первый резервуар (a) связан с резервуаром под номером 1 (b). Значение –4,0 в третьей ячейке указывает, что c является последним резервуаром в своей группе, а каждый резервуар в этой группе содержит 4,0 единицы воды.
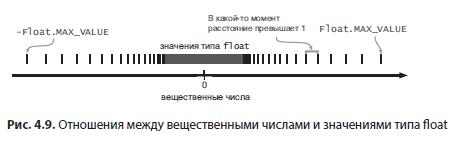
Например, из-за расширенного диапазона тип float способен точно представить число 1E10 (10^10 или 10 млрд), чего не позволяет сделать целочисленный тип. Оба типа могут представить значение 1E8 (100 млн), но если переменная float содержит 1E8, то при увеличении на 1 она останется равной 1E8. У чисел с плавающей точкой не хватает значащих цифр для представления числа 100 000 001.
Расстояние между 1E8 и следующим числом типа float превышает 1. Хотя число 1E8 входит в диапазон чисел float, оно не входит в непрерывный целочисленный диапазон float, то есть в диапазон целых чисел, которые могут быть представлены точно и без разрывов. В табл. 4.7 приведены непрерывные целочисленные диапазоны для большинства числовых примитивных типов.
Неожиданный вопрос 5
Выберите тип данных и исходное значение переменной x таким образом, чтобы цикл
while (x+1==x) <> выполнялся бесконечно.
Использование float в качестве индекса массива — не лучшая идея. Оно сработает, только если индексы остаются в непрерывном целочисленном диапазоне, границы которого заметно меньше Integer.MAX_VALUE. Чтобы уточнить, насколько меньше, нужно учесть, что неотрицательные целые числа содержат 31 значащий бит, тогда как неотрицательные числа с плавающей точкой имеют только 24 значащих бита. Так как 31 – 24 = 7, порог для float в 2^7 = 128 раз меньше Integer.MAX_VALUE.
Если создать более 2^24 резервуаров, начнут происходить странные вещи и потребуется включить проверки времени выполнения в метод newContainer. Но эта глава посвящена потреблению памяти, поэтому будем придерживаться плана и оптимизировать только одно свойство кода за раз, а с факторами надежности подождем до главы 6. Остальной исходный код Memory4 можно найти в репозитории (https://bitbucket.org/mfaella/exercisesinstyle).
4.4.1. Временная сложность и затраты памяти

За крайнюю экономию памяти приходится платить замедлением выполнения, как видно из табл. 4.9. Методы connect и addWater должны вычислять размер группы по заданному индексу произвольного резервуара группы. Для этого приходится возвращаться к первому резервуару группы, а затем обходить весь виртуальный список резервуаров для определения длины. Найти первый резервуар в группе не так просто, ведь это единственный элемент группы, на который не ссылается другой указатель. Чтобы найти его, необходимо обойти список в обратном порядке, что требует квадратичного времени.

4.5. Баланс затрат памяти и времени
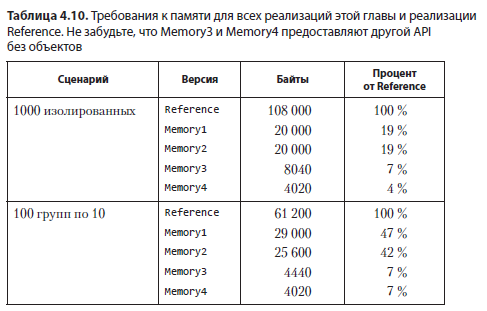
Начнем с краткой сводки требований по памяти для четырех версий резервуаров из этой главы и сравним их с реализацией Reference из главы 2.
Как видно из табл. 4.10, разумный выбор коллекций и способов кодирования позволяет добиться значительной экономии памяти. Чтобы выйти за рамки, представленные служебными затратами объектов, нам пришлось нарушить API из главы 1 и идентифицировать резервуары целыми числами вместо объектов резервуаров. Все реализации этой главы также жертвуют удобочитаемостью — и, как следствие, удобством сопровождения. Стремление к эффективности использования памяти ведет к использованию низкоуровневых типов (в основном массивов) вместо высокоуровневых коллекций и специальных кодировок, вплоть до применения значений float в качестве индексов массивов в Memory4. Во многих рабочих средах такие приемы считаются нежелательными, но им находится место в узкоспециализированных ситуациях с жесткими ограничениями по памяти, как в некоторых встроенных системах, или с необходимостью хранить огромные объемы данных в основной памяти.

Самыми сложными реализациями из двух глав являются те, которые максимизируют соответствующее свойство программного кода: Speed3 обеспечивает максимальную скорость выполнения, а Memory4 — максимальную эффективность использования памяти. Кроме того, при сокращении требований к памяти до 4 байт на резервуар в Memory4 временная сложность повышается до квадратичной. Этого следует ожидать — подобные компромиссы типичны при выборе баланса между временем и затратами памяти.
С другой стороны, Speed3 демонстрирует отличную эффективность: затраты памяти близки к Memory2 — минимуму, которого нам удалось добиться без отказа от стандартного API. Следовательно, в большинстве ситуаций при отсутствии жестких ограничений по памяти следует выбирать Speed3.
4.6. А теперь совсем другое
Пришло время применить методы экономии памяти в другом сценарии: работе с мультимножествами. Мультимножеством называется множество, которое может содержать дубликаты. Так, мультимножество
Спроектируем реализацию мультимножества MultiSet, которая эффективно расходует память и поддерживает следующие методы:
1. Предположим, вы вставляете n разных объектов c возможностью многократной вставки одного объекта и всего есть m вставок (то есть m по крайней мере не меньше n). Сколько байт потребуется для их хранения?
2. Какова временная сложность операций add и count в вашей реализации?
Как выясняется, существуют две реализации, оптимальные по затратам памяти, а выбор между ними зависит от предполагаемого количества дубликатов.
4.6.1. Малое количество дубликатов
Если предполагаемое количество дубликатов невелико, можно воспользоваться одним массивом для объектов и присоединять каждый вставляемый объект в конец массива — как для первого вхождения, так и для дубликатов.
Как упоминалось в этой главе, использование ArrayList вместо простого массива абсолютно оправданно, потому что коллекция занимает чуть больше памяти, но очень сильно упрощает реализацию. Более того, в отличие от массивов, ArrayList хорошо работает с обобщениями.
Реализация должна выглядеть примерно так:
С новой библиотекой потоков можно переписать метод count в однострочной реализации:
Метод add выполняется за постоянное (амортизированное) время (раздел 3.3.5), а count — за линейное время. Затраты памяти после m вставок n разных объектов составят 56 + 4 × m байт (не зависит от n):
4.6.2. Большое количество дубликатов
Если дубликаты встречаются часто, лучше использовать два массива: для хранения самих объектов и для хранения количества повторений каждого объекта. Если вы знакомы с библиотекой коллекций, то догадаетесь, что эта задача идеально подходит для Map. Однако обе стандартные реализации Map (HashMap и TreeMap) представляют собой связанные структуры и занимают намного больше памяти, чем две коллекции ArrayList.
В итоге у вас получится нечто такое:
Остаток реализации я оставлю вам для самостоятельной работы. Проследите, чтобы i-й элемент repetitions (который вы получаете от repetitions.get(i)) содержал количество повторений объекта elements.get(i).
Для ускорения выполнения вставка должна проверять первый массив и определять, что вставляется: новый объект или дубликат. В худшем случае оба метода add и count будут выполняться за линейное время.
Затраты памяти после m вставок n разных объектов составят 100 + 28 × n байт (не зависит от m):
4.7. Реальные сценарии использования
В главах 3 и 4 рассматривались два основных фактора, влияющих на эффективность алгоритма: время и затраты памяти. Было показано, что задача может быть решена разными способами (например, с использованием ArrayList вместо HashSet для хранения групп резервуаров). Выбор того или иного метода обычно приводит к компромиссу между эффективностью по времени и затратам памяти. Лучший выбор зависит от контекста решаемой задачи. Рассмотрим пару сценариев с высокой эффективностью по затратам памяти.
— Пакет android.util содержит несколько классов, предоставляющих альтернативы для стандартных коллекций Java с меньшими затратами памяти. Например, SparseArray — эффективная по памяти реализация карты (или ассоциативного массива), связывающей целочисленные ключи с объектами. (В упражнении 2 этой главы вам будет предложено проанализировать этот класс.)
— Все классы Android, относящиеся к работе с графикой, используют для представления координат, углов поворота и т. д. значения float с одинарной точностью вместо значений double. Пример можно найти в классе android. graphics.Camera.
Марко Фаэлла — преподаватель computer science в Неаполитанском университете имени Фридриха II (Италия). Помимо академических исследований в области computer science Марко увлеченно занимается преподаванием и программированием. Последние 13 лет он ведет курсы про-граммирования повышенной сложности, а также является автором учебника для желающих получить сертификат Java-разработчика и видеокурса по потокам в языке Java.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Java
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.