1 символ это сколько бит
Я просто смущен. сколько символов в одном бите?
Это зависит от характера и того, в каком кодировании он находится:
Символ ASCII в 8-разрядной кодировке ASCII составляет 8 бит (1 байт), хотя он может поместиться в 7 бит.
Символ ISO-8895-1 в кодировке ISO-8859-1 составляет 8 бит (1 байт).
Символ Unicode в кодировке UTF-8 находится между 8 битами (1 байт) и 32 битами (4 байта).
Символ Юникода в кодировке UTF-16 находится между 16 (2 байтами) и 32 битами (4 байта), хотя большинство общих символов принимают 16 бит. Это кодировка, используемая Windows внутренне.
Символ Unicode в кодировке UTF-32 всегда 32 бита (4 байта).
Символ ASCII в UTF-8 — 8 бит (1 байт), а в UTF-16 — 16 бит.
Дополнительные символы (не ASCII) в ISO-8895-1 (0xA0-0xFF) будут принимать 16 бит в UTF-8 и UTF-16.
Это означало бы, что между 0.03125 и 0.125 символами.
Один бит это 1/8 (одна восьмая или 0.125 символа). Из учебника информатики мы знаем что для того чтобы записать один символ нам нужен 1 байт, который состоит из 8 бит, отсюда 1 бит это 1/8 символа или 0.125 символа. Почему 1 символ это байт? Все дело в том что машина (компьютер) не понимает наши буквы и символы, она понимает только значения «верно» и «ложь» которые записаны в двоичном коде (то есть при помощи двух символов 1 и 0). Соответственно для того чтобы закодировать один из 256 символов при помощи нолей и единиц нам потребуется восемь мест в каждом из которых может быть только один из двух вариантов: единица или ноль. Таким местом как раз и является один бит который может содержать только ноль или единицу, а вот последовательность из восьми нолей или единиц можно описать один из 256 символов. Таким образом и получается что для записи одного символа нам нужно 8 бит или один байт.
Сравнивая UTF-8 и UTF-16, можно отметить, что наибольший выигрыш в компактности UTF-8 даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII. [4] [5]
Содержание
Алгоритм кодирования [ править | править код ]
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов (байтов), требуемых для кодирования символа. Номер символа берётся из стандарта Юникод.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
| 00000000-0000007F | 1 |
| 00000080-000007FF | 2 |
| 00000800-0000FFFF | 3 |
| 00010000-0010FFFF | 4 |
Для символов Юникода с номерами от U+0000 до U+007F (занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 102 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Примеры кодирования [ править | править код ]
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ | U+0024 | 100100 | 0 0100100 | 24 |
| ¢ | U+00A2 | 10 100010 | 110 00010 10 100010 | C2 A2 |
| € | U+20AC | 10 0000 10 101100 | 1110 0010 10 000010 10 101100 | E2 82 AC |
| �� | U+10348 | 1 0000 0011 01 001000 | 11110 000 10 010000 10 001101 10 001000 | F0 90 8D 88 |
Маркер UTF-8 [ править | править код ]
| 1-й байт | 2-й байт | 3-й байт | |
|---|---|---|---|
| Двоичный код | 1110 1111 | 1011 1011 | 1011 1111 |
| Шестнадцатеричный код | EF | BB | BF |
Пятый и шестой байты [ править | править код ]
Представление символов, таблицы кодировок
Содержание
Представление символов в вычислительных машинах [ править ]
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Таблицы кодировок [ править ]
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти [math]32[/math] символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение [math]256[/math] символов: [math]128[/math] основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) [math]256[/math] символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII [ править ]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа [math]n = 8[/math] бит. |
Кодировки стандарта ASCII ( [math]8[/math] бит):
Структурные свойства таблицы [ править ]
Кодировки стандарта UNICODE [ править ]
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей. Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство [ править ]
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до [math]2^<31>[/math] [math](2\ 147\ 483\ 648)[/math] кодовых позиций, было принято решение использовать лишь [math]1\ 112\ 064[/math] для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее [math]110\ 000[/math] кодовых позиций ( [math]109\ 242[/math] графических и [math]273[/math] прочих символов).
Кодовое пространство разбито на [math]17[/math] плоскостей (англ. planes) по [math]2^<16>[/math] [math](65\ 536)[/math] символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости [math]15[/math] и [math]16[/math] выделены для частного употребления.
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы [ править ]
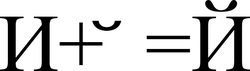
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления [ править ]
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8 [ править ]
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0x00000000 — 0x0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0x00000080 — 0x000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
| 0x00000800 — 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0x00010000 — 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
| 111111xx | служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования [ править ]
Правила записи кода одного символа в UTF-8 [ править ]
1. Если размер символа в кодировке UTF-8 = [math]1[/math] байт
Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 [math]\gt 1[/math] байт (то есть от [math]2[/math] до [math]6[/math] ):
2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления; 2.2 «0» — бит терминатор, означающий завершение кода размера 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
Определение длины кода в UTF-8 [ править ]
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
| [math]1[/math] | [math]7[/math] |
| [math]2[/math] | [math]11[/math] |
| [math]3[/math] | [math]16[/math] |
| [math]4[/math] | [math]21[/math] |
| [math]5[/math] | [math]26[/math] |
| [math]6[/math] | [math]31[/math] |
[math]C = 7[/math] при [math]n=1[/math]
[math]C = n\cdot5+1[/math] при [math]n\gt 1[/math]
UTF-16 [ править ]
UTF-16LE и UTF-16BE [ править ]
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32 [ править ]
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно [math]32[/math] бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Порядок байт [ править ]
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
[math]M = \sum_
Варианты записи [ править ]
Порядок от старшего к младшему [ править ]
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему [ править ]
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок [ править ]
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок [ править ]
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия [ править ]

Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт [ править ]
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
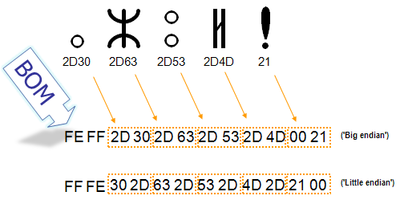
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) | FE FF |
| UTF-16 (LE) | FF FE |
| UTF-32 (BE) | 00 00 FE FF |
| UTF-32 (LE) | FF FE 00 00 |
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его [math]2[/math] или [math]4[/math] байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода [ править ]
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры [ править ]
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
Если вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку. Вот так, например:
01100010 01101001 01110100 01110011
b i t s
В этой кодировке, 01100010 представляет из себя ‘b’, 01101001 — ‘i’, 01110100 — ‘t’, 01110011 — ‘s’. Конкретная последовательность бит соответствует букве, а буква – конкретной последовательности битов. Если вы можете запомнить последовательности для 26 букв или умеете действительно быстро находить нужное соответствие, то вы сможете читать биты, как книги.
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие. В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский. И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все. Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂
characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Какого черта мой текст нечитаем?
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню. Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.