batch
Тематики
замес
Объём бетонной смеси, получаемый из барабана бетоносмесителя за один цикл перемешивания
[ Терминологический словарь по строительству на 12 языках (ВНИИИС Госстроя СССР) ]
Тематики
Тематики
система рецептурного управления технологическим процессом
—
[Интент]
Вообще, batch-процесс – это вид технологического процесса, который иногда противопоставляют непрерывному процессу. Иногда batch-процессы называют рецептурными процессами (или просто рецептами); эту терминологию мы и будем в дальнейшем использовать. Слово “batch” еще можно перевести как “партия продукции”, и это тоже относится к затрагиваемой теме, так как в результате рецептурного процесса производится партия продукции. Ладно, хватит путаницы – теперь по делу.
Раньше мы рассматривали технологические процессы, которые идут непрерывно в течение 24 часов в день, 7 дней в неделю, 365 дней в году. Хотя, на самом деле, раз в году делают плановый останов на несколько дней для выполнения ремонтных и других работ, но это происходит строго в соответствии с планом, и этому предшествуют значительные подготовительные работы. В другое же время остановка производства – это “чрезвычайное” происшествие. При этом отдельно взятая технологическая установка принимает участие в производстве одного вида продукции, а сам процесс идет по фиксированной технологической цепочке с неизменными настройками (уставками). Короче, все скучно, однообразно и весьма предсказуемо.
А теперь представим гипотетический пищевой цех по производству сока. При этом цех может производить несколько видов сока: яблочный, вишневый и апельсиновый, т.е. 3 вида продукции. Пусть сок производится из концентрированного сока в специальной емкости с мешалкой, где он тщательно смешивается с водой, а потом пастеризуется и идет на розлив (пакетирование).
Набор технологических параметров для производства определенного вида продукции называется рецептом (recipe). В нашем примере для сока это может быть: соотношение вода/концентрат, длительность и температура смешивания; температура пастеризации + другие параметры. В общем случае, рецепт также может содержать последовательность технологических операций, которые для различных видов продукции могут быть, строго говоря, разными. Хотя на практике, как правило, рецепт не подразумевает различающиеся технологические операции, а содержит всего лишь массив технологических уставок для того или иного продукта.

Рис. 1. Иллюстрация рецептурного управления на примере производства различных видов сока
Это все напоминает процесс приготовления еды на кухне, где мы оттачиваем рецепты разных блюд, но при этом используем одни и те же орудия (кастрюли, ножи, разделочные доски, плиту и т.д.)
Теперь попробуем дать характеристику batch-процессу:
1. На выходе несколько видов продукции.
2. При производстве разных видов продукции задействуется одно и то же технологическое оборудование.
3. Имеется множество рецептов.
4. Производство по “партиям”, которое может быть относительно легко и без последствий остановлено после завершения партии, а потом возобновлено.
Автоматизированное управление batch-процессом называется рецептурным управлением (batch control, или recipe control). Этот вид управления несколько специфичен, и требует от системы управления некоторой смекалки. Конечно, можно использовать для задач рецептурного управления обычные программные блоки, подходящие для управления непрерывным процессом, НО на практике это приводит к огромным трудностям (=головной боли) при попытке все это реализовать, используя стандартные подходы программирования. Поэтому многие производители АСУ ТП разработали специализированные batch-модули, которые адаптированы именно под рецептурные процессы. Эти модули могут выполняться на уровне ПЛК или на выделенном сервере batch. Иногда эти сервера, к тому же, резервируются. Также batch-модули дополняются специализированной средой разработки batch-программ, что сильно облегчает жизнь инженера.
На рисунке ниже в качестве примера приведена конфигурация верхнего уровня АСУ ТП SIMATIC PCS 7, оснащенной выделенным сервером batch.

Рис. 2. Структурная схема АСУ ТП с выделенным сервером batch
Перечислим основные обязанности системы batch-управления:
1. Ну, собственно, самая главная задача – хранение/загрузка рецептов и их выполнение в режиме реального времени ( batch process management ).
2. Отслеживание, не занята ли технологическая установка выполнением другого рецепта. Если занята, то выделяется другая аналогичная установка для выполнения данного рецепта ( process unit allocation ).
3. Формирование отчетов об изготовление партии продукции в задаваемой пользователем форме. Причем, требуются отчеты с возможностью отслеживания истории (ретроспективы) “прогона” партии по технологической цепочке ( reporting and batch tracking ).
4. Расчет различных показателей эффективности производства, как, например: удельного времени простоя (в %), производительности (в л/c) технологической установки или полного времени изготовления партии продукции (в мин).
5. Планирование изготовления партий, что фактически подразумевает составление производственного расписания. Ну, это на самом деле ни одна система в полном объеме пока не реализует ( batch planning ).
И еще несколько слов.
Как правило, пакет batch состоит из двух частей – операторской (клиентской) и исполняемой. Клиентская часть устанавливается на АРМы и всего лишь обеспечивает удобный операторский интерфейс. Клиентская часть, как правило, органично вписывается в общую операторскую среду, и работа с ней идет непосредственно из мнемосхем.
Исполняемая часть – это костяк системы. Именно она ответственна за автоматизированное выполнение задач рецептурного управления, описанных выше. Исполняемая часть прогружается в специальные серверы batch или в обычные ПЛК в зависимости от архитектуры АСУ ТП.
И еще. Существует международный стандарт ISA-88, специфицирующий batch-процессы, определяющий модель и философию рецептурного управления, а также стандартизирующий соответствующую терминологию. Документ тяжеловесный, и посему прочитан полностью мной не был. Тем не менее, в следующей части я попытаюсь более детально описать рецептурные системы с привязкой именно к стандарту ISA-88.
GM-AVTOVAZ после каникул качества не теряет

Помимо профилактических работ, за время летних каникул на производстве Chevrolet Niva внедрены несколько решений по повышению эффективности и удобства для сотрудников завода.
Как сообщила пресс-служба завода GM-AVTOVAZ, в этом году скорость работы и объём нагрузки на конвейере не снижались, хотя обычно так называемая «ребалансировка» проводится именно в период каникул. Более того, в рамках «Программы рацпредложений сотрудников по улучшениям»
Более того, в рамках постоянно действующей «Программы рацпредложений сотрудников по улучшениям» введены новые решения по повышению эффективности работы сотрудников завода. После возобновления производства или значительных технологических нововведений проводится проверка качества для каждой партии произведенных автомобилей по процедуре Batch&Hold.
Также проводится так называемый «Аудит глазами клиентов». Иными словами, сказали в пресс-службе, снижающееся качество продукции после каникул или выплаты премий – это всего лишь миф.

В настоящее время цена на полноприводный внедорожник начинается от 519 000 рублей. Chevy Niva во всех комплектациях оснащается 83-сильным двигателем объёмом 1,7 литра, работающим в паре с пятиступенчатой механической коробкой передач.
Напомним, работы над новым поколением Chevrolet Niva пока приостановлены, однако есть и приятные новости.
Для комментирования вам необходимо авторизоваться
ГЛАВА 8. РЕЦЕПТУРНОЕ УПРАВЛЕНИЕ
Batch-процесс – это вид технологического процесса, который иногда противопоставляют непрерывному процессу. Иногда batch-процессы называют рецептурными процессами, эту терминологию мы и будем в дальнейшем использовать. Слово “batch” еще можно перевести как “партия продукции”, и это тоже относится к затрагиваемой теме, так как в результате рецептурного процесса производится партия продукции.
Раньше мы рассматривали технологические процессы, которые идут непрерывно в течение 24 часов в день, 7 дней в неделю, 365 дней в году. Хотя, на самом деле, раз в году делают плановый останов на несколько дней для выполнения ремонтных и других работ, но это происходит строго в соответствии с планом, и этому предшествуют подготовительные работы. В другое же время остановка производства – это “чрезвычайное” происшествие.
А теперь представим гипотетический пищевой цех по производству сока. При этом цех может производить несколько видов сока: яблочный, вишневый и апельсиновый, т.е. 3 вида продукции. Пусть сок производится из концентрированного сока в специальной емкости с мешалкой, где он тщательно смешивается с водой, а потом пастеризуется и идет на розлив (пакетирование).
Набор технологических параметров для производства определенного вида продукции называется рецептом (recipe). В нашем примере для сока это может быть: соотношение вода/концентрат, длительность и температура смешивания; температура пастеризации + другие параметры. В общем случае, рецепт также может содержать последовательность технологических операций, которые для различных видов продукции могут быть, строго говоря, разными. Хотя на практике, как правило, рецепт не подразумевает различающиеся технологические операции, а содержит всего лишь массив технологических уставок для того или иного продукта.
1. На выходе несколько видов продукции.
2. При производстве разных видов продукции задействуется одно и то же технологическое оборудование.
3. Имеется множество рецептов.
4. Производство по “партиям”, которое может быть относительно легко и без последствий остановлено после завершения партии, а потом возобновлено.
Автоматизированное управление batch-процессом называется рецептурным управлением (batch control, или recipe control). Этот вид управления несколько специфичен, и требует от системы управления некоторой смекалки. Конечно, можно использовать для задач рецептурного управления обычные программные блоки, подходящие для управления непрерывным процессом, НО на практике это приводит к огромным трудностям при попытке все это реализовать, используя стандартные подходы программирования. Поэтому многие производители АСУ ТП разработали специализированные batch-модули, которые адаптированы именно под рецептурные процессы. Эти модули могут выполняться на уровне ПЛК или на выделенном сервере batch. Иногда эти сервера, к тому же, резервируются. Также batch-модули дополняются специализированной средой разработки batch-программ, что сильно облегчает жизнь инженера.
Перечислим основные обязанности системы batch-управления:
1. Хранение/загрузка рецептов и их выполнение в режиме реального времени (batch process management).
2. Отслеживание, не занята ли технологическая установка выполнением другого рецепта., иначе выделяется другая аналогичная установка для выполнения данного рецепта (process unit allocation).
3. Формирование отчетов об изготовление партии с возможностью отслеживания истории (ретроспективы) “прогона” партии по технологической цепочке (reporting and batch tracking).
4. Расчет различных показателей эффективности производства, например: удельного времени простоя (в %), производительности (в шт/c) технологической установки или полного времени изготовления партии продукции (в мин).
5. Планирование изготовления партий, что фактически подразумевает составление производственного расписания. Ну, это на самом деле ни одна система в полном объеме пока не реализует (batch planning).
Как правило, пакет Вatch состоит из двух частей – операторской (клиентской) и исполняемой. Клиентская часть устанавливается на АРМы и всего лишь обеспечивает удобный операторский интерфейс. Работа с ней идет непосредственно из мнемосхем.
Исполняемая часть – это основа системы. Именно она ответственна за автоматизированное выполнение задач рецептурного управления. Исполняемая часть прогружается в специальные серверы Вatch или в обычные ПЛК в зависимости от архитектуры АСУ ТП.
Существует международный стандарт ISA-88, специфицирующий Вatch-процессы, определяющий модель и философию рецептурного управления, а также стандартизирующий соответствующую терминологию.
Дата добавления: 2016-11-28 ; просмотров: 1236 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Эпоха, батч, итерация — в чем различия?
Вам должны быть знакомы моменты, когда вы смотрите на код и удивляетесь: “Почему я использую в коде эти три параметра, в чем отличие между ними?”. И это неспроста, так как параметры выглядят очень похожими.
Чтобы выяснить разницу между этими параметрами, требуется понимание простых понятий, таких как градиентный спуск.
Градиентный спуск
Это ни что иное, как алгоритм итеративной оптимизации, используемый в машинном обучении для получения более точного результата (то есть поиск минимума кривой или многомерной поверхности).
Градиент показывает скорость убывания или возрастания функции.
Спуск говорит о том, что мы имеем дело с убыванием.
Алгоритм итеративный, процедура проводится несколько раз, чтобы добиться оптимального результата. При правильной реализации алгоритма, на каждом шаге результат получается лучше. Таким образом, итеративный характер градиентного спуска помогает плохо обученной модели оптимально подстроиться под данные.
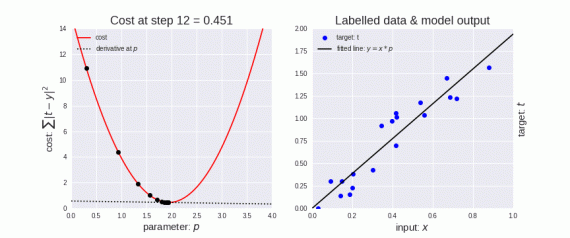
У градиентного спуска есть параметр, называемый скоростью обучения. На левой верхней картинке видно, что в самом начале шаги больше, то есть скорость обучения выше, а по мере приближения точек к краю кривой скорость обучения становится меньше благодаря уменьшению размера шагов. Кроме того, значение функции потерь (Cost function) уменьшается, или просто говорят, что потери уменьшаются. Часто люди называют функцию потерь Loss-функцией или просто «Лосс». Важно, что если Cost/Loss функция уменьшается, то это хорошо.
Как происходит обучение сети
Исследователи работают с гиганскими объемами данных, которые требуют соответствующих затрат ресурсов и времени. Чтобы эффективно работать с большими объемами данных, требуется использовать параметры (epoch, batch size, итерации), так как зачастую нет возможности загрузить сразу все данные в обработку.
Для преодоления этой проблемы, данные делят на части меньшего размера, загружают их по очереди и обновляют веса нейросети в конце каждого шага, подстраивая их под данные.
Epochs
Произошла одна эпоха (epoch) — весь датасет прошел через нейронную сеть в прямом и обратном направлении только один раз.
Так как одна epoch слишком велика для компьютера, датасет делят на маленькие партии (batches).
Почему мы используем более одной эпохи
Вначале не понятно, почему недостаточно одного полного прохода датасета через нейронную сеть, и почему необходимо пускать полный датасет по сети несколько раз.
Нужно помнить, что мы используем ограниченный датасет, чтобы оптимизировать обучение и подстроить кривую под данные. Делается это с помощью градиентного спуска — итеративного процесса. Поэтому обновления весов после одного прохождения недостаточно.
Одна эпоха приводит к недообучению, а избыток эпох — к переобучению:
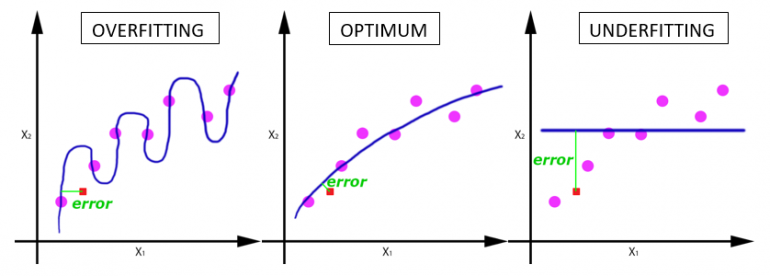
С увеличением числа эпох, веса нейронной сети изменяются все большее количество раз. Кривая с каждый разом лучше подстраивается под данные, переходя последовательно из плохо обученного состояния (последний график) в оптимальное (центральный график). Если вовремя не остановиться, то может произойти переобучение (первый график) — когда кривая очень точно подстроилась под точки, а обобщающая способность исчезла.
Какое количество эпох правильное?
На этот вопрос нет единственного точного ответа. Для различных датасетов оптимальное количество эпох будет отличаться. Но ясно, что количество эпох связано с разнообразием в данных. Например, в вашем датасете присутствуют только черные котики? Или это более разнообразный датасет?
Batch Size
Общее число тренировочных объектов, представленных в одном батче.
Отметим: Размер батча и число батчей — два разных параметра.
Что такое батч?
Нельзя пропустить через нейронную сеть разом весь датасет. Поэтому делим данные на пакеты, сеты или партии, так же, как большая статья делится на много разделов — введение, градиентный спуск, эпохи, Batch size и итерации. Такое разбиение позволяет легче прочитать и понять статью.
Итерации
Итерации — число батчей, необходимых для завершения одной эпохи.
Отметим: Число батчей равно числу итераций для одной эпохи.
Например, собираемся использовать 2000 тренировочных объектов.
Можно разделить полный датасет из 2000 объектов на батчи размером 500 объектов. Таким образом, для завершения одной эпохи потребуется 4 итерации.
Пакетная обработка в JDBC и HIBERNATE
В этой статье, я кратко расскажу о пакетной обработке SQL (DML) операторов: INSERT, UPDATE, DELETE, как одной из возможностей достижения увеличения производительности.

Преимущества
В отличие от последовательного выполнения каждого SQL запроса, пакетная обработка даёт возможность отправить целый набор запросов (пакет) за один вызов, тем самым уменьшая количество требуемых сетевых подключений и позволяя БД выполнять какое-то количество запросов параллельно, что может значительно увеличить скорость выполнения. Сразу оговорюсь, что заметный эффект можно увидеть при вставке, обновлении или удалении больших объёмов данных в таблицу БД.
Таблица БД
В качестве примера будет использована таблица book c полями id и title.
| id | title |
|---|---|
| 10001 | Java Persistence API и Hibernate |
| 10002 | Новая большая книга CSS |
| 10003 | Spring 5 для профессионалов |
| 10004 | Java ЭФФЕКТИВНОЕ ПРОГРАММИРОВАНИЕ |
1. JDBC — пакетная обработка
Прежде чем перейти к примерам реализации, необходимо осветить несколько важных моментов:
Далее, я приведу небольшие примеры использования интерфейсов Statement, PreparedStatement и CallableStatement в пакетной обработке. В примерах размер пакета указывается, как BATCH_SIZE. Значение размера пакета должно быть оптимальное, то есть не слишком большое, но и не слишком маленькое (например, 10-50).
В примерах, я ограничусь и буду использовать SQL оператор INSERT. Для UPDATE, DELETE всё аналогично.
1.1. Интерфейс Statement
Пример использования Statement для добавления данных пакетами в таблицу book.
Использование объекта Statement даёт возможность собирать в один пакет разные SQL операторы INSERT, UPDATE, DELETE.
Каждый SQL запрос проверяется и компилируется БД, что приводит к увеличению времени выполнения.
1.2. Интерфейс PreparedStatement
Пример использования PreparedStatement для добавления данных пакетами в таблицу book.
Шаги 3) и 4) такие же, как и для Statement, единственное отличие — это addBatch() без параметров.
SQL запрос компилируется и оптимизируется базой данных один раз, после чего его можно использовать многократно, задавая различные значения параметров. И это серьёзное преимущество, так как не затрачивается время на компиляцию каждого последующего запроса.
1.3. Интерфейс CallableStatement
Интерфейс CallableStatement используется для выполнения хранимых на сервере БД процедур.
Пакетная обработка предусматривает исполнение хранимых процедур при условии, что процедуры не содержат параметров OUT или INOUT.
Пример использования CallableStatement для добавления данных пакетами в таблицу book.
Не затрачивается время на компиляцию, так как хранимая процедура компилируется один раз при первом ее запуске, а затем сохраняется в скомпилированной форме на сервере БД.
Хранимые процедуры предоставляют возможность производить какие-либо вычисления перед тем как совершить манипуляцию с данными, выполнять сложную транзакционную логику.
Использование интерфейса CallableStatement не предусматривает возможности собирать в один пакет вызовы разных хранимых процедур, а только какой-то одной.
1.4. Класс BatchUpdateException
Небольшой демонстрационный пример:
Этот пример показывает лишь суть выше изложенного. В реальной же ситуации необходимо логировать сам запрос, который привёл к ошибке, так как сам по себе индекс малоинформативен, а для этого необходимо предусмотреть в обработчике сохранение пакета запросов перед их выполнением, чтоб в случае получения исключения уже по индексу определить запросы повлёкшие к нему. К сожалению объект BatchUpdateException не содержит методов получения SQL запросов, которые содержались в пакете и привели к исключению. Поэтому полная реализация механизма логирования и обработки ложиться на плечи разработчика.
2. Hibernate — пакетная обработка
2.1. Изменения в конфигурационном файле
2.2. Примеры реализации пакетной обработки
Прежде чем перейти к примерам реализации обратим внимание на некоторые аспекты связанные с контекстом хранения. Как известно, контекст хранения служит кэшем хранимых экземпляров. При попытке загрузить тысячи экземпляров сущностей, Hibernate сделает копию каждого экземпляра в кэше контекста хранения, что может привести к исчерпанию памяти OutOfMemoryException. Есть 2 варианта предотвращения полного расходования памяти:
2.3. Сбор статистики
Для того чтобы убедиться, что Hibernate действительно использует пакетную обработку, можно временно включить сбор статистики. Для этого необходимо в конфигурационном файле Hibernate.cfg.xml установить свойство «hibernate.generate_statistics» в true.
При пакетной вставке, удалении, обновлении статистика будет содержать информацию о затраченном времени и количестве выполненных пакетов.
Пример информации из статистики.
Вывод
Пакетное выполнение SQL запросов – это один из известных способов повышения производительности на который стоит обратить внимание. Уменьшение количества сетевых подключений к БД и увеличение скорости выполнения запросов является существенным плюсом в пользу использования пакетной обработки.