Как вернуть старый поиск Google в браузере Chrome
За последние годы поиск Google претерпел массу изменений. Компания доработала поисковые алгоритмы, повысив их эффективность, усовершенствовала интерфейс, сделав его более дружелюбным, и, конечно, довольно ощутимо преобразовала методику формирования поисковой выдачи. Это может быть незаметно на первый взгляд, но поисковик Google стал работать совершенно не так, как раньше, зачастую пропихивая в релевантной выдаче совершенно нерелевантные результаты, за продвижение которых компании просто-напросто заплатили. Рассказываю, как вернуть всё назад и не видеть назойливую рекламу.

Сейчас поиск Google сильно повязан на рекламе, а раньше он таким не был
Прежде, чем мы перейдём к инструкции по активации старой модели работы Google Search, предлагаю разобраться, что всё-таки изменилось и почему Google изменила методику формирования поисковой выдачи.
Теперь вы можете увидеть, помимо ссылок, карточки, маркированные списки и выдержки с геоточками на картах. Несмотря на то что далеко не все из них предоплачены (кое-что Google форсит сам по себе, потому что «любит» конкретные ресурсы за информировность), но очень часто попадаются геоточки магазинов и карточки сайтов, подключённых к рекламной сети AdWords.
Она принадлежит самой Google и, соответственно, продвигая популярные ресурсы с рекламой, получает больше денег. Из-за этого конкурирующие с компанией веб-сайты и сервисы в выдачу не попадают, как, например, наш канал в Яндекс.Дзен (обязательно подпишись). Просто Google считает Яндекс основным конкурентом и не видит нужды в том, чтобы продвигать его платформу. Расширение Simple Search устраняет эту подоплёку.
Как включить старый интерфейс Google
Поскольку расширение, активирующее старую поисковую модель, существует только в версии для Chrome и Firefox, то и пользоваться вам придётся именно этими браузерами. Я же объясню принцип его работы на примере Chrome:
Расширение Simple Search работает только в Chrome и Firefox
После установки расширения поверх оригинальной выдачи вы увидите большое окно с альтернативными результатами поиска, которые основаны на старых алгоритмах Google и которые Google реально бы предложил вам несколько лет назад, когда функция продвижения не была интегрирована настолько глубоко.
Это окно не перекрывает основную выдачу целиком, поэтому вы можете сравнивать её с тем, как в целом изменилась методика расположения сайтов, какие из них больше не демонстрируются в топе в принципе, а также какие элементы вроде глоточек и карточек теперь занимают пространство в окне выдачи.
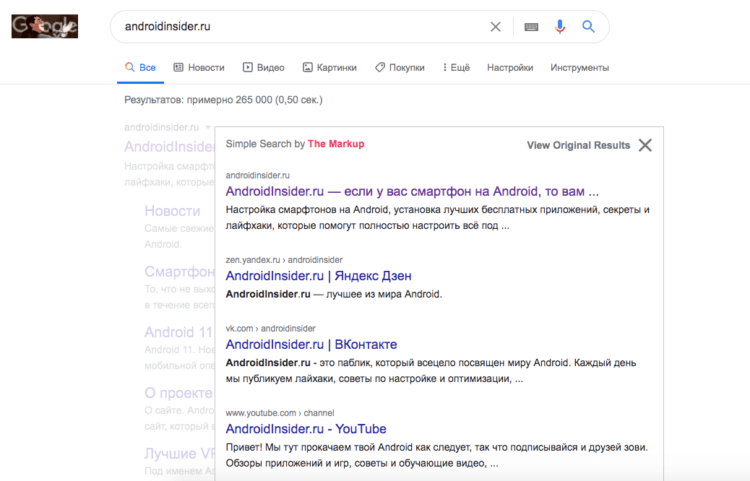
Сверху — старая выдача, под ней — новая
С одной стороны, интерфейс становится чище. Старый тип выдачи не демонстрирует больше подсайтов вроде форумов и специальных разделов основных веб-ресурсов, не говоря уже о карточках и разного рода вставках. Из-за этого на одну страницу помещается больше релевантных результатов поиска.
Чем старый Google лучше
Сравните сами. Если раньше по запросу «продукты» в Google вылезало 8-9 ссылок, то теперь только 3, потому что большую часть экрана занимает карточка с геоточками офлайновых магазинов.
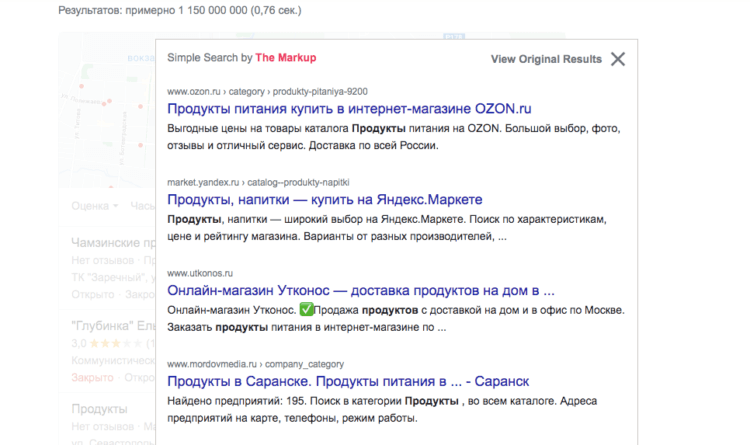
Результаты поиска в старой выдаче зачастую более релевантны
Не скажу, что стало совсем плохо. В конце концов, многие из нас предпочитают закупаться продуктами в гипермаркетах или супермаркетах, и точка на карте кажется полезным элементом поисковой выдачи. Но, во-первых, советует Google какие-то уж совсем местечковые магазины, в которые я точно не пойду, а не, скажем, Ленту или Магнит. А, во-вторых, раз уж поиск Google настолько умён, он мог бы сам понять, что, находясь у себя дома, я вряд ли нуждаюсь в подсказках такого рода.
На мой взгляд, было бы логичнее советовать магазины на карте только в том случае, если я нахожусь в другом городе. Поэтому в данном случае считаю старую поисковую выдачу более релевантной, чем новую.
Особенно круто, что Simple Search предлагает возможность напрямую сравнивать оба типа выдачи и определять, что подходит вам больше всего. Если старая выдача вас не устраивает, просто закрываете её и пользуетесь новой, ради которой Google даже не придётся перезагружать страницу. А если старая окажется для вас более предпочтительной, так тому и быть. Мне, по крайней мере, она показалась очень полезной.

Новости, статьи и анонсы публикаций
Свободное общение и обсуждение материалов



Расширенные сведения о принципах работы Поиска
При устранении неполадок и предварительном изучении действий, которые выполняют роботы Google Поиска на сайте, важно понимать, как эти роботы сканируют и индексируют ваш контент, а также показывают его в результатах поиска.
Сканирование
Сканирование – это процесс, в ходе которого робот Googlebot переходит на новые и обновленные страницы, чтобы добавить их в индекс Google.
Для этого мы используем огромное количество компьютеров, ведь робот обрабатывает миллиарды страниц. Программа, выполняющая сканирование, называется «робот Googlebot» (или «паук»). Робот Googlebot автоматически определяет, какие сайты следует сканировать, как часто это нужно делать, а также какое количество страниц следует выбрать на каждом из них.
При обработке сайта Googlebot в первую очередь анализирует список URL его страниц, который создан на основе предыдущих сеансов сканирования, и дополняет его информацией из файлов Sitemap, предоставленных веб-мастерами. Когда робот Googlebot переходит на страницу, он находит на ней ссылки и добавляет их в список сканируемых URL. Все новые и измененные сайты, а также неработающие ссылки помечаются, и впоследствии также учитываются в индексе Google.
В ходе сканирования робот Googlebot отрисовывает страницу при помощи актуальной версии браузера Chrome, а также запускает все скрипты, которые находит на ней. Если на вашем сайте используется динамически генерируемый контент, убедитесь, что вы следуете основным рекомендациям по поисковой оптимизации сайтов на JavaScript.
Основное и дополнительное сканирование
Google использует два разных типа поисковых роботов: для мобильных сайтов и для обычных. Соответственно, робот имитирует посещение страницы с мобильного устройства или с компьютера.
Один из этих двух типов роботов считается для вашего сайта основным. Все ваши страницы сканируются роботом основного типа. При сканировании всех новых веб-ресурсов в качестве основного используется поисковый робот для мобильных сайтов.
Google также сканирует некоторые страницы вашего сайта с помощью другого робота. Такое сканирование называется дополнительным и выполняется для того, чтобы понять, насколько сайт адаптирован к разным типам устройств.
Как Google определяет, какие страницы не нужно сканировать
Как повысить эффективность сканирования
Упростить роботу Googlebot поиск нужных страниц на вашем сайте можно перечисленными ниже способами.
Индексирование
Робот Googlebot обрабатывает все просканированные страницы и интерпретирует их контент, в том числе текст, основные теги и атрибуты (например, теги и атрибуты alt), изображения, видео и т. п. Робот Googlebot способен анализировать многие типы контента, но не все. К примеру, не распознается содержание некоторых мультимедийных файлов.
Между процедурами сканирования и индексирования робот Googlebot определяет, является ли обрабатываемая страница дубликатом или канонической версией другой страницы. Если страница считается дубликатом, она будет сканироваться значительно реже. Похожие страницы объединяются в документ, который состоит из канонической (основной) страницы и ее копий (могут иметься в виду альтернативные URL или версия той же страницы для другого типа устройств).
Обратите внимание, что Googlebot не индексирует страницы, на которые действует директива noindex (в теге или HTTP-заголовке). Но даже если робот Googlebot из-за запрета доступа в файле robots.txt, обязательной авторизации или по какой-либо другой причине не видит как саму страницу, так и директиву, страница все равно может быть проиндексирована.
Как повысить эффективность индексирования
Есть много способов упростить для Google анализ контента:
Определение понятия «документ»
В Google информация о просканированных сайтах представлена в виде огромного набора документов. Каждый документ соответствует одной веб-странице или нескольким сразу. Это одинаковые или очень похожие страницы с разными URL. Такие URL могут вести на одну и ту же страницу (например, example.com/dresses/summer/1234 и example.com?product=1234) или на почти идентичные страницы, предназначенные для пользователей разных устройств (предположим, example.com/mypage – версия для ПК, а m.example.com/mypage – для мобильных устройств).
Googlebot выбирает один из URL в документе в качестве канонического. Именно этот URL робот Googlebot сканирует и индексирует чаще других. Остальные URL в документе считаются копиями или альтернативными вариантами. Они могут иногда сканироваться и показываться в результатах поиска по обстоятельствам. Например, если каноническим является URL мобильной страницы, скорее всего, Google все же покажет пользователю компьютера версию для ПК (то есть альтернативную).
В большинстве отчетов Search Console данные агрегируются по каноническому URL документа. Есть инструменты (например, инструмент проверки URL), с помощью которых можно тестировать альтернативные URL. Однако информация о них должна появляться и при проверке канонического URL.
Даже если вы сами укажете канонический URL, Google по той или иной причине может выбрать в качестве канонической другую страницу.
Ниже приведен обобщенный список терминов с определениями, которые используются в Search Console.
Выдача результатов
Когда пользователь вводит запрос, наша система находит в индексе и показывает в результатах поиска самые подходящие страницы. При этом учитываются сотни различных факторов, и мы постоянно работаем над улучшением алгоритма. При ранжировании результатов имеет значение удобство просмотра, поэтому убедитесь, что ваш сайт быстро загружается и оптимизирован для мобильных устройств.
Как улучшить показ вашего контента в результатах поиска
Сделать так, чтобы контент с вашей страницы был лучше представлен в результатах поиска, можно несколькими способами.
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
42 оператора расширенного поиска Google (полный список)
Большинство операторов легко запомнить, это короткие команды. Но уметь эффективно их использовать — совсем другая история. Многие специалисты знают основы, но немногие по-настоящему овладели этими командами.
Операторы поиска Google: полный список
Вы знали, что Google постоянно удаляет полезные операторы? Именно поэтому большинство существующих списков устарели и неточны. Для этой статьи я лично проверил каждый оператор, что смог найти.
Вот полный список всех рабочих, частично рабочих и сломанных операторов расширенного поиска Google по состоянию на 2018 год.
Рабочие операторы
“поисковый запрос”
Принудительный поиск точного совпадения. Используйте его для уточнения неоднозначных результатов поиска или исключения синонимов при поиске отдельных слов.
Поиск по X или Y. Вернёт результаты, связанные с X или Y, или и то, и другое. Вместо него можно использовать оператор (|).
Поиск по X и Y. Вернёт только результаты, связанные как с X, так и с Y. Примечание: в реальности не имеет значения для обычного поиска, потому что Google по умолчанию вставляет AND. Но очень полезен в сочетании с другими операторами.
Исключение термина или фразы. В нашем примере все страницы будут упоминать Джобса, но не с Apple (компанией).
Действует как подстановочный знак для произвольного слова или фразы.
Группировка нескольких терминов или операторов, чтобы контролировать выдачу.
Поиск цен. Также работает для евро (€), но не для британского фунта (£).
define:
По сути, это встроенный в Google словарь. Показывает значение слова.
cache:
Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно).
filetype:
Ограничивает результаты файлами определённого формата, например, pdf, docx, txt, ppt и т. д. Примечание: аналогично оператору “ext:”.
Результаты для определённого домена.
related:
Поиск сайтов, связанных с данным доменом.
intitle:
Найти страницы с определённым словом (или словами) в заголовке страницы. В нашем примере возвратятся все результаты со словом [apple] в теге title.
allintitle:
Аналогично “intitle», но будут возвращает результаты, содержащие все указанные слова в теге title.
inurl:
Найти страницы с определённым словом (или словами) в URL. В этом примере будут возвращены все результаты, содержащие слово [apple] в URL.
allinurl:
Аналогично “inurl», но возвращает результаты со всеми указанными словами в URL.
intext:
Найти страницы, содержащие определённое слово (или слова) где-то в содержании. В примере будут возвращены все результаты, содержащие слово [apple] на странице.
allintext:
Аналогично “intext», но возвращает результаты со всеми указанными словами на странице.
AROUND(X)
Поиск поблизости. Страницы, содержащие два слова или фразы на расстоянии X слов друг от друга. В этом примере слова [apple] и [iphone] должны присутствовать в тексте на расстоянии не более четырёх слов друг от друга.
weather:
Найти погоду для конкретного места. Отображается в погодном сниппете, но также возвращает результаты с других метеорологических сайтов.
stocks:
Биржевая информация (т. е., цена и т. д.) для любой акции по биржевому тикеру.
Результаты поиска по картам.
movie:
Найти информацию о конкретном фильме. Также находит расписание сеансов, если фильм сейчас показывают недалеко от вас.
Преобразует одну единицы измерения в другую. Работает с валютами, весами, температурой, расстояниями и т. д.
source:
Найти новостные результаты из определённого источника в Google News.
Не совсем оператор поиска, но действует как подстановочный знак для автодополнения.
Пример: apple CEO _ jobs
Частично рабочие операторы
Вот операторы, которые не всегда дают желательный результат:
Поиск диапазона чисел. В приведённом примере возвращаются результаты [видео WWDC] за 2010-2014 годы, но не за 2015 год и последующие годы.
inanchor:
Поиск страниц, связанных с определённым текстом в ссылке. В этом примере будут возвращены все страницы, на которые есть ссылки со словами [apple] или [iphone].
allinanchor:
Аналогично inanchor, но возвращает результаты, содержащие все указанные слова во входящих ссылках.
blogurl:
Поиск URL блога в определённом домене. Использовался в поиске Google по блогам, но кое-как работает и в обычном поиске.
Примечание. Поиск Google по блогам закрыт в 2011 году.
loc:placename
Найти результаты из заданного места.
Примечание. Официально не закрыт, но результаты противоречивы.
location:
Найти результаты из заданного места в Google News.
Примечание. Официально не закрыт, но результаты противоречивы.
Сломанные операторы
Операторы поиска Google, которые удалены и больше не работают.
Принудительный поиск по одному слову или фразе.
Примечание. То же самое делается с помощью кавычек.
Включить синонимы. Не работает, потому что Google теперь включает синонимы по умолчанию. (Подсказка: для исключения синонимов используйте двойные кавычки).
inpostauthor:
Найти сообщения в блоге, написанные конкретным автором. Работало только в поиске по блогам.
Пример: inpostauthor:”steve jobs”
Примечание. Поиск Google по блогам закрыт в 2011 году.
allinpostauthor:
Аналогично предыдущему, но устраняет необходимость в кавычках (если вы хотите найти конкретного автора, включая фамилию).
Пример: allinpostauthor:steve jobs
inposttitle:
Найти сообщения в блоге с конкретными словами в названии. Больше не работает, так как этот оператор был уникальным для поиска по блогам.
Пример: inposttitle:apple iphone
Примечание. Хотя изначальная функциональность этого оператора устарела, он по-прежнему полезен для поиска канонической индексированной версии. Благодарю @glenngabe за информацию!
daterange:
Найти результаты по определённому диапазону дат. Почему-то использует юлианский формат даты.
Примечание. Официально не закрыт, но, похоже, не работает.
phonebook:
Поиск по хэштегу. Появился вместе с Google+, теперь устарел.
15 вариантов использования операторов поиска Google
Теперь рассмотрим несколько способов эффективного применения этих операторов, в том числе в сочетании друг с другом. Не стесняйтесь отклоняться от приведённых примеров, можете найти что-то новое.
1. Поиск ошибок индексации

Примечание. Google здесь даёт примерное количество. Точную информацию см. в Google Search Console.
Но сколько из них являются статьями в блоге?

Примерно четверть: около 249.
Я отлично знаю свой блог, поэтому уверен, что у меня статей реально меньше.
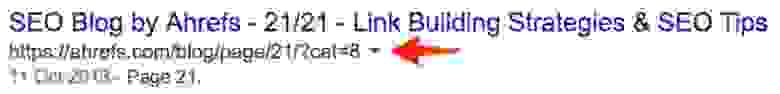
Кажется, проиндексировано несколько странных страниц.
(Это даже не реальная страница — она выдаёт 404)
Такие страницы следует удалить из индекса. Сузим поиск до поддоменов и посмотрим, что получится.

Примечание. Здесь мы используем подстановочный знак (*), чтобы найти все поддомены, принадлежащие домену, в сочетании с оператором исключения (-), чтобы исключить обычные результаты www.
Примерно 731 результат.
Вот страница на поддомене, которая определённо не должна индексироваться. Она сразу выдаёт 404.

Есть несколько других способов выявить ошибки индексации:
2. Поиск незащищённых страниц (не https)

О боже, около 2,47 млн незащищённых страниц.
Похоже, что Asos вообще не используют SSL — невероятно для такого большого сайта.

Примечание. Клиентам Asos волноваться не стоит — страницы оформления заказа безопасны.
Но вот ещё одна вещь: Asos доступен в версиях https и http.

Примечание. Иногда страницы индексируются без https, но после перехода по ссылке происходит редирект на версию https.
3. Поиск дубликатов контента
Дубликаты — это плохо. Вот пара джинсов Abercrombie & Fitch на сайте Asos со стандартным описанием:


Теперь интересно, является ли текст уникальным для Asos. Проверим.

Нет, он не уникален. Есть 15 других сайтов с точно таким же текстом, то есть дублированным контентом. Иногда дубли присутствуют на страницах с похожими товарами. Например, аналогичные продукты или тот же товар в упаковках с разным количеством. Вот пример на сайте Asos:
Как видим, за исключением количества, страницы одинаковые. Но дубликаты встречаются не только на сайтах электронной коммерции. Если у вас есть блог, то люди могут красть и публиковать ваш контент без надлежащей ссылки. Посмотрим, может кто-то украл и опубликовал наш список советов по SEO.

Около 17 результатов.
Большинство страниц, наверное, созданы в результате синдикации. Всё-таки стоит проверить, что они ссылаются на вас.
4. Поиск нежелательных файлов и страниц на своём сайте (о которых вы могли забыть)
Трудно уследить за всем на большом сайте, поэтому легко забыть о каких-то старых загруженных файлах: PDF, документы Word, презентации PowerPoint, текстовые файлы и т. д. Оператор filetype: поможет их найти.


Никогда раньше не видел этой статьи, а вы? Комбинируя несколько операторов, можно одновременно выводить результаты для разных типов файлов.
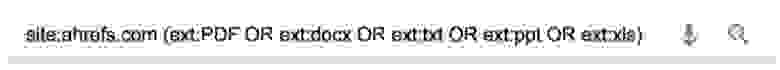
Важно удалить или деиндексировать их, чтобы они не попадались людям на глаза.
5. Поиск возможностей для гостевой публикации
Возможность публикации на других сайтах… есть много способов найти такие ресурсы:

Но вы уже знали об этом методе, верно!? 😉
Примечание. Этот метод находит страницы с предложением написать статью. Такие страницы создают многие сайты, которые ищут авторов.
Так что применим более творческий подход. Во-первых: не ограничивайтесь одной фразой. Также можете использовать такие поисковые запросы:

Примечание. На этот раз я использую оператор (“|”) вместо AND, он делает то же самое.
Можно даже искать эти фразу с учётом тематики.


Вот ещё один метод: если знаете конкретного блоггера в своей нише, попробуйте такой способ:

Так найдутся все сайты, где публиковался этот автор.
Примечание. Не забудьте исключить его сайт из выдачи, чтобы сохранить чистоту результатов!
Наконец, если вам интересно, принимает ли конкретный сайт статьи от сторонних авторов, попробуйте это:
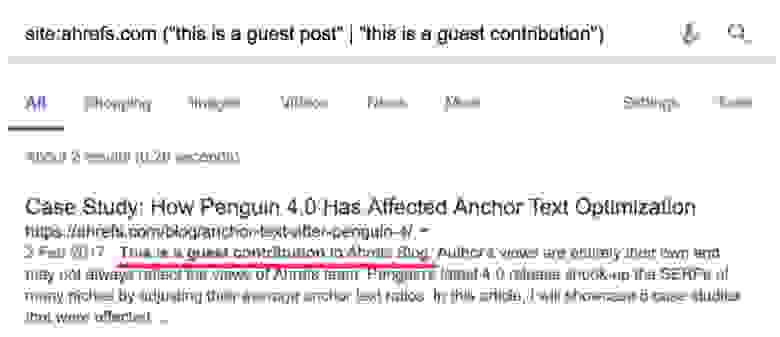
Примечание. В список можно добавить много других фраз.
6. Поиск страниц со списками ресурсов
Такие страницы собирают списки ресурсов по определённой теме.
Всё это — ссылки на сторонние ресурсы. По иронии, учитывая тему этой конкретной страницы — многие ссылки там не работают.
Так что если у вас есть крутой ресурс, можно найти соответствующие «ресурсные» страницы и подать заявку на добавление туда своей ссылки.
Вот один из способов найти их:
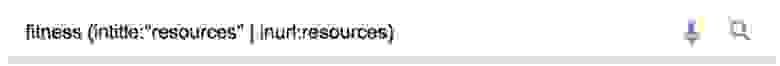
Но это может вернуть много мусора. Сужаем поиск:


Примечание. Здесь allintitle: гарантирует, что тег title содержит слова [fitness] и [resources], а также число от 5 до 15.
Примечание об операторе #..#
Странно, да? Дело в том, что этот оператор плохо сочетается с большинством других операторов. Да и вообще не всегда работает. Поэтому я рекомендую использовать последовательность чисел с оператором OR или вертикальной чертой (“|”). Это немного трудоёмкая процедура, зато работает.
7. Поиск сайтов с примерами инфографики… так что можно предложить свою
У инфографики плохая репутация. Скорее всего, потому что многие создают некачественную, дешёвую инфографику, которая не служит никакой реальной цели… кроме как «привлекать ссылки». Но не вся инфографика такая.
Кому вы можете предложить свою инфографику? Любым известным сайтам в своей нише?
Надо обратиться к сайтам, которые действительно захотят её опубликовать. Лучший способ — найти сайты, где уже публиковались такие материалы:

Примечание. Есть смысл поискать в пределах диапазона недавних дат, например, за последние три месяца. Если сайт публиковал инфографику два года назад, это не означает, что они таким занимаются до сих пор. Но если сайт публиковал её в последние несколько месяцев, то есть вероятность, что примет и вашу. Поскольку оператор daterange: больше не работает, придётся указать диапазон дат во встроенном фильтре поиска Google.
Но опять же, придётся отфильтровать мусор.

Нашлось два результата за последние три месяца. И более 450 результатов за всё время. Проведите такой поиск для нескольких конкретных иллюстраций — и получите хороший список.
8. Поиск сайтов для размещения своих ссылок… и проверки, насколько они подходят
Предположим, вы нашли сайт, где хотите разместить ссылку. Вручную проверили актуальность… всё выглядит хорошо. Вот как найти список похожих сайтов или страниц:

Получаем около 49 результатов, все похожие.
Примечание. В приведённом примере мы ищем сайты, похожие именно на блог Ahrefs, а не на весь сайт Ahrefs.
Я хорошо знаю Yoast, поэтому уверен, что это подходящий сайт для наших целей. Но предположим, что я ничего не знаю об этом сайте, Как проверить, что он подходит? Вот как:

0,84. Отличный результат.
Теперь проверим на сайтах, которые точно нам не подходят.
Количество результатов для поиска site:greatist.com:
Количество результатов для поиска site:greatist.com SEO:
0,0004 = совершенно нерелевантный сайт)
Важно! Это отличный способ быстро устранить крайне нерелевантные результаты, но он не всегда надёжно работает. Конечно же, это не замена ручной проверке потенциального кандидата: их всегда следует просматривать вручную, прежде чем обращаться с предложением. Иначе вы начнёте генерировать спам.
9. Поиск профилей в социальных сетях
Хотите с кем-то связаться? Попробуйте найти контактную информацию таким способом:

Примечание. Имя человека обычно легко найти, а вот контактную информацию сложно.
Четыре лучших результата:
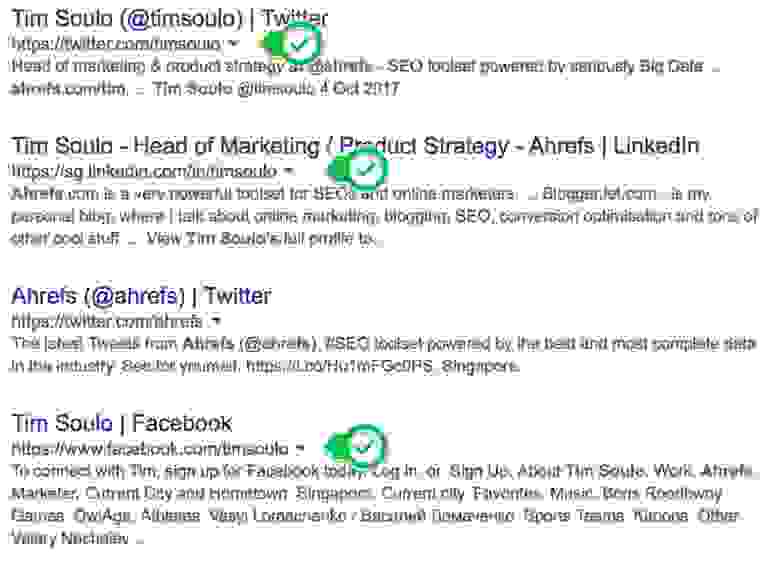
Затем можете связаться с человеком напрямую через социальные медиа. Или воспользуйтесь советами 4 и 6 из этой статьи для поиска адреса электронной почты.
10. Поиск возможностей для внутренних ссылок
Внутренние ссылки очень важны. Они помогают в навигации посетителей по вашему сайту, а также полезны для SEO (при разумном использовании). Но нужно убедиться, что вы добавляете внутренние ссылки только там, где это уместно. Допустим, вы только опубликовали большой список советов по SEO. Разве не здорово добавить внутреннюю ссылку на эту статью со всех страниц, где упоминаются советы по SEO?
Но не так легко найти соответствующие места для добавления этих ссылок, особенно на больших сайтах. Вот быстрый трюк:

Для тех, кто ещё не освоил операторы поиска, здесь мы делаем следующее:

Поиск занял три секунды.
11. Поиск упоминаний конкурентов для своего пиара
Вот страница, на которой упоминается наш конкурент — Moz.

Найдено с помощью такого расширенного поиска:

Но почему нет упоминания блогов Ahrefs? 🙁
С помощью site: и intext: я вижу, что этот сайт раньше упоминал нас пару раз.
Но они не разместили никакой статьи с обзором наших инструментов, как в случае с Moz. Это даёт возможность. Свяжитесь с ними, пообщайтесь. Возможно, они напишут также про Ahrefs.
Вот ещё один классный запрос, который можно использовать для поиска отзывов о конкурентах:

Примечание. Поскольку мы используем [allintitle], а не [intitle], то получим результаты со словом [review] и названием одного из конкурентов в теге заголовка.
Можете пообщаться с этими людьми, чтобы они повторно рассмотрели ваш товар/услугу.
Вот ещё один совет. Оператор daterange: устарел, но на странице поиска можно добавить фильтр для дат, чтобы найти последние упоминания конкурентов. Просто используйте этот встроенный фильтр.
Похоже, за последний месяц опубликовано 34 отзыва о наших конкурентах.
12. Поиск возможностей для спонсорских постов
Спонсорские посты — это платные статьи, продвигающие ваш бренд, продукт или услугу. Такой вариант не предназначен для размещения ссылок.
Покупка или продажа ссылок, которые передают PageRank. Это включает в себя передачу денег на ссылки или сообщения, содержащие ссылки; передачу товаров или услуг в обмен на ссылки; отправку кому-то «бесплатного» продукта в обмен на то, что они напишут о нём и поставят ссылку.
Вот почему вы всегда должны следить за ссылками в спонсорских статьях.
Но истинная ценность этих статей всё равно не сводится к ссылкам. Это пиар, то есть демонстрация свого бренда перед нужными людьми. Вот один из способов найти возможности для спонсорских публикаций с помощью операторов поиска Google:
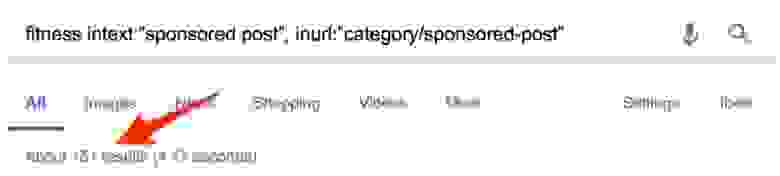
Примерно 151 результат. Неплохо.
Несколько других комбинаций операторов:
13. Поиск тем Q+A, связанных с вашим контентом
Форумы, а также сайты с вопросами и ответами отлично подходят для продвижения контента.
На ум приходит Quora, которая разрешает публиковать в своих ответах релевантные ссылки.

Ответ в Quora со ссылкой на SEO-блог
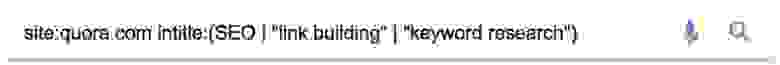
Это можно сделать на любом форуме или сайте с вопросами и ответами. Такой же поиск для Warrior Forum:


Такие операторы даже лучше находят темы на форуме, чем встроенный поиск на сайте.
14. Проверка, как часто конкуренты публикуют новый контент
Большинство блогов находятся в подпапке или поддомене, например:
Похоже, у них уже около 4500 статей. Но это не совсем так. Сюда входят версии блога на разных языках, которые находятся на поддоменах.

Это больше похоже на правду: около 2200 постов. Посмотрим, сколько опубликовано за последний месяц. Поскольку оператор daterange: больше не работает, используем встроенный фильтр Google.
Примечание. Можно указать любой диапазон дат. Просто выберите “Custom”.
Около 29 постов. Интересно. Это примерно вчетверо больше, чем у нас. И у них в целом примерно в 15 раз больше постов, чем у нас. Но мы всё равно получаем больше трафика… с двукратным превосходством по ценности.

Оператор site: в сочетании с поисковым запросом покажет, сколько статей конкурент опубликовал по определённой теме.
15. Поиск сайтов со ссылками на конкурентов
На конкурентов ставят ссылки? Может быть, мы тоже можем их получить? Google прекратил поддержку оператора link в 2017 году, но он по-прежнему возвращает некоторые результаты.
Примечание. Обязательно исключайте сайт конкурента, чтобы отфильтровать внутренние ссылки.
Около 900 тыс. ссылок. Здесь тоже пригодится фильтр по дате. Например, за последний месяц на Moz поставили 18 тыс. новых ссылок.
Очень полезная информация. Но эти данные тоже могут быть неточными.
Заключение
Я бы ещё добавил, что многие операторы бесполезны, если не применяются в сочетании с другим оператором… или двумя-тремя. Так что поиграйте с ними и напишите, как ещё их можно использовать. Я с радостью добавлю в статью любые полезные комбинации, какие вы найдёте.